Modelling cognitive aspects of complex control tasks: one possible view of the structure of the thesis
| My home page | Copyright ©1990, 1995, 2022 | my publications |
|---|
University of Strathclyde Department of Computer Science
Modelling Cognitive Aspects
of Complex Control Tasks
A. Simon Grant
Ph. D.
1990
This separate document includes links to each heading and subheading here.
This thesis grew out of an environment including the Scottish HCI Centre, with a psychologist as supervisor, and the machine learning expertise of the Turing Institute. It is a work of cognitive science, strongly flavoured with cognitive ergonomics for complex tasks and human factors in process control. It attempts to understand human representation of complex tasks, and finds a key in the idea that the cognitive context of an action is related to the information accessed. This is shown by using rule-induction as a measure of the degree to which the actions are determined by the information observed by the human. It is a many-threaded, forward-looking work, which does not fit neatly into any standard research framework, but rather offers to help open up new ones. It is particularly recommended for cognitive scientists and related researchers open to or looking for new paradigms.
The copyright of this thesis belongs to the author under the terms of the United Kingdom Copyright Acts as qualified by the University of Strathclyde Regulation 3.49. Due acknowledgement must always be made of the use of any material contained in, or derived from, this thesis.
HTML version copyright 1995, 2022
Dedicated to Magdalene, Chloe and Finn: because if I had been with them, as I wished, and they deserved, this thesis would not have been studied or written. Whatever its quality, it is a poor substitute.
At that time, Jesus spoke these words: ‘I thank thee, Father, Lord of heaven and earth, for hiding these things from the learned and wise, and revealing them to the simple … ’
— The Gospel according to Matthew, ch. 11
There is, it seems to us,
At best, only a limited value
In the knowledge derived from experience.
The knowledge imposes a pattern, and falsifies,
For the pattern is new in every moment
And every moment is a new and shocking
Valuation of all we have been.
— T. S. Eliot, Four Quartets, East Coker (here)
… at this sound, the crowd gathered, all bewildered because each one heard his own language being spoken. They were amazed, and in their astonishment exclaimed, ‘Why, they are all Galileans, are they not, these men who are speaking? How is it then that we hear them, each of us in his own native language? Parthians, Medes, Elamites; inhabitants of Mesopotamia, of Judaea and Cappadocia, of Pontus and Asia, of Phrygia and Pamphilia, of Egypt and the districts of Libya around Cyrene; visitors from Rome, both Jews and proselytes, Cretans and Arabs, we hear them telling in our own tongues the great things God has done.’ And they were all amazed and perplexed, saying to one another, ‘What can this mean?’ Others said contemptuously, ‘They have been drinking!’
— The Acts of the Apostles, ch. 2
Jesus answered, ‘ … My task is to bear witness to the truth. For this I was born; for this I came into the world, and all who are not deaf to truth listen to my voice.’ Pilate said, ‘What is truth?’
— The Gospel according to John, ch. 18
We shall not cease from exploration
And the end of all our exploring
Will be to arrive where we started
And know the place for the first time
— T. S. Eliot, Four Quartets, Little Gidding (here)
For now we see through a glass, darkly; but then face to face: now I know in part; but then shall I know even as also I am known.
— 1 Corinthians 13.12
I would like to acknowledge the help of many people during my study. At YARD: Peter Mason, for helping to supervise me, providing resources and subjects, and offering direction and penetrating criticism; Brian Sherwood-Jones, for passing me many leads, discussing human factors points, and helping to set up the project in the first place; Martin Stafford, for piloting me in nautical ways; Douglas Blane and David Barrie, for providing vital information about the simulations; and Bob Leiser, Sue Mellows and numerous others for particular help, advice or discussion.
At the Turing Institute: Michael Bain, for helping me get started on C, and bicycle simulation, as well as numerous helpful discussions; Robin Boswell, for fixing my problems with his rule-induction programs, and implementing many of my suggestions; Eddie Grant, for useful feedback; Professor Donald Michie, for supervising some of my work; and all the members of the Machine Learning Group, particularly Peter Clark, Stephen Muggleton and Jonathan Shapiro, for contributing interest and help on many occasions.
At the Scottish HCI Centre: Terry Mayes (now at Heriot-Watt University), for supervising me in a concerned way, despite the little time he had available; George Weir, for giving me many pointers, particularly in the area of HCI and complex systems literature; Christina Knussen, for commenting and making connections on and off the subject, and many others, particularly Marius Bergan, both for discussion and the routine mutual aid that is almost indispensable in environments centred round computers.
Thanks are due also to several researchers and staff at other organisations that I visited in the initial stages of the study: David Lewis and others, of Glasgow College of Nautical Studies; Captain John Habberley and others, of The College of Maritime Studies, Warsash (Southampton Institute of Higher Education); Frans Coenen and others, of Liverpool Polytechnic Department of Maritime Studies; and Grahame Blackwell and others, of Plymouth Polytechnic (now Polytechnic South West) Ship Control Group.
I have also benefited from many discussions with members of the wider HCI academic community. I would particularly like to thank Paul Booth for detailed discussion and encouragement in the area of mental modelling techniques. Thanks also to Jon Mortimer and others at Bristol Polytechnic, where I had a chance to develop some of my ideas before this study commenced.
And I would like to thank the subjects who provided me with the experimental data that I regard as so important.
The study was funded, under a “CASE” studentship, by the Science and Engineering Research Council, and YARD Ltd., Glasgow.
Disasters in man-made systems (ships, aircraft, power plant, etc.) often point to a lack of ideal provision of information to the operators. To give good operator support, in remedy, we need to understand more about human cognition in such complex tasks, beyond what can be firmly deduced from verbal reports. The recent tradition of modelling by formalisms (such as GOMS, TAG) is applicable to tasks that are logically definable, but lacks the empirical input for effective modelling of complex tasks. When there is a clearly appropriate representation of situations and actions, machine learning can effectively derive rules that model behaviour, but for complex control tasks we have no satisfactory idea of the human representations of complex tasks.
Human control of a specially constructed bicycle-like simulation was studied, and showed the added difficulties of attempting to model a task in which psycho-motor factors are significant. A semi-complex, non-manual simulation task (mine-hunting) was devised and implemented as a scored game, in order further to study human representations and rules. Data from several subjects were collected and analysed with the help of a rule-induction program (CN2). The first experiment showed that representation content was important to the quality of rules derived by induction, and that a simple analysis of the frequency of common consecutive actions helped towards constructing compound actions that were more human-like. In the second experiment, information was priced to motivate subjects to turn off unnecessary information and so reveal the information they used. This revealed a context structure that was useful and informative in the preparation and separation of data for rule-induction. Following the experimental reports, extending and generalising these methods is discussed, considering prospects for their use in HCI design, and outlining a ‘guardian angel’ paradigm for operator or user support.
This inter-disciplinary thesis is broadly concerned with how to investigate and model the cognition behind people's performance of tasks that deal with complex dynamic, or real-time, systems.
The remainder of Chapter 1 (Introduction and study context) introduces the background to this study, details the aspects that are explored in the study, and gives a view of the logical structure of the thesis. The issues of the thesis are not straightforward, and there are no easy solutions reported.
Chapter 2 (Mental models and cognitive task analysis literature) is a literature survey that ends up discovering little of direct positive relevance to the central field of interest. Its main relevance to the rest of the study lies in revealing the way in which the literature as a whole fails to address the relevant areas effectively.
Chapter 3 (Early studies) further defines the area of study by exploring, and ruling out, both a complete study of a naturally occurring complex task (ship navigation), and machine learning approaches that are not based on human performance data.
Chapter 4 (The Simple Unstable Vehicle: a manual control task) reports the more detailed exploration experimentally, of a manual control task (a simulated bicycle-like vehicle) and explains the reasons, chiefly concerning psycho-motor issues, why this too is unsuitable for immediate study here.
Chapter 5 (Non-manual control task selection) is a detailed statement of the necessary features of a task that could be studied in the manner envisaged here. This would be useful for anyone considering undertaking a similar study. It goes on to evaluate options available at the time of the study, concluding that no available systems were suitable, and that a new task had to be constructed specially.
Chapter 6 (The Sea-Searching Simulation task and first experiment) describes the construction of a nautical mine-sweeping simulation task, suitable for the desired experiments, implemented on a Silicon Graphics Iris 3130 workstation, and now being held by YARD Ltd., Glasgow. Rule-induction was found to be a viable analytic tool enabling comparison of representations, and opening up many possibilities for deeper exploration. The methods of data preparation and analysis used, are discussed at length in this chapter.
Chapter 7 (Sea-Searching Simulation task: second experiment), following the findings of Chapter 6, investigates costing information, for a modified version of the same task, as a means of discovering about information use, and about the human structuring of the task. Here, novel analytic techniques are introduced, revealing an individual ‘context’ structure to the task. Ideas both for extensions of these experiments, and for further experiments on the same task, are included in the discussion at the end of this chapter.
Chapter 8 (Overall interpretation of results, conclusions and directions) summarises the main findings of the study, also explaining the nature of the results, along with ideas about the work needed to make the results more general. Suggestions on overcoming the great remaining obstacles to applying this methodology to real tasks are put forward. This application could be to interface redesign, systems design, and training; and for operator support, we introduce the Guardian Angel paradigm, as a vision of what could eventually follow on from this work. Lastly, the implications for further work are explored. These focus around the idea of a new approach to rule induction, using a human-like context structure, which could be based on the principle of minimising the cognitive requirements of executing a task.
For several years, there has been an awareness that tasks involving complex dynamic systems pose particular problems in the field of Human-Computer Interaction (HCI). In 1985, a substantial study was carried out, as part of the Alvey Programme [36], aimed at identifying research needs within this defined area. The common factors of the systems considered in the 1985 study included
The task of controlling such systems was given the title “Information Organisation and Decision-making” (IOD), implying that these tasks formed a natural kind. Quoted as typical examples of such tasks were:
The cited study report tackles three aspects of the problem: applications; technology; and cognitive research. New applications are more complex than older ones, and tolerances are becoming tighter. This demands more sophisticated control, either by more capable people, or by providing aids for the people that there are. Such aids need to go beyond simply collecting the data, to organising it into a higher-level form, perhaps representing goals and sub-goals at varying levels. Ideally a decision aid needs to display “ ‘what the user needs to know’ ” rather than data that are easy to measure (A1 paragraph 3). This brings us to the last of the three aspects of the problem, and it is this that is of most interest here. In an IOD task, how do people organise the information, and how do they make decisions? Without an answer to this question, we risk constructing ‘aids’ that do not in fact aid the people intended. To this end, the 1985 report recommends, (among many other things) that “Research should be performed into the characterisation, representation and evaluation of reasoning strategies during complex command and control interactions…' (7 paragraph 13).
Nor does the problem look like going away soon. A recent paper by Hoc [53] states that still, in many studies, two failings of control rooms are:
And two improvements that are very often suggested are:
Presumably these ideas keep on being suggested because no-one knows how to implement them effectively.
The issue of what distinguishes the applications considered in the 1985 study (and this present one) from others, will be taken up below (§1.3.1). But let us note here that there are many areas of information organisation and decision-making that deal, for example, with organisations or businesses, rather than with complex pieces of machinery. Why does the current area of interest focus on machinery? One good reason for this is because it is the mechanical systems where there are already low-level sensors carrying information electronically, and therefore here it is more obvious how in principle one could build a support system that advised the operator about what he or she needed or wanted to know. Another reason is that machinery fails in a more spectacular and immediately dangerous way. Another reason is that in most of the mechanically-based complex systems there is no ‘adversary’—this would add a whole extra layer of difficulty onto the problem (see, e.g., chapters in [41]). To the extent to which one can identify management decision-making at all (doubted even in military circles [62]), those decisions may be based on all kinds of factors, including ones that are not normally electronically measured, and the factors which arise from the likely competition. In mechanically-based systems, at least more of the relevant information would be available, and it is easier and less unreasonable to ignore those sources of information which are not able to be sensed electronically. Thus the mechanically-based tasks are at present more amenable to HCI study and design, whereas the less mechanical tasks, although raising the same issues in principle, cannot currently easily be dealt with from an HCI viewpoint.
If a task was to be performed by a fully automatic system, which did not need (or did not support) direct human supervision, there would be little motive in designing the system with reference to how a human might perform it. In contrast, many of the systems we are considering are unlikely to be fully automated in the foreseeable future. There are a number of reasons why not. Firstly, we would not generally like to entrust decisions that can affect the lives of people to an automatic system which does not have human accountability, nor the sense of responsibility that comes with that. This may or may not be backed up by legal or licensing requirements. Secondly, there is the need to be able to cope with situations where the control system, for whatever reason, stops working, or malfunctions in a way not explicitly allowed for in the design. This is often termed ‘reversionary control’. Thirdly (a related point), there is a level of complexity beyond which it is impractical to design automatic responses to all possible fault combinations. When something anticipated goes wrong, perhaps an automatic system could have been designed to deal with it, but if something truly unexpected should happen, there will be no automatic system ready programmed for that eventuality. Fourthly, in any system in which people are involved, there are likely to be factors relevant to a decision which are not directly available to automatic sensing or interpreting. In this category would come the personal, the inter-personal, and the social factors, as well as “the apparently unmediated pickup of information from aspects of the system which were never designed for that purpose” [43].
More motivation for improving human-computer interaction in complex system control comes from the results of errors. Often, modern disasters involving high technology do not stem simply from the malfunctioning of a mechanical component, though some such malfunctioning often plays a part. What seems to be generally agreed is firstly that human error often plays a part in accidents, in the sense that if an operator had done something else at a crucial moment, the accident could have been averted; and secondly that the operator's ‘erroneous’ actions have often been performed in the absence of information which indicated a contrary action, despite that information's technical availability. Let us briefly consider some example areas.
Cahill [19] gives descriptive reports of numerous notable collisions between ships. In every case, there is no doubt that there was some sensible course of action which would have averted the collision. Even in the few cases caused by rudder failure, maintenance of a more cautious separation between the ships could have prevented the collision. Generous (The word ‘strict’ would imply that there was some definite unambiguous interpretation of the rules. This is not the case.) adherence to the Collision Regulations [61] would imply these more cautious miss-distances. The problem is that even if one ship's master adheres generously to the rules, many others will be adhering to rules that are either their own, or very distorted versions of the collision regulations.
Cahill attributes the collisions to a number of causes. First, and most frequently, there is a failure to keep a proper lookout. This means in practice a failure to obtain the information that was obtainable, whether by sight, radar, or VHF communication; and to make the routine inferences from it. Secondly, there is often evidence of low standards of safety: i.e., accepting a lower miss distance than is prudent. And thirdly, there are economic pressures. If saving fuel, or making a deadline at a port, are very highly valued, the prospect of making a large alteration of course for the sake of wider safety margins becomes less attractive.
A belief that other ships are going to behave in an orderly fashion might lead to a combination of the first and second of the attributed causes. Cahill warns that all other ships should be treated with extreme caution, since they may not have a competent person on the bridge, or even in some cases no-one at all! A good example of economic pressure from management leading to low safety margins (more recent than his book) is the Herald of Free Enterprise disaster at Zeebrugge [98].
The availability of the appropriate information, and making necessary inferences from it, are the issues that we are most interested in here. This, and other issues in collision avoidance, will be taken up below (§3.1).
The Three Mile Island incident in March 1979 generated considerable literature, but here we need only be concerned with the barest outline of the accident. The technical aspects of the accident are summarised by Jaffe [63], and more of the human factors viewpoint is given by Bignell and Fortune [14], including photographs and diagrams of the working environment. A small number of technical problems provided the background in which the incident developed.
The technical problem thought of as most important by Jaffe, and also mentioned in [14] and by Pheasant [98], was the failure of the “pilot-operated relief valve” to close properly after automatically opening to relieve pressure in the primary coolant system. However, it was indicated closed, because the indicator took its reading from the control signal to the valve, and not from sensing its actual position. One can, with the benefit of hindsight, see this as a design defect, but there are other possibilities that could have overcome this design defect. Probably, what the other relevant instruments read would have been incompatible with the valve actually being closed. Could this not have been detected, by some higher-level sensor? The operators erroneously believed the indicator, but a more thorough understanding of the plant could have led to a correct mistrust. Jaffe lists inadequate training and experience as a factor contributing to the accident. But perhaps another factor is even more significant here, and though given only four words by Jaffe, has been a significant part of hearsay concerning the incident: “A plethora of alarms”. Bignell and Fortune say that two minutes into the incident over 100 alarms were operating.
In effect, the information that would have been most helpful to the operators at the time when the incident was developing was hidden or obscured in several ways. As well as the misleading indicator, and the confusing alarms, a hanging tag obscured an indicator that showed that a different valve that should have been left open was in fact closed. In other words, there were a number of ways in which there was less than helpful provision of accurate information.
It is clear that, as with collision avoidance, there were possible sequences of actions that would have averted the Three Mile Island incident, and presumably other nuclear power plant incidents that have occurred. But where there are such deficiencies in the provision of relevant information to operators, it is hardly reasonable to blame an accident on ‘human error’. The difficulty, in the absence of hindsight, is in knowing what information is relevant to unforeseen circumstances, as well as common ones, and how to provide that information helpfully.
The report of Woods et al. [148], though concerned with nuclear power plant safety, goes beyond description of incidents, to determining whether the current state of models of cognition could help in the prediction of human errors, specifically in the case of emergency operations. They consider the kinds of cognition used in the control of nuclear power plants, using examples from actual incidents, and then consider a system from the artificial intelligence (AI) world that deals with the kind of cognition that they have identified (see the discussion below, §2.1.8.) They see enough overlap to claim that a symbolic processing cognitive model of problem-solving in this domain can be built, as psychologically plausible effective procedure. Whether or not we agree, at least this makes a case for a more detailed consideration of the relevance of this kind of model to costly technological accidents.
Although accidents and errors are notable (and newsworthy) aspects of complex systems, the present study is not a study of errors. Human error is studied as a subject in its own right (see, for example, [104], [107]), and some authors believe that the study of errors is the method of choice for the development of improved human-computer interfaces [16]. (For arguments on this point, see below §2.4). The present study will take the view that errors would be elucidated by good models of human task performance, and that one cannot expect to derive good models of human performance from error studies alone. Despite the fact that error information is very useful as an aid to iterative design, there will always remain the problem of designing the first prototype in the best possible way, and for this, models of human performance and cognition could help.
The problem area that has just been outlined is clearly extensive. The title of the present work (“Modelling Cognitive Aspects of Complex Control Tasks”) is intended to clarify, in broad terms, the part of the area that is to be dealt with here in greater detail. We shall here take each part of the title, starting at the end, and describe how this helps to define the study.
In the previous section we have mentioned real systems and tasks which have been seen as exemplifying a certain class. How can we define this class other than by example? One adjective that is often applied to such tasks is “dynamic”. This implies that something is happening over time, whether or not a human is interacting with the system at that moment. The system “has a life of its own”, and will not stop and wait for the human to complete lengthy considerations in order to come to the best possible decision.
In contrast, problem-solving has different characteristics. There may be time limits for decisions, but during whatever time is allotted for solving a problem, the problem itself normally does not change. Medical diagnosis is this kind of task, as are mathematical problems, and the kind of puzzles studied by Newell & Simon [91] In that book, humans are shown to have a great diversity of strategy and tactics for problem-solving tasks.
In the literature dealing with human performance of control tasks, particularly complex ones, Jens Rasmussen is a key figure. Much of his work is summarised in one relatively recent book [102]. His ‘stepladder’ diagram (in, e.g., [100]), which is often quoted and reproduced, gives an analysis of the mental activity which can occur between the perception of a signal and the execution of an action. The diagram is arranged in the form of a two-sided stepladder, with the height corresponding to the ‘level of abstraction’. On the left, there are the perceptual steps, from a low level at the bottom to a high level at the top, and on the right there are the steps of decision or action, from high at the top to low at the bottom. Thus, a decision could be initiated by some sensory input; this could be recognised and categorised; and then reasoned about with respect to the overall goals. A decision could be made at a high level, about desired targets, and this could be worked out as a sequence of conscious steps, which would ultimately be effected by unconscious preprogrammed patterns of physical action. Another important aspect of his diagram is that it illustrates possible ‘short cuts’ in mental processing between the legs of the ladder.
In a later paper [101], Rasmussen makes more explicit the concepts of skill-based, rule-based and knowledge-based behaviour. Skilled behaviour, of which the details are largely below conscious awareness, takes direct input from the environment (“signals”) and performs actions at a low level of abstraction. Sporting activities would fall into this category. Rule-based behaviour is where the situation is categorised as requiring a particular response, at a level that is able to be expressed verbally: ‘cookbook recipes’ not involving any reasoning, probably built up from instruction and experience. Information at this level can be thought of as “signs”. Where there are no pre-established appropriate rules governing a situation, knowledge-based reasoning is required, with an explicit consideration of goals, and perhaps planning or search. Here, the corresponding form of information is the “symbol”.
Rasmussen connects the three levels he is distinguishing with three phases of learning a skill: the cognitive, associative and autonomous phases. This implies that although control tasks normally have a substantial skill component when they are established, as they are first learnt they, too, have a knowledge-based character. A corollary is that knowledge-based processing tends to be slow, whereas skill-based processing can be fast enough to form the basis of the real-time control of dynamic systems.
In complex dynamic control tasks, there is no skilled bodily performance to require high-speed processing power, but it is generally agreed that these tasks use the kind of processing that Rasmussen refers to as skill-based. The wealth of information available, and the constraints of time in which to process it and come to decisions, may be the alternative reasons why control tasks need the high-speed processing, characteristic of skilled performance.
In contrast, problem-solving, particularly of the ‘puzzle’ kind (e.g., missionaries and cannibals) met with in AI, often uses a minimum of information defining the problem (typically a short piece of text). If such a problem is not trivial, it must need knowledge-based processing in order to solve it, for if appropriate effective skill-based processes had already been established, we could imagine a very quick solution would be found, since the problem is defined by so little information.
These contrasts between knowledge-based and skill-based processing suggest that in control tasks mental processing has some bias towards the skill end of the continuum, whereas in problem-solving domains, there is the opposite bias towards knowledge-based processing. But to avoid confusion, we must recognise that whenever a process operator goes outside the familiar bounds of experience, their information processing will again be characteristic of the learner, that is, knowledge-based.
Knowledge-based, and problem-solving, tasks, including the problem-solving-like diagnostic tasks that often appear as part of supervisory control, are not here the principal objects of study, because the fact that these situations are less practiced, and the fact that the initially plausible actions have a wider range, together mean that there is less likely to be a uniformly repeated pattern to the skill. If we can first deal with skills that are better learnt, we might then be on the way to dealing with the greater complexity of the knowledge-based area.
There has been much study of complexity from the point of view of computer systems or algorithms, which is generally based on some formal representation of the studied system. However, in HCI, some authors take a much more informal view of complexity, which is very reasonable considering how difficult would be the attempt to formalise a real complex industrial process, and how ambiguous the results of such an exercise would be. For example, Woods [145] gives four dimensions of the cognitive demands of a task domain. These are:
A world where all of these are high would be described as “complex”.
Woods details many ways in which a high value on his dimensions can arise. Specific features that often occur in our typical complex systems include: multiple goals; hidden quantities; long time constants; servo systems embedded within the task; distinct phases to the task with different rules; and a quirkiness that comes from general rules having many exceptions, special cases, etc. However, arriving at a compound measure (even qualitative) based on this multiplicity of factors would be difficult, and might not add much to the common intuitive idea of complexity.
This study proposes a simpler informal operational definition of complexity. A complex task is one for which there are a large number of potential practical strategies. The rationale behind this definition is that if there is only one or a very small number of practically feasible methods of performing a task, then performing it is simply a matter of sticking to explicit rules, such as might be found in a rule book, and there would be the potential for automation, no matter how intricate or involved was the required processing. A typical example of intricate processing that is not complex might be performing arithmetic calculations. Thus, the opposite to ‘complex’ on this definition would not be ‘simple’, but rather ‘straightforward’ or ‘unambiguous’.
Many further examples of tasks that are not complex would be found under the heading ‘clerical’, and indeed, many of these tasks have been automated. When a task has a necessary motor skill component, it is more difficult to be sure of the level of complexity, even under the new definition. How many varying strategies are there for baking a loaf of bread? for sweeping a road? for weeding a garden? The lower the level of analysis, the less clear is the answer. But at least there is one sense in which, say, following a recipe is not complex. That is, that we can describe unambiguously, at some level, what steps should go on—even though the method of effecting those steps (how they should go on) may depend on the person and the situation. The examples of text editing (Chapter 2, passim), and bicycle riding (Chapter 4, come up in the course of this study, and will be discussed further there.
Many tasks are, on the other hand, clearly complex. Programming is an obvious example: for anything but simple programs, people are liable to choose different ways of solving a given problem, and different ways of implementing those solutions, unless constrained by a ‘structured’ methodology. Another good example would be running a business. There may be guidelines, there may be textbooks, but for these tasks, and the control tasks we are considering, there is no fully definitive account of the details of how the task should be performed. This kind of complexity is obviously closely related to the general complexity dimensions given by Woods and by others. In complex tasks, the complexity defies a complete logical analysis, leading to a multiplicity of possible methods. In the doubtful cases, we have not in fact yet performed a complete logical analysis, and therefore we do not know whether there are few or many possible methods.
Many writers in the field of HCI and complex systems (e.g., Rasmussen, Reason) stress the importance of understanding human cognition. The paper by Woods [145] also gives an example of this: “… we need, particularly at this time of advancing machine power, to understand human behavior in complex situations”. Researchers in the field investigate different aspects of cognition, and a number of these will be looked at in Chapter 2.
For tasks that are straightforward rather than complex, with little or no scope for different methods, a logical analysis (including the structures and methods that of necessity arise from the nature of the task itself) might possibly cover the bulk of what is interesting about the task-related cognition. In tasks where the logical structure is salient, it becomes interesting to study the extent to which humans do or do not conform to the logical structure, as Johnson-Laird [64] and others have done. This is not done in the present work.
But the more complex a task is, the more will there be aspects of cognition that are contingent, rather than necessary—‘mental’, rather than purely logical. If the purpose is automation, then arguably how these contingent aspects are implemented is not centrally important; but to understand human action in complex control tasks, we do need to go beyond the necessary logical structure, and investigate some of the contingent cognitive aspects.
These cognitive aspects, that are in the subject area of the present study, include the structures and methods that humans devise to enable them to perform these complex tasks, within the limitations of their ability, and dependent on circumstances. As will be discussed below (§2.6), the aspect of cognition that emerges as central to this study concerns the mental representation underlying the rules describing complex task performance. This goes beyond the logically necessary.
Unlike the choices implied by the other parts of the title, we have no option other than modelling, because we cannot directly observe human cognition. Models of some kind have to be built, and if these models are to be validated, they must be tested against the experimental data of recorded human action, which is what we observe.
The choice of what approach to take to modelling is properly explained after the next chapter, which discusses the literature on mental models, cognitive models, and cognitive task analysis. Before starting on that chapter, it may be pertinent to remember that the designers of complex systems form a very important class of end-user for such models. Within the point of view of systems design we can assemble a number of possible purposes for models of operator's mental processes:
The point raised above (§1.2.1), about “what the user needs to know”, could be taken as referring to either of the last two items in the above list.
If just system designers have so many different possible uses for these models, it is not at all surprising that the literature has a great range. Chapter 2 casts the net wide at first, and there it becomes increasingly apparent which published work relates to which of the purposes, and how relevant it is to our present study. The kind of models and modelling to be studied in this work is best described in conjunction with an overview of the thesis, which now follows.
Within the context that has just been defined, the thrust of this thesis is to introduce, explore, and progressively to refine, a modelling concept. The idea behind the concept is that we should be able to model something about human cognition by analysing human actions.
In concentrating directly on actions rather than intentions, on what people do rather than what they say, we are moving away from the kind of study based on verbal reports. Verbal reports and protocols (“Protocol” is in this study taken to mean a record made as the task was actually being performed. “Verbal report” is a more general term.) have been the method of choice (or perhaps the default method) for finding out about human concepts and rules for a considerable time. But as Bainbridge points out [6], verbal reports do not directly inform us about what people actually do. We need other methods of study, at least to corroborate verbal reports if not to replace them.
One of the main results that we can hope for from a study of human actions is to discover regularities behind those actions: rules about what action is taken in what situation. Recently, a new paradigm for finding such rules has emerged from the effort to construct “expert systems”, and this is based on machine learning, or, more specifically, rule induction, where rules are induced from examples (see, for example, [87]) Can this paradigm be applied to inducing rules governing human behaviour? One classic study [77] suggests that it can be applied to human diagnosis of soy-bean disease. But in what other situations? Would it be possible to discover rules behind humans' interactions with more complex, less documented and less analysed systems?
If we could discover such rules, they might well form a very significant part of a model of human task performance. One might be able to construct a model predicting the actions that a human would take in a particular task, and it would be natural to ask the question whether these rules could be regarded as an aspect of the mental structures underlying task performance in that human. This could lead on to comparison of these rules with verbal reports, and no doubt many other avenues of investigation.
Looking at these questions leads into the realm of representation, which one can come to see haunting every shadow in artificial intelligence and cognitive science. How do humans internally represent their practical, largely unspoken knowledge? Not only has this question endless fascination, but also answers to it have important practical implications for the design of computer-based information and support systems for the control of complex systems in industry.
It is from a synthesis of such practical and theoretical concerns that this thesis takes its structure, and in outlining the structure of the thesis, we can see more of what the modelling concept is about. At the most abstract level possible, this structure could be given as follows: the practical problems, reflected on, reveal a lack of theoretical underpinning; this is confirmed with reference to related fields of study; an attempt to get to the bottom of the theoretical deficiencies leads to the motive to study human representations, and this motive, tempered by considerations of feasibility and refined by experience, suggests an experimental method; the experimental results give some pointers towards the broader objectives, and show something of the distance that needs to be travelled to get there.
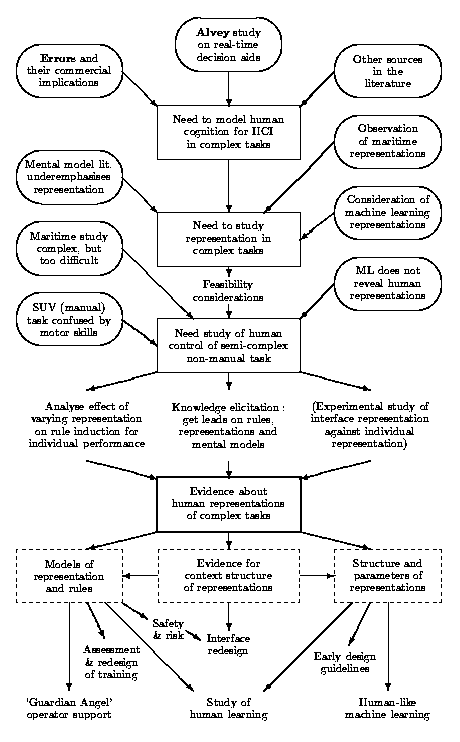
Modelling cognitive aspects of complex control tasks: one possible view of the structure of the thesis
At the next level, some more of the details of the structure appear, illustrated in the Figure. The need to model human cognition, in order to improve human-computer interaction for complex tasks, was given as an initial problem, and is recognised by many writers. Some examples have been given above (§1.2). This leaves us at the uppermost rectangular box in the figure. From the literature on mental models and cognitive task analysis, (Chapter 2), together with early studies, arose the conviction that central to the problem is the issue of representation (the next rectangle). This argument is first made explicit immediately after reviewing the literature (§2.6).
Early studies carried out by the author (Chapter 3) confirmed the importance of representation, and served to explore what research goals might be desirable and feasible. Using maritime collision avoidance (an initially given starting point for the research), as a subject of this study turned out to be fraught with many theoretical and practical problems. A study of machine learning of dynamic control clarified the formal aspect of representation, and confirmed that despite inevitable practical problems, human experimentation was necessary to discover human cognitive structures. A bicycle-like simulation task (the Simple Unstable Vehicle) gave interesting results (in Chapter 4), but it increasingly became clear that this also was off target. What emerged from these studies was a much clearer view that a semi-complex, non-manual task was needed as an experimental vehicle.
The very necessary evaluation of different candidates for this experimental task is not shown on the chart. This is given in Chapter 5. Having chosen the task, implementing it was difficult and very time-consuming; however, again, this stage is a necessary one and as such it adds little to the structure diagram. When originally implemented, it was envisaged that there would be three parallel ways of proceeding from the experiment to evidence about human representations. The first two have already been mentioned: verbal reports; and rule induction. The third depended on discovering different representations for different subjects: not only that, but different representations that could be transformed into different versions of an upgraded interface. In practice, although there was some evidence for differing representations, this was not enough to make different interfaces with any degree of confidence. The experiments that investigated these first two methods are given in Chapters 6 and 7, but the third way remains future work.
It was clear from early on that the originally motivating objectives were out of immediate reach. But it is hoped that a provisional mapping out of how these goals might be achieved could be of some value. In the figure, future paths are shown in the lowest part of the diagram, underneath the box with the heavy outline. These are expounded in Chapter 8.
The justification for this work is not in whether it reaches these further goals: rather, it is that this work explores, and attempts to fill in, some of the necessary foundations on which progress towards those further goals may be built. The further goals have had an important shaping function on the work as a whole, but they remain as ideals. But if one is unaware of them, it is possible to see this research as a collection of disjointed studies, rather than as a coherent whole. The ultimate achievement of the goals required (and still requires) groundwork; the groundwork needed exploration; and that exploratory aim is the point around which this work coheres, and it is reflected in all the sub-studies. The wide range of this exploration is due to the relatively little that had previously been done in this field of study.
In this work, the people who interact with complex systems, for whatever reason, in whatever way, are referred to by a number of different terms. Whatever the intention in the literature (see below, §2.1.1), The terms “user”, “operator”, “trainee”, “player”, “subject”, etc., are used here, not to indicate exclusive classes of people, but simply to use a term that fits reasonably into the context. The reader is cautioned against reading too much into this terminology: he or she who is a user could equally be an operator, player, etc.
Within the study of Human-Computer Interaction (HCI) there is a substantial body of literature which uses the phrases ‘mental models’, ‘user models’, ‘conceptual models’, etc. Confusion starts because there is no generally agreed single term which covers these phrases, and other similar ones. For brevity, we will exploit the ambiguity between models of the mind and models in the mind, and here use the term ‘mental models’ as a general term standing for all of the models referred to, and the general models implicit in modelling methods, techniques and theories, as well as having a slightly more circumscribed meaning than it tends to have in the literature.
In this literature there is no universal agreement about exactly which aspects of the users or their actions should be modelled, or how they should be modelled, and as a result writers have tended to define their area of interest implicitly by reference to others' work, or by concentrating on a particular point of view, or a particular practical problem, or particular aspects of modelling. The categories arising from this process of self-definition are not necessarily the best from the point of view of defining independent sub-literatures, or separating out different logical aspects of the subject. Nevertheless, these categories provide a starting point for a sketch of how the literature appears in its own terms: a kind of natural history of the literature. The objective in this first section about the literature is to give that natural history, before starting to discuss individual papers or theories: that will come after substantial discussion of the structure of the whole field.
The lack of definition in the subject also means that the boundaries between it and a number of neighbouring fields are ill-defined. Those fields which are left out here, or only mentioned in passing, include much of cognitive psychology, ergonomics, control theory, general systems theory, cybernetics, information theory, decision theory, management science, and planning. Intelligent tutoring systems and computer-aided instruction are only mentioned briefly. Similarly brief is the discussion of optimal control modelling, since it is less concerned with cognition. A guide to the literatures in control theory, communication theory, statistical decision theory, and information processing is given by Woods & Roth [148].
The language chosen by authors tends to indicate their background and informal affiliation. The term “mental model” emphasises that the object of study is a model which does, or could, belong to a person. It often goes along with the idea that a person has some kind of imagery in their head, which can be ‘run’, or otherwise directly used, to imagine and predict what will happen to something. Authors using this term favourably are concerned with finding out, or modelling, what the person actually ‘has in their mind’.
“User models”, on the other hand, often represent a view of the user and their attributes to be used equally well by a designer when designing a system, or by a computer system when interacting with a user, the latter model being termed an “embedded user model”. A “user” is generally seen as someone interacting with a computer-based device or system, which provides a service in the context of either work or leisure. Thus a “user” might use a word processor, a photocopier, or a library system.
If, in contrast, the person interacts all day long with machinery, the function of which is to serve some purpose external to the person, she or (usually) he tends to be called an “operator”. Someone may “operate” a ship, an aircraft, or a piece of industrial plant. “Operator models” tend to model this kind of operator from the perspective of more traditional ergonomics and cognitive psychology. The term is also often used by those writing from the engineering tradition of optimal control modelling.
Various uses of the term “conceptual models” have been noted. The most obvious usage follows the idea that a ‘concept’ is an explicitly expressible idea, thus “conceptual models” are models communicated to, or used by, people; usually relevant to the early stages of using or operating a system, where it is the general concepts that are the most important features of a model. A conceptual model would be expressible in words or figures, and probably communicated during the course of learning to use or operate a system.
There are other terms used in the literature, of which some (e.g. “student models”) have an obviously specialised use. More cautious authors say explicitly what aspect of what they are modelling, and do not use any of the general terms unqualified. All these terms are used in the literature, but each of the groupings in the literature tend to have their favourite.
Making a model of task performance can naturally involve task analysis: the breaking down of a task into component sub-tasks and elementary actions. In general, there are many possible ways of doing this, and, unlike the case in some branches of the longer-established sciences, there is no established canonical method for analysis of tasks, nor any widely agreed set of primitive elements which the analysis would give as end-points. The more complex the task, the more potential choice there is of different analyses or styles of analysis, just as there is more potential choice of methods of performing that task.
Traditionally, task analysis has been seen as fulfilling many purposes, including personnel selection, training, and manpower planning, as well as workload assessment and system design, and various analytic procedures have been proposed to meet these purposes. Many of these purposes are given by Phillips et al. [99], who also note that “systems which are stimulus-intensive, non-sequential and involve many cognitive responses, such as computer-based systems” have been less amenable to traditional methods.
There has recently been a growing body of opinion, that styles of task analysis that do not take into account relevant facts about human cognition are less than fully adequate for the analysis of complex tasks. This has led to attempts to describe those principles of cognition which are most relevant for task performance, or to devise task analysis methods that are in harmony with the human appreciation of the tasks. However, the lack of firmly established theoretical principles for such an analysis has meant that various authors have taken, or suggested, different approaches to this goal of a cognitive task analysis.
If we take a view exemplified by Sutcliffe [135], “…task analysis is a description of human activity systems and the knowledge necessary to complete a task”, then task analysis is closely related to mental modelling. Cognitive task analysis could be regarded as task analysis done from a mental models viewpoint. Much of the literature reviewed in §2.3 could be seen equally from the perspective of mental models or cognitive task analysis.
Barnard [9] (see §2.3.2.4) sees cognitive task analysis as analysis in terms of the cognitive subsystems needed to perform the task. This brings in different considerations from those of other authors, and thus the phrase needs using with caution. For this reason, the discussion here prefers the term ‘mental models’.
The first strand of the literature that we shall consider here focuses around the issues raised by Card, Moran & Newell's book, “The Psychology of Human-Computer Interaction” [20]. This book is exemplary in defining an audience, and giving a clear scenario of the possible use of the end products of the analysis given. It sets the scene well to quote some extracts from their application scenario (pp. 9–10):
A system designer, the head of a small team writing the specifications for a desktop calendar-scheduling system, is choosing between having users type a key for each command and having them point to a menu with a lightpen. … The key-command system takes less time … he calculates that the menu system will be faster to learn … A few more minutes of calculation and he realizes … training costs for the key-command system will exceed unit manufacturing costs! … Are there advantages to the key-command system in other areas, which need to be balanced? …
This gives us a picture of the use of formal models, which is in calculating reasonable values for expected human performance on a system. The model is of human abilities and ways of doing tasks. Card, Moran & Newell suggest that systems designers will be able to use their models and principles of user performance in the design process, and also that psychologists, computer scientists, human factors specialists, and engineers will find their work of interest.
Card, Moran & Newell expect designers, before using their methods, to have considered the psychology of the user and the design of the interface, specified the performance requirements, the user population, and the tasks. Thus it can be seen that their methods assume a context of use where the problem has already been specified, rather than being of use in the initial stage of breaking down a real-world problem to create the initial task or interface design. This is a fairly limited objective, but by being limited it becomes achievable, and it is not difficult to see how it may work in various circumstances.
A number of authors have followed this general lead, by taking a simplified tractable model of the user, and analyzing human-computer interaction in terms of a formalised approach to modelling. Some models have a worked-out formalism, and they could be called formal models, whereas other models have not yet reached that stage (though clearly intended to) and could therefore be called formalisable. In another sense, the modelling method only provides the means of producing a formal model, actually produced when the method is applied, and in this sense we could say that the methods given in the literature are able to formalise facts or suppositions into usable models. For these reasons, we call these modelling methods ‘formalisable models’, following Green et al. [45]. Some reviewers here distinguish ‘performance’ models, which make predictions, generally quantitative, about the time or the effort involved in operations [12, 20, 66]; and ‘competence’ models, which tell what someone is, or is not, able to do (e.g. [96]). There are also papers which discuss this kind of approach in general [16, 21, 45, 127, 140], in particular [122, 123], or take their own specific related approach [9, 83].
This class of model answers the question, “what models can or could predict aspects of human performance?” As techniques for implementing models get more sophisticated, the boundary between working and just potential models is likely to shift, with more being included in the class of implemented, predictive models. The application scenarios are likely to widen and diversify from Card, Moran & Newell's vision given above.
Engineering and operator models could also be described as formal or formalisable, since they work with numerical or mathematical formalisms, and control theory, rather than informal ideas; and they offer predictions on issues such as: amount of deviation from some ideal performance; workload; errors; and task allocation. Some examples of literature discussing such issues are given in the present bibliography [46, 115, 132, 136, 139, 153].
Since this kind of model is based on engineering control theory, it is most suited to the simulation of tasks which would be amenable to that discipline, such as the manual control task of track-following, where there is a clear definition of ideal performance, and therefore measurements of deviation from the ideal are possible. The models are usually justified by comparing the characteristics of the performance of the models, with measurements of similar characteristics of human performance. But there is little or no justification in terms of psychological mechanisms for the generation of the human behaviour. Thus, these models are models of output, rather than models of internal processes.
The limitations of this kind of approach are acknowledged by some authors in the field (e.g., Rouse [115], Zimolong et al. [153]). Such models cannot easily and accurately deal with multiple tasks. Variation between individuals is clearly not easy to accommodate within an optimal model, and higher-level decisions taken at longer intervals are much less easy to model this way than continuous control tasks with short time constants. As limited-purpose models they are no doubt useful, but they are not well suited to rule-based tasks, and even less to knowledge-based ones, because in these tasks it is more difficult to posit ideals. And since a complex task has initially been defined here as one for which there are many practical strategies, these models, based on uniform strategies, even where parameters are allowed to vary, cannot be a good choice for modelling complex tasks.
There would seem to be little prospect for any contact between engineering models and the psychological and other models considered in this study: the references cited by authors in this field overlap little with those in the other fields. For all these reasons, this kind of model is not reviewed in detail here.
There is a set of models, less closely-defined than the formalisable models above, which can be seen as attempting to model what users “have in their heads”, at the same time trading off the clear-cut predictive ability of the previous classes of models. Gentner & Stevens' book, “Mental Models” [40] is a wide-ranging collection of papers which are fairly representative of this kind of approach to modelling, and many authors cite that collection, or at least some paper from it [18, 37, 56, 70, 84, 85, 133, 150]. Inasmuch as these models attempt to model human cognitive processes from a cognitive psychology standpoint, they have also been called “cognitive models”.
It is difficult to find a common subject in such a broad-ranging literature, which includes models of memory, of learning, of analogy, of commonsense reasoning, all from some kind of computational or algorithmic point of view. What these papers have in common is more like a general attitude: the authors seem to wish to propose models of various aspects of human action broadly in terms of computational processes, but not at such a simplified level as the previous class of models. This usually means that they do not expect practical implementation of their models now or in the near future. They do not in general provide performance predictions. However, the nature of these models is generally such that we could envisage them being formalised and implemented if there was enough time and interest.
Most of these models attempt to clarify what is going on in one area of human thinking, rather than trying to be all-embracing. This means that they can be taken as complementary to one another. Different methods which look irreconcilable may actually be appropriate for different areas of human action. These approaches could be seen as addressing the question, “what may we suppose to be the basis of a user's or operator's performance?”
The previous group of models focuses on the theoretical basis, but the application of models to training is to produce a practical result. Kieras & Bovair found (in a well-cited study [67]) that explicit conceptual models presented to learners made a difference to the efficiency of their learning. This bears on the topics of training and learning, where, as some authors have pointed out (e.g. [21]), explicit conceptual models, and analogies, have a large role to play. The model delivered to the learner or trainee is simpler than that of the designer or trainer, and although it is intended to form the basis of the learner's model of the system, it could hardly be the same as the learner's final model, for if it were, the learner could not be continuing to refine his or her model (as is clearly the case in practice). There is therefore a sense in which the study of this kind of model is not a study of the actual mental models that are in the subject's mind, but rather a study of how to stimulate a user to develop his or her own model more quickly. The corresponding question is, “what model can we give to a user to help him or her understand and control a new system, or device, or machine, or program?” There are other opinions on this question that differ from Kieras & Bovair: for instance, Halasz & Moran [50] consider analogy harmful in the training of new users.
Conceptual models, as in Kieras & Bovair, are unlikely to be identical with the model in the trainee's head, so there is scope for studying the latter model as part of an attempt to see how much of the presented conceptual model has been assimilated. The present study relates to a possible study of what the trainee has actually learnt, but not directly to studies that omit this.
In decision support, and skilled operator's models of complex dynamic processes, effective HCI relies on knowing what is currently in the operators mind, which may be complex and only partially conscious or able to be verbalised, rather than knowing about the conceptual level of the model, which may have been taught to the operator, or which the operator may teach to someone else. For this reason no review of the training and learning literature is given in this paper, other than in passing. Murray [89] gives a useful wide-ranging review of the modelling literature with close attention to this part of the field.
Different again are models of human learning, which may or may not be used in the context of training. A model of learning would imply a model of what is learnt, and modelling what has been learnt is a reasonable precursor to modelling (rather than merely emulating) the learning process itself. Again, the present study does not relate centrally to the modelling of learning independently from what is learnt, since in complex tasks it is both difficult and important to model what has been learnt, and one cannot expect to achieve this thoroughly from an a priori approach to modelling learning.
Training focuses more on the performance of the user than on the models they actually develop. So what can we find out about what is in a user's model? There are a number of papers that consider how to derive mental models from the users or operators themselves [2, 6, 95, 124]. This is a tricky problem, since users can be quite idiosyncratic, (as recognised long ago by Newell & Simon [91, p.788]). Knowledge elicitation techniques such as protocol analysis and personal construct theory have been used to this end.
Typically, if a user or operator knows a lot about something, they will be able to answer many direct questions about what they do in different situations, but they may not be able to answer questions about their knowledge, such as “how much do you know about such-and-such?” If they do not know the extent of their knowledge, and even more so if some of that knowledge is unconscious, they will not be able to give an exhaustive unprompted account of it, and therefore the knowledge that is actually elicited will be restricted by what questions the analyst asks, which will in turn be restricted by the concepts held by the analyst (or in the case of the repertory grid technique [124], restricted by the elements chosen for the elicitation of constructs). If we have an explicit model of the user's knowledge (and model) of the system, our model will limit what we will be able to find out about the user's model, which will not be unhelpful, if we wish to find out correspondingly limited things. But if we have no explicit model, what we discover about the user's model will be at the mercy of chance, or our intuition. In other words, the way we think of the user's model is intimately bound up with what we are able to discover about it. This means that advances in our model of the user's model will enable more knowledge to be recognised, and conversely, if we know something informally about the user's model that we want to capture, but cannot yet because of the restrictions of our model of the user, that informal knowledge may act as a stimulus to elaborating our model of the user.
Another branch of this literature, where knowledge is gathered from people, is the field of expert systems. The normal area of application of expert systems is, as their name implies, to encode the knowledge of an expert in a way that a non-expert can have access to the expert knowledge and, if possible, reasoning behind that knowledge. Typically, though not exclusively, this has been in such areas as diagnosis.
Diagnosis is generally something that can be discussed and reasoned about, and even if it is difficult to elicit all the knowledge from an expert in diagnosis (in whatever field), it is at least conceivable. In process operation, however, Bainbridge [6] points out that much of a process operator's knowledge is typically not able to be expressed readily in verbal form. This means that it is difficult to construct a faithful model of operator's decision-making, from the basis of verbal reports or protocols, as would be the norm following the expert system methodology.
Woods & Roth [148] did not consider the problems of elicitation, but instead considered the cognitive activities performed in nuclear power plants, as their criterion for selecting an expert system as a possible basis for a model of behaviour in the nuclear power plant domain. The system they chose, CADUCEUS, originally from medical diagnosis, fulfilled their criteria of: having a structured knowledge representation; having the ability to simulate problem-solving under multiple-fault, multiple constraint conditions; and allowing data-driven revision of knowledge over time. As with engineering operator models, one question of importance here is, to what extent are such models simply modelling some overall features of human performance, rather than providing a causative model compatible with cognitive psychology? If the object of such a model is merely to provide expert system decision support, then one cannot object to it just on the grounds that it does not model human cognitive processes. However, to provide a sound basis in general for designing operator aids, we do indeed need to model the operators' cognitive processes, at least in terms of their information usage. But Zimolong et al. [153] did not find any expert systems for process control, whose output matched human output well at a detailed level. For these reasons, it was decided to omit detailed review of papers following this approach.
Whatever the difficulties in elicitation, any good model has to explain the major observed features of human cognition in complex tasks. What needs to be in a good model of a user or operator? A few authors approach the subject of modelling from the standpoint of knowing about the realities of controlling complex dynamic systems [2, 3, 7, 57, 58, 100, 101, 125, 138, 143, 146, 148]. These realities are of such intricacy that there are as yet no proposed fully-fledged models which attempt to account in detail for both normal and emergency operation of complex systems, including errors and recovery from them. The papers of this type therefore tend to tell us (and system designers) about the features which should be taken into account when forming models of process operators and their knowledge and skill. Jens Rasmussen is a central author here, and most of the other authors cite him.
This is the least formalised area in the field of mental models, and this can lead to a sense of vagueness when reading the papers. This is due to the complexity of the questions being approached, compared with the questions dealt with by the cut-down idealisations in the currently formalised models. In this trade-off, informal models gain breadth of applicability at the expense of precision. These authors are more concerned with realism than with ease of formalisation.
Since this division of the field of mental models has not yet reached the stage of common agreement, it is not surprising that there are papers which do not fall neatly into one of these classes, including several review papers covering various parts of the field [13, 51, 88, 106, 140, 142, 150].
Another reason why the literature is not well-defined is because it is possible to see ways in which the divisions will break down in future. It may be naïve to think that one grand mental model could perform all the functions of all the different classes outlined above, but the idea is certainly attractive. If a definitive, theoretically sound model were invented (such as we might expect in the established physical sciences), it would certainly have something to say about all the areas of mental modelling.
More realistically, there are developments which are more easy to envisage, which would move or remove some of the boundaries implied above. Firstly, there is the tendency for implementation techniques to become more intricate and powerful, thus enabling more of the models which have been devised to be used in a practical way. This may mean that some of the less-restricted models pass into being formalisable. Also we may expect models to become more like the humans they are intended to model, which is a conceptual, as well as a technical, advance. The section of the literature on models taken from real life may find greater contact with other sections.
We cannot expect predictive models which accurately reflect all the aspects of human cognition relevant to systems designers until development and integration of the research areas has taken place.
Part of the disarray of the literature is caused by different authors meaning different things when they write about models, and by these meanings not being entirely clear and explicit. The literature shows that people have been aware of a variety of meanings for many years, and there are several papers which offer classifications of the meaning or usage of the terms. We shall start this section by looking at the distinctions between owners of models and between objects of models. Then, looking at the purpose of models, we find that there is a reasonable correspondence between purposes and the categories given in the previous section. This suggests that the purpose of a model is a important factor in classifying a mental modelling approach.
Distinguishing the owner and object of a mental model is important, particularly for readers who may gain a wrong impression by writings that do not make this clear. To start clarifying this, let us imagine a situation where we have a user using a system (often complex) which has been designed by someone else (a designer), and the interaction is being studied by another person, a scientist.
An author often quoted or cited for distinguishing the owner and object of a model is Norman [94]. He distinguishes the target system t, the scientist's conceptual model of that system C(t), the user's mental model of that system M(t), and the scientist's conceptual model of the user's mental model C(M(t)). This brings out the importance of whose model it is, in that M(t) is not assumed to be identical with C(t). Equally well, C(t) is not the same as C(M(t)), even though it may be the same scientist who is doing the conceptualising. Great potential confusion may arise, because C(M(t)) is intended to be like M(t). Other authors sometimes talk loosely as if C(M(t)) actually was M(t).
Now if the user could reliably describe his or her mental model M(t) explicitly, the scientist could presumably accept this, and there would be no need for a separate C(M(t)). But most often, much of M(t) is implicit and tacit. Remembering this should help to reinforce the distinction.
Streitz [133], elaborating Norman, introduces the needs of a designer into his “mental model ‘zoo’ ”. The models of the target belonging to the system designer Cd(t) and to the psychologist Cp(t) may differ, as may their models of the user's mental model, Cd(M(t)) and Cp(M(t)). He also makes the distinction between the ‘content problem’ (the problem to be solved, itself) and the ‘interaction problem’ (how to solve the problem with the tools in hand). The user's mental model of the content domain is referred to as M(c). We may follow Streitz in suggesting a different ‘target’ for each of the different ways in which someone may be treating a system. Clearly there are many such distinctions which could be made in the spirit of the original ones put forward by Norman.
Whitefield [140] gives a classification based on these same two dimensions of ‘whose’ and ‘what of’. He claims that this classification is of use to systems designers, so it is worth a closer look. He has
In the end, Whitefield admits that this classification fails to capture some of the intuitively important dimensions, such as the distinction between creator and user of a model. Also, his classification does not produce homogeneous classes, and it fails to classify some models unambiguously. Nor does his classification capture the way in which the literature organises itself: the classes cut across the categories outlined in §2.1. Whitefield's classification does “discriminate and relate” elements together (one of his stated aims), but one may question what these elements are “relevant” to. If a classification were to expose fundamental divisions which were relevant in all circumstances (such as species in biology), it would be very valuable. Whitefield gives no idea about why, or even whether, he thinks these particular two dimensions are fundamental ones. He confounds his own classification by putting together researchers' and designers' models, and then briefly describes how, in theory, a designer could use the different kinds of model. It is very difficult to see what this analysis adds to the simple description, for a few published modelling methods, how their authors and others envisage them being used; and difficult to see what relevance Whitefield's classification has, beyond communicating to the HCI novice the undisputed fact that the identities of a model's owner and object can make a difference to the type of model that is, or could be, used.
There is also the question of what a model is for. As we shall see, the categories revealed by this question map much more closely onto the apparent groups outlined in §2.1, suggesting that the purpose of a model is an important feature for its classification. Although the purpose of a model is often ill-defined in many authors' works, it seems that without the dimension of purpose, there is little order or sense to be made from the literature on models.
Norman [94] makes passing reference to the purpose of a model without considering purposes as centrally important. In his view, the purpose of a mental model is to allow the person who owns it to understand and to anticipate the behaviour of a system, whereas conceptual models are devised as tools for the understanding or teaching of systems. (Norman talks of physical systems here, but we can easily extend the idea to cover human or social systems.) In this way, Norman recognises the question of what the model is for, without considering it as contentious. In particular, he does not discuss the possibility that a user may have a number of separate models of a particular system, used for different purposes, nor the possibility that a scientist may have various models of the user's mental model of a particular system. Norman describes models as tools, and we may reflect that, for a tool, the purpose is at least as significant a determining factor in its nature, as the identities of the tool's user and the object on which the tool is used.
Other authors make more of the importance of purposes of models in general. Murray [88] posits that “a statement of a model's purpose is an additional necessary constituent of any taxonomy which is to be used to specify the boundaries of different classes of models”. Benyon [13] asks “what is the purpose of the User Model? Is it to assist designers? to assist the user? to provide an adaptive capability for the system? to assess the knowledge of the user? to develop and refine other models? to assist research into human cognition?” Wahlström [138] distinguishes the following possible purposes of models:
Let us follow Wahlström's distinctions, in order to examine the significance of models' purposes, and to consider the relationship between purpose and form.
There is a general approach to the concept of mental models, which aims not to describe particular users' mental models of a system, but rather to describe general issues for the designer to consider when thinking about the needs of the user. These issues may include general principles of human cognition, and its limitations; general observations about the way people deal with complex systems; factors which affect human tendency to error; and so on. These considerations may aid systems designers simply by getting them to think along appropriate lines. These approaches fall largely into the class described in §2.1.9 above.
If the purpose of a model is communication of an idea (outside the training context), there is not much we can deduce in principle about the form of the model. The way in which a researcher may attempt to communicate important ideas to a systems designer could be expected to vary greatly depending on the individual researcher and his or her appreciation of, and rapport with, the intended audience, which is typically seen to be both academic and professional.
Three surveys of opinions or practice of professional designers [11, 51, 131] give no positive evidence that designers are influenced by this kind of model. Designers seem to have many other more pressing things in mind: consistency and structure in the software; commercial pressure and deadlines; compatibility, convention and current design practice are among these.
Of course, these ideas continue to circulate among HCI researchers. More discussion on this topic would say no more than could be said of ideas within scientific enquiry in general.
A possible purpose for a mental model is to aid understanding of human cognition. Researchers need to develop their understanding of the field to continue to generate further useful facts for designers, whereas one would expect designers to be more interested in the applicable facts. Models of user's mental structures and processes could help researchers' understanding by giving extra ways of looking at cognition, whether by metaphor, analogy or other means. It is the kind of knowledge that requires further digestion and synthesis by cognitive scientists and HCI researchers before it is directly useful.
Some authors see mental models primarily in this way. For example, Young [150] suggests that what he calls a “User's Conceptual Model” (even though this sometimes refers, as here, to a model possessed by a psychologist) should help to explain aspects of the user's performance, learning and reasoning about a system, as well as providing guidelines for good design. Similarly, Carroll [21] says, “Mental models are structures and processes imputed to a person's mind in order to account for that person's behavior and experience”, thereby characterising models as psychological theories. There is much overlap between the class of models described here and those described in §2.1.5 above.
Viewing mental models as aids to understanding does not imply much about the form of such models, except perhaps that they should be comprehensible by the people for whom they are intended, i.e., researchers in HCI. It would be shortsighted of HCI practitioners to underrate the importance of this kind of model just because they are not immediately useful. It is from here that future developments may arise.
A designer may wish to know something about the potential or actual performance of a human-machine system, while wishing to avoid the need to do experiments involving people, which could be time-consuming and expensive. This could be in the context of choice between possible designs.
The formalisable models mentioned in §2.1.3 explicitly aim to predict either human performance or competence in terms of their analysis of the task. For any model to be a useful predictive tool, it must be able to take values of things which are assumed to be known, and produce values for the quantities which are to be predicted. This, of course, depends on what quantities are assumed to be known, or taken as known. One view of the essence of a model could be to predict whatever the modeller was interested in, from the things the modeller knows.
There is an important distinction within this class of models between models to be communicated and ones for private use. If the model is made to be communicated it would of course have to be explicit; but the models that we spontaneously generate, for the prediction and control of the things that we deal with in everyday life, are not normally available for direct inspection, either by others or even (often) by the owner of the model, and therefore if we wish to know about these models, their contents have to be inferred.
The formality of explicit models enables much more detailed discussion of particular approaches to modelling, which will be done in §2.3.1 shortly below.
Operator, or engineering, models also provide predictions, particularly about human performance and mental workload; and hence possible errors, and suggested task allocation between human and computer. For reasons given above (§2.1.4), no discussion of these models is given here.
As has been explained above (§2.1.6), these models form a separate category, which is recognised here, but will not be discussed. From the user's point of view, the purpose of these models is to aid understanding and using the system, while at the same time the trainer is treating them as something to be communicated, to assist the training process by supporting “direct and simple inference of the exact steps required to operate the device” [67]. The form of these models is an issue to be dealt with by theoretical and empirical study within the discipline of the psychology of learning, which is outside the present study.
The review here is not intended to be exhaustively comprehensive. Rather, the object is to review major exponents of the different approaches to mental modelling. In this section are covered:
The research detailed here corresponds to the class of formalisable models (§2.1.3) and also to those models that have the purpose of being tools for prediction and control.
Clearly, these authors are attempting to construct a formalism that fits with the structure of human cognition. If these formalisms were to provide the basis for a cognitive task analysis, it would be on the grounds that the analysis is in similar terms to the analysis which we might presume is done in the human who is performing the task.
The analysis given by Card, Moran & Newell [20] is based around a model of task performance, referred to as GOMS, which stands for Goals, Operators, Methods and Selection rules. The Goals are those that the user is presumed to have in mind when doing the task—the authors see no need for argument here, since the user's presumed goals seem obviously reasonable. The Operators are at the opposite end of the analysis from the Goals: they are the elementary acts which the user performs (not to be confused with the human ‘operator’ who controls a process). The Methods are the established means of achieving a Goal in terms of subgoals or elementary Operators. When there is more than one possible Method for the achievement of a certain Goal, a Selection rule is brought into play to choose between them. The acts are assumed to be sequential, and the authors explicitly rule out consideration of the possibilities of parallelism in actions. They also see the control structure in their model as a deliberate approximation, being more restricted in scope than the production system of Newell & Simon [91].
What is considered elementary for the purposes of the analysis is to some extent arbitrary. The authors give examples of different analyses of the same text-editing system using different classes of elements: possible elementary units range from the course grain of taking each editing task as an Operator, to the fine grain of the keystroke as the Operator. At each level, the times to perform each elementary unit operation should lie generally within a certain band [83]. For the course grain, this would be at least several seconds; for the fine grain keystroke units it would be a fraction of a second.
By calculating times for each Operator, from experiment, and allowing time necessary for mental workings, we could, in principle, use the GOMS model to make a prediction about the time necessary for a user to perform any particular task, for instance a benchmark task to be compared between different systems. Thus we could have a prediction of the relative practical speeds of various systems. The success of the predictions would depend on the validity of the simplifying assumptions for the studied task, including the choice of level or grain of analysis.
The area of application chosen for developing GOMS was text editing (see the quotation given above, §2.1.3). It could be that much of what they say, and the approximations they use, are appropriate to text editing but not to quite different kinds of task such as riding a bicycle on one hand, and controlling a complex chemical works on the other. It is difficult to imagine a GOMS analysis of bicycle riding. We could imagine Goals without too much difficulty: at the highest level, to get from A to B, and at an intermediate level, for example, to stay upright while travelling in a straight line. At the lowest level, comparable to the grain of keystrokes, the Operators may be to turn the handlebars left or right; but what could the Methods be to connect those Goals and Operators? For the different example of a complex plant, any procedures that one could explicitly teach a human operator could probably be expressed in the form of GOMS. But it is a well known fact [100] that humans do not reach full competence by formal instruction alone. After substantial experience, they develop what is known as ‘process feel’, which is often considered as beyond the reach of usual methods of analysis. How could this be represented in the GOMS model? And how would GOMS represent the many exceptions, anomalous states, emergency procedures, and unenvisaged states of the system? To be fair to the authors, they do not suggest that GOMS would be a suitable model for these various control tasks. However, it is possible to cast doubt even on the GOMS analysis of text editing. This will be done below, §2.6.1.
The GOMS model in general is a scientist's model, but a particular GOMS model of a task would be the analyst's model. It is not so clear, however, exactly what GOMS is trying to model. It is not intended to be an accurate model of the user's mental processes. Rather, it is an idealised model, which falls somewhere between a putative model of the user's mental processes and a model of the analyst's, or designer's, understanding of the task. Thus we can see that GOMS does not fit into the Norman/Streitz analysis (owner and object, § 2.2.1) very easily. But analysis in terms of purpose is much clearer: the function of the GOMS approach is to enable designers or analysts to produce models, the purpose of which is to provide the designer with comparisons of the performance of systems which have, at least in outline, been designed. It is limited in its accuracy by the simplifying assumptions which have been made, which also limit its applicability.
The KLM, although often referred to separately, is a simplified special case of the GOMS family, namely an analysis with keystrokes as Operators. Card, Moran & Newell introduce it as a practical design tool (as opposed to GOMS in general?), to predict the time that an expert would take on a certain task, if performed without error, given: a task; the command language; parameters for the user's motor skill and the system's response; and the method. This means that the KLM does not predict the method—it has no Selection rules; and it only predicts execution time, not time spent in task acquisition. As they point out, task acquisition time is highly variable, depending on the type of task. For text editing, they assume 2–3 seconds, but for creative writing, it could be a many orders of magnitude longer. (In the case of Ph. D. students, perhaps the most convenient unit in which to measure task acquisition time would be months, so the KLM would not be much use in predicting the time to write a thesis.) The treatment of mental operations is even simpler in the KLM than it is in GOMS. An average of 1.35 seconds of thinking time is allowed in various places, decided on by ‘heuristic’ rules-of-thumb.
As with GOMS, the KLM deals with error-free operation. The explanation of errors is an important goal in the modelling of the control of complex systems.
It should be clear from this discussion that the KLM is suited to relatively routine tasks involving interaction with a computer system via a keyboard, and it is not suited to the analysis and design of the HCI aspect of the supervisory control of complex dynamic systems.
This is a development by Moran based on ideas in the GOMS model [83]. Moran recognises that the model that a designer has when designing a system will determine the one that the user will have to learn, and therefore it would be a good idea if the designer had a clear and consistent model in mind when designing. The purpose of Moran's CLG formalism is to ensure that the designer has a framework round which to design. The design is done (generally) on four levels: the Task Level, the Semantic Level, the Syntactic Level, and the Interaction Level. Moran gives guidelines, and an example (a simple mail system), for how to do this.
Moran identifies three important views of CLG. The linguistic view is that CLG articulates the structure of command language systems, and generates possible languages. This explains the G of CLG. It may be that the linguistic view is of most interest to HCI researchers and theorists.
In the psychological view, CLG models the user's knowledge of a system. This assumes that the user's knowledge is layered in the same way as CLG. Moran suggests ways of testing whether a CLG is like a user's knowledge, but he does not give ways of testing the detailed structure of the knowledge, nor whether the representation is the same in both user and CLG. He has a clear idea that it is the designer's model that should be able to be assimilated by the user, hence the designer should be careful to make, and present, a clear and coherent model. But concentrating on this idea neglects discussion of the real possibility that users may develop their own independent models of a system, which may not be describable in the same formalism. We might fairly say that viewed psychologically, CLG makes another speculative attempt to introduce a theory explanatory of aspects of human cognition. It is hard to identify any success in this endeavour above that which is achieved by other psychological theories, and other models mentioned in the study in hand.
In the design view, CLG helps the designer to generate and evaluate alternative designs, but does not claim to constitute a complete design methodology. It could aid the generation of designs by giving an ordered structure to the detailed design tasks, and Moran suggests that CLG could provide measures for comparing designs, addressing efficiency, optimality, memory load, errors and learning.
Sharratt [122, 123] describes an experiment in which CLG was used by a number of postgraduates to design a transport timetabling system. The study shows the wide variation in designs produced, and although it was not the object of the study, this shows that CLG does not effectively guide a designer to any standard optimal design. Sharratt evaluated the designs with three metrics, for complexity, optimality and error, which metrics were developed from Moran's own suggestions. Sharratt also gives ideas on extending CLG to help with its use in an iterative design process. Sharratt notes difficulties with the use of CLG, and if such difficulties arise even in areas of design such as an interactive mail system or a transport scheduling system, we have all the less reason for supposing that CLG could substantially help with the design of decision aids for complex systems.
We may raise one further question, on top of those already asked by Moran himself and by Sharratt. That is, do we know whether Moran's level structure is correct? Is this the right way to go about dividing the specification? In the absence of any arguments, we must say that we do not know. It may well be that there are other possible ways of analysing a system into different levels, and a different system of levels would give rise to possibly quite different analyses or designs. The most important point to be made here, however, is that it is presumptuous to suppose that the levels given here actually correspond in all or most cases with similar levels in human representations. We can imagine, or perhaps some have experience of, design based on other characterisations of level. Would designers all feel that one particular level model is natural and all the others artificial? So as far as the psychological view goes, we have to say no more than that CLG gives a guess at a possible level framework for human knowledge about a system, and that this guess has no more empirical support than alternative ones.
It may be that there is some definite and constant basis for human cognition in the context of interactive systems, in which case we need to find it and make it the basis of the models of the user's knowledge that underlie HCI tools. If there is no such basis, we would need to find a more flexible approach to modelling and to design than is offered by CLG, or similar techniques.
The stated aim of Kieras & Polson's Cognitive Complexity Theory [66, 12] is to provide a framework for modelling the complexity of a system from the point of view of the user, out of which should come measures able to predict the ‘usability’ of that system. We may speculate that if this were effective and efficient, it would be potentially useful to the systems designer, by providing comparisons between different possible designs. But it is not intended to provide performance predictions directly, in the way that GOMS and the KLM can.
The achievement of this aim is via the provision of two formalisms, intended to interact with each other: one for representing the user's knowledge of how to operate the device (the “job–task representation”), and another for representing the device itself, in the form of a generalized transition network. The first formalism allows a designer to create a model of a user's understanding of a task in context. The second is a representation of the system from a technical point of view.
The formalism for the user's job–task representation is based on the concept of the production system (as in [91]). Although the authors cite GOMS as the precursor to their work, they do not follow GOMS in deliberately simplifying the full production system formalism, which is a general purpose architecture of great power. It may well be that the production system architecture is sufficiently powerful to simulate human cognitive capability in many fields (the aim of some AI research), but to model cognitive complexity for many purposes (such as modelling errors) there needs to be a correspondence between the model execution and the ways in which humans make use of their knowledge (a process model). They do not give any clear argument supporting the inherent suitability of the production system for modelling the appropriate aspects of the user's knowledge, nor do they offer any restrictions which bring it more in line with the capabilities of the human. They consider it sufficient justification to refer to other research which has used, or reviewed the use of, production system models.
Because there are no inherent restrictions in using a production system, and because of the potential variability of human ways of performing a task, formalising task knowledge in this way seems to be closer to an exercise in ingenuity (with relatively arbitrary results) than a means of faithfully reproducing actual human thought processes. Hence the doubt about whether the computed values of cognitive complexity bear any necessary relationship to the actual difficulties experienced by users.
These authors also chose text processing as a field of study. Although the task of writing is very complex, text processing (i.e., conversion of words in the mind to words on the machine) does not take very long to learn, and does not afford a great deal of variability in the strategies that one can adopt. One can imagine a text processor with a very limited repertoire, where an extensive logical structure is a necessary consequence of the structure of the computer program running the text processor. In this case, it is also easy to imagine a full analysis of error-free text processing skill, that would not vary between different people. Hence it would be plausible to put forward a production system account of the skill. But even if a production system account is valid for such a well-defined task, we cannot extrapolate this validity to complex tasks such as industrial process control.
The idea of a grammar model of a task is that it is possible to represent tasks, or complex commands, in terms of the basic underlying actions necessary to perform those tasks, and this can be done in a way that parallels the building up of sentences from words, or the building up of programs from elementary commands in a programming language. Grammars which describe the structure of programming languages have often been formalised in Backus-Naur Form (BNF), which is a relatively straightforward formalism.
When a grammatical model has been made of a ‘language’, two measures are of interest: the total number of rules in the grammar is some measure of complexity of the language, and therefore potentially related to the difficulty of learning it; and the number of rules employed in the construction (or analysis) of a particular statement, command, or whatever, is a measure of the difficulty of executing that command, and therefore potentially related to the difficulty of comprehending it.
Green, Schiele & Payne [45] argue convincingly that representing task languages in terms of BNF (as in [108]) must miss something of human comprehension, because in many cases the measures of complexity in BNF do not tally with experimentally derived or intuitive human ideas of complexity. Payne & Green's Task-Action Grammars [96] set out to provide a formalism in terms of which simple measures correspond more closely with actual psychological complexity.
The formalism is a scientist's model of a possible way
in which people might represent tasks.
An instantiation of the model would presumably be a designer's, or
analyst's, model of how a typical user would structure a task internally.
The designer makes this model by considering important
abstract ‘features’ of the task (i.e., dimensions
or attributes on which there are distinct differences
between commands), which are assumed to be apparent to a user,
and then formalising the task language to take account of those features,
by enabling rules to be written in terms of the features,
as well as in terms of instantiated feature values.
The simplest example of this that Payne & Green
give concerns cursor movement.
Instead of having to have independent rules for moving a cursor
forwards or backwards by different amounts, TAG allows the rule
Task[Direction, Unit] → symbol[Direction] + letter[Unit]
provided that the available actions support such a generalisation.
An important point made by these authors is that the consistency
that allows such schematic rules makes command languages easier
to understand and learn, compared to languages whose inconsistency
does not allow the formation of such general rules.
Reisner [109] has recently pointed out that Payne & Green's notion of consistency is not as straightforward as perhaps they would like. There is usually room for various views of consistency, and what matters in system design is whether or not the designer and the user share the same view of consistency. Only then will a task's consistency make learning easier.
This is a point to which empirical data would be relevant, in that if it could be shown that a large majority of users shared one particular view of consistency in a particular task, then designers should design to it and analysts analyse in terms of it. But Payne & Green themselves admit a lack of such data on perceived task structure (perceived by users or operators, that is), and therefore the way in which a task is formalised is up to the judgement of the analyst. Here again we have the problem that the formalism is of such a power as to permit varying solutions. How are we to know whether a particular formalisation is the one that most closely corresponds to a practical human view of the task? Only, it would seem, by experiment, and that would make it impossible to use TAG with any confidence for a system that had not at least had a prototype built.
An alternative view would be that there is some ideal view of consistency, in which the grammar would represent the task in the most compact form. (Compactness is also a guiding principle in many machine learning studies. See, for example, Muggleton [87].) Users could then be encouraged to adopt this view. The difficulty for this idealist notion is that there is no general method of proving that any particular formalisation is the most compact possible. Payne has accepted this as a valid critique of TAG [personal communication].
It is to be expected, as for other formalisms, that for inherently well-structured tasks, the representation is fairly self-evident, and therefore a guess at an appropriate formalisation may well be near enough to get reasonable results. But as previously, there is plenty of room to doubt whether using this method in modelling the control of complex, dynamic systems could be helpful to the systems designer.
No doubt it is already clear that formalisms such as those described above may work reasonably in the analysis of simpler systems, and for systems where the tasks have no latitude for variability. Currently there are no generally known examples of such analysis being performed on a complex system. We may perhaps take this as an indication that the formalisms reviewed are not well suited to the analysis of complex systems, but we cannot be certain about this until either someone does perform one of these analyses of a complex system, or a substantially different type of analysis is shown to be superior for complex systems.
The next grouping of literature corresponds to the more general mental models of §2.1.5, and in terms of purpose, to those models intended to aid understanding. In this group, there are theories and models of human cognition, which specify the units and structure of supposed human cognitive methods and resources. This could be characterised as the analysis of (internal) cognitive tasks, which does not, of itself, specify how to analyse and map external tasks into these internal units, but obviously asks to be complemented by such a mapping.
Providing a model cognitive architecture does not in itself present a technique for cognitive task analysis, because there are other necessary aspects of a mental model. But if one wishes to perform such an analysis, a cognitive model will define the terms in which the task has to be analysed. A useful model here would be one which dealt with the aspects of cognition most relevant to interacting with complex systems.
The first ‘framework’ architecture to consider is the MHP of Card, Moran & Newell [20]. This is not closely related to GOMS or the KLM, despite appearing in the same book. ehe authors attempt to bring together many results from cognitive psychology which they see as relevant to HCI design. The mind is seen as being made up of memories and processors, which have parameters for (memory) storage capacity, decay time and code type, and (processor) cycle time. They give estimates for general values of these parameters. Thrown in with these values are a number of other general principles (e.g., Fitts's Law, and the power law of practice). Taken together, what these parameters tell us is clearly more relevant to short-term simple tasks (and laboratory experiments) than to longer-term subtler cognitive abilities involving problem-solving or decision-making.
Card, Moran & Newell give several examples of the kind of question which could be answered with the help of the MHP. The questions mostly are about how quickly things can be done (reading, pushing buttons or keys, etc.) in different circumstances. There are no examples of applying the MHP to problem-solving or decision-making.
What the MHP does in terms of task analysis is essentially to set bounds on what is feasible for a human to do (cognitively). Thus a matching analysis would have to show what items were in what memories at what different times, and to take account of the times required for motor actions. What the MHP does not do is to set a limit on depth or complexity of information processing, nor to other values which may be of interest in analysing complex control tasks.
The PUMs idea described by Young, Green & Simon [151] potentially takes the modelling of cognitive processes much further, though its implementation is still thought to be several years in the future. That idea is to represent the user of a system by a program, interacting with another program that represents the system. The purpose of a PUM is to benefit a designer in two ways: firstly, by making the designer think rigorously about how the system requires the user to interact; secondly, if such a program were ever constructed, by enabling predictions of users' competence and performance on a given system in the same kind of way as other analytical methods, but with improved accuracy because of the closer matching of mental processes by PUMs than by simpler formalisms.
What language would the program be written in? How would knowledge be represented and manipulated in that language? They give no definitive answers. The cited paper and a paper on a related concept by Runciman & Hammond [117] suggest progress towards answers by considering fundamental facts about human cognition: e.g., that working memory is limited (so you can't just reference global variables from anywhere at any time), and that there is no default sequential flow of control in humans, as there is in many programming languages.
Because there is not yet any explicitly decided architecture for PUMs, it is easier to imagine the approach being used in the course of design, rather than analysis. But the potential is there to provide a detailed language and knowledge structure which would constrain the analysis of a task more closely and helpfully than the MHP. In the meanwhile, using the PUMs concept in analysis could be a way of testing the plausibility of hypotheses about the mechanisms of task-related cognition: one could attempt to fit a task into the constraints selected, and if the performance was similar to that of a human, that could be said to corroborate those constraints.
The concern with implementing a system which represents the main features of human cognition is shared by a number of people not directly concerned with HCI, on the borderlines of AI and psychology. Young, Green & Simon cite SOAR [72] as the closest in flavour to their desired representation of the human processor: both they and Runciman & Hammond also mention Anderson (ACT*) [5] and others. Some difficulties with these for modelling in HCI will be discussed below.
Anderson's ACT* [5] is a much more specific implemented architecture that aims to model human cognition generally. It deals with three kinds of cognitive units: temporal strings; spatial images; and abstract propositions. Anderson does not discuss in detail the cognitive processes that convert sensory experience into these units.
There are three distinct forms of memory dealing with cognitive units: working memory, which stores directly accessible knowledge temporarily; declarative memory, which is the long-term store of facts, in the form of a tangled hierarchy of cognitive units; and production memory, which represents procedural knowledge in the form of condition–action pairs.
Factual learning is said to be a process of copying cognitive units from working memory to declarative memory. This is seen as quite a different process from procedural learning, which happens much more slowly, because of the danger of very major changes in cognitive processes, which may be produced by the addition of just one production rule.
Procedural learning is the construction of new productions, which then compete for being used on the same terms as the established productions. ACT* allows procedural learning only as a result of performing a skill. First, general instructions are followed (using established general purpose productions), then those instructions are compiled into new productions, which are then tuned by further experience in use. Compilation happens through two mechanisms: first a string of productions is composed into a single production (a mechanism called “composition”); then this composite production is proceduralised by building in the information which had previously been retrieved from declarative memory.
Anderson illustrates the operation of learning by ACT* simulating the acquisition of early language, specifically syntax. Many assumptions are made for this purpose, including the assumption that words and parts of words (morphemes) are known and recognised. More important, the meaning of complete utterances is assumed to be understood.
From this brief description, we may see that ACT* is designed to emulate human learning, among other things. However, it is very difficult to see how, for the kind of complex systems that we are considering, ACT*'s mechanism for procedural learning could work. Where would the initial ‘general’ productions come from, which would be needed to guide the initial experience?
The question of whether ACT* serves to guide a task analysis in a useful cognitive way is a separate question. Since the knowledge which results in action in ACT* is implemented in a production system, it would make sense to analyse tasks in terms of production rules, and there is no reason to suppose this is a difficulty, since this is the formalism adopted by Kieras & Polson [66]. The problem is not that production rules are difficult to create, but rather that it is possible in general to analyse a task in terms of production rules in many widely differing ways—just as it is in general possible to find many algorithms to solve a particular problem. The ACT* model does not help to focus an approach to analysis, but rather leaves this aspect of the analysis open. ACT* does not seem to pose the right questions, or offer useful guidance, for the practical problem of analysing a task in terms that are specifically matched to actual human cognition.
SOAR [72] is a general-purpose architecture that is less directly concerned with modelling human cognition than ACT*. SOAR cannot create representations, or interact with the external task environment. While it may well be another promising model of the ideal performance of a single task, what it cannot do includes some of the crucial aspects of the operator in either an active learning situation, or (which is similar) an unfamiliar emergency, not well-remembered or encountered before.
What both SOAR and ACT* need, to complement them in providing guidance for task analysis, is (at least) a way of finding those production rules which best represent a particular human approach to a particular task. Analysing a task in terms of goals and rule structures is not a strong enough constraint to specify a method of cognitive task analysis.
Barnard [9] gives a theory of cognitive resources which he claims is applicable to human-computer interaction. He wishes to deal explicitly with the various different representations of information and the different models that are appropriate in different circumstances, and with the interaction between those models.
His theory, “Interacting Cognitive Subsystems” (ICS), postulates a model of cognition as a number of cognitive subsystems joined by a general data network. In his main diagram of the architecture, Barnard gives two sensory subsystems, acoustic and visual; four representational subsystems, morphonolexical, propositional, implicational and object; and two effector subsystems, articulatory and limb. Each subsystem has its own record structure, and methods for copying records both within the subsystem and across to other subsystems.
ICS is used to explain a number of features of cognition and experimental results, particularly concerning novice users of a computer system engaging in dialogue via the keyboard. Barnard's intention is that the ICS model should provide the basis for describing principles of the operation of the human information processing system that could be tested empirically for generality. If general principles were indeed found in this way, we would both have gained knowledge applicable to the field of HCI, and would have demonstrated the usefulness of the ICS model.
Barnard clearly states that his approach starts with the assumption that “perception, cognition and action can usefully be analysed in terms of well-defined and discrete information processing modules”. What is not entirely clear is whether Barnard is committed to the particular subsystems that he mentions in this paper. One could certainly imagine a similar model based on different subsystems, or subsystems interacting in a different way. Moreover, it is highly plausible to suppose that individuals use different representational systems in different ways. Investigating the statistical features of experimental results on a number of subjects together, in the way that Barnard reports, is not designed to show up any differences between individuals in this respect.
The concept of interacting cognitive subsystems is not dependent on a particular theory about any of the relationships between the subsystems. Indeed, Barnard gives few indications about how information is changed from one representation to another. For example, how is iconic visual information converted to propositional form? Interestingly, it could be just this sort of conversion of information from iconic to logical form that plays a crucial rule in many dynamic control skills—particularly controlling vehicles. The acquisition of such a conversion ‘routine’ may be a key aspect of learning the skill.
Another unclear feature of the ICS model concerns the general data network. In computer systems, communication is made possible by agreement on common formats for data transfer and communication: networks can have elaborate standards to define these formats. According to Barnard, it is the individual subsystems that recode information in formats ready for other subsystems. Thus recoding is seen as dependent on the sender, rather than the receiver. This means that the supposed data network has to be able to convey information in any of the constituent representations. How it could possibly do this is not discussed, which is disappointing, considering that it would be a major discussion if the problem were seen in terms of the computer analogy that it invokes.
Barnard regards his theoretical framework as in some respects an enhanced model human information processor of the type proposed by Card, Moran & Newell (see above, §2.3.2.1). But whereas those authors largely report the separate parameters of cognitive abilities, Barnard is making assumptions about the structure of cognition that have not been explicitly verified. The present study does not see ICS as in the same league as GOMS, yet. A judgement on whether his theory is applicable to human-computer interaction in complex systems would have to await an attempted detailed analysis of a practical complex task using his framework.
The models reviewed here are more relevant to well-understood, more straightforward tasks than to complex tasks involving complex systems. Their starting point has generally been within the scope of cognitive psychology, where there is a dominance of experiments designed to discover about particular identified parts of human cognitive capabilities, rather than the way in which these abilities are coordinated to produce skilled control. The models which address the coordination, though very interesting, cannot claim a strong empirical base for the way in which they model coordination itself, however much they may rightly claim to base themselves on empirical research of the individual abilities. The core of the problem seems to be firmly tied to complexity. In §1.3.2 a case is made out for defining complexity in terms of the variety of practical strategies, hence in a complex task one would expect variation over time or between individuals. The methodology for empirically addressing the issues arising from complexity seems not to have been worked out yet in the cognitive science tradition.
This part of the literature corresponds to the models of error-prone human operators, above, §2.1.9, and to the purpose of communication of the modelled concepts. In this literature, there are observations on salient features of human cognition in complex processes, that do not directly relate either to current models of cognition, or to current methods of logical analysis of tasks. Here we find the distinctions between novice and expert styles of reasoning, and Rasmussen's distinctions between skill-, rule- and knowledge-based behaviour [101]. We can see these as offering partial specifications of what a model of human performance of complex tasks should cover.
Many authors have stressed that much human mental activity differs between individuals and between tasks (e.g. [1, 91, 110]). The variety of individual strategies and views of any particular task has been identified by Rasmussen [100], who states that “Human data processes in real-life tasks are extremely situation and person dependent”. This may well have a bearing on the information requirements and priorities, and thus it should be reflected in any comprehensive cognitive task analysis.
We may here make a useful distinction between individual variation in Intelligent Tutoring Systems (ITS), and in complex system control. For ITS, it is not difficult to imagine the production of models of complete and incomplete knowledge of a domain, and expert and ‘buggy’ performance strategies (examples in [128]). In contrast, in complex process control it is much more difficult to define what would comprise ‘complete’ knowledge, and what (if anything) is an optimum strategy for a given task, since, although there is usually much that is defined in procedures manuals, this is never the whole story. Hence, for complex systems, it is implausible to model individual variation as an ‘overlay’ on some supposed perfect model.
In current approaches to cognitive task analysis, variation between individuals is often ignored, and analysis performed only in terms of a normative structure, often justified merely by the observation that it is plausible to analyse the task in this way. But, considering (for example) the reality of complex process control, to ignore differences is highly implausible, since there are apparent obvious differences in the way that, for example, novices and experts perform tasks. Better, surely, if it were possible, to construct a model of each individual's mental processes and information requirements. If this were done, a designer would have the option of designing either a system tailored to the information requirements of an individual, or a system which could adapt to a number of individuals, where the information presented could more closely match their particular strategies, methods, etc.
In any case, it could well be dangerous to specify rigid operating procedures, where there is any possibility of a system state arising that had not been envisaged by the designers, since an operator dependent on rigid procedures might be at a loss to know what to do in the situation where the rule-book was no help. If there are not rigid operating procedures, then operators will find room for individuality, and their information requirements will not be identical. Hence, in complex systems, it would be advantageous to be able to model individuals separately, and hence there is space for the development of models more powerful than current ones.
Rasmussen and various co-workers wished to have a basic model of human information-processing abilities involved in complex process control, including (particularly, nuclear) power plants and chemical process works, in order to provide the basis for the design of decision support systems using advanced information technology techniques. The analysis of many hours of protocols from such control tasks has led to a conceptual framework based around the distinction between skill-based, rule-based, and knowledge-based information processing, which has been introduced above, §1.3.1.
Although Rasmussen presents his stepladder model as a framework for cognitive task analysis, he suggests neither an analytical formalism, such as a grammar, nor any explanation of the framework based on cognitive science. In a later report [103], he does give examples of diagrammatic analysis of a task in terms of his own categories. However, this is neither formalised nor based on any explicit principles.
Clearly, what Rasmussen gives does not amount to a complete cognitive task analysis technique. Writing in the same field, Woods [144] identifies the impediment to systematic provision of decision support to be the lack of an adequate cognitive language of description. In other words, neither Rasmussen nor anyone else provides a method of describing tasks in terms that would enable the inference of cognitive processes, and hence information needs. What Rasmussen does provide is an incentive to produce formalisms and models that take account of the distinctions that he has highlighted. Any new purported model of cognition or cognitive task analysis technique must rise to the challenge of incorporating the skill, rule and knowledge distinction.
Roth & Woods [114] base their suggestions for cognitive task analysis on experience with numerous successful and unsuccessful decision support systems designed for complex system control. They see the central requirements for cognitive task analysis as being firstly, analysing what makes the domain problem hard, i.e., what it is about the problem that demands cognitive ability; and secondly, analysing the ways people organise the task that lead to better or worse performance, or errors. Once the errors have been understood, it should become possible to design a support system to minimise their occurrence.
The study of the central requirements of cognitive task analysis is referred back to Woods & Hollnagel [147]. They recognise three elements basic to problem-solving situations: “the world to be acted on, the agent who acts on the world, and the representation of the world utilized by the problem-solving agent”. Before considering the interrelationship of all three elements, their proposed first step in the analysis is to map the cognitive demands of the domain in question, independently of representation and cognitive agent. This implies that any variation between cognitive agents (people, computers, etc.) will not feature in this first stage of the analysis. We may expect this to capture any necessary logical structure of a task, but this is not the cognitive aspect in the sense related to actual human cognition. The only variation they allow at this stage is between different “technically accurate decompositions” of the domain. For these authors, “determining the state of the system” is an example of this kind of cognitive demand. The difficulty with this mode of analysis is, given the possibility of variant human strategies, and thence representations, that the human description of the ‘state of the system’, and the method for determining it, may indeed vary both with the individual operator, and with the representation that they are currently using.
To try to retreat into technical descriptions at this point is only further to sidestep the cognitive issue, and evade the question of whether there is any cognitive analysis at all that can be done independently of the agent and the representation. A possible reply might be that it is necessary to abstract from the influence of the agent and the representation in order to make progress in task analysis, since these factors are difficult to capture: however this does no more than beg the question of the possibility or ease of finding out about the agent and representation—and that question has not been opened very far, let alone closed.
Inasmuch as some analysis is done without reference to the agent and the representation, we could see this as compromising the cognitive nature of the analysis, taking it further away from a full treatment of cognitive issues, back towards the a priori formalisms of §2.1.3. Woods & others' approach still has some advantage over such formalisms, by taking the operational setting into account, but this trades off against simplicity, and means that their approach is harder to formalise.
In essence, these authors' approach to cognitive task analysis falls short of a detailed methodology, because there is still uncertainty about how the domain problem is to be described in the first place. Of course, for systems which are not especially complex, there may be a certain amount of cognition-independent task analysis based on the logical structure of the task. For more complex tasks, it is difficult to see how cognitive aspects of the task could usefully be analysed without a concurrent analysis of the actual cognitive task structure that the operators work with.
Holland et al. [56] present a detailed account of rule-based mental models, which they see as incorporating advantages from both production systems and connectionist approaches. The mental models of the world are based on what they call quasi-homomorphisms, or q-morphisms for short. In essence, any particular way of categorising the world gives rise to categories which are abstract to some degree, by leaving out some of the detailed properties of real-world objects. For instance, to give an extreme example from their book, we could categorise objects simply into fast-moving and slow-moving. These categories behave in certain more-or-less uniform ways, so that on the whole we can predict the future state of an object by classifying it, and applying a general rule for how that class of objects behaves. Thus, on the whole, fast-moving objects, after a while, become slow-moving. If we then look at the real world at a subsequent time, we might notice that some of the things that we had predicted were wrong: i.e., our categorisation was not sufficient to predict the behaviour of all the objects in which we were interested. For example, wasps, members of the class of fast-moving objects, mostly retain their fast-moving quality over time. This makes the mapping between real world and model a quasi-homomorphism, rather than a plain homomorphism, which a faithful many-to-one mapping of world to model would be. (This also contrasts with an isomorphism, which is a one-to-one mapping.)
If the person with the model is concerned to be able to predict more closely things that happen in the world, they can introduce another categorisation to deal with the exceptions from the first one, and this process can be repeated if necessary. Of course, the categorisations have to be based on detectable differences, but there are no hard-and-fast properties which always serve to classify particular objects. In their example, the further categorisation in terms of size (small/large) and stripiness (uniform/striped) might serve to distinguish wasps from a few other cases of fast objects that do indeed slow down over time. The way that things are classified depends on what the purpose of classification is, and can rely on feature clusters rather than specific predefined features alone.
Their theories are particularly interesting because they extend to giving accounts of the fundamental processes of inference, learning and discovery. This could provide a very powerful model in the long run, because if we can describe the ways in which people learn about complex systems (with any variations in such ways) we would be in a stronger position to model the knowledge that they actually have at any time. Also, having a theory of how knowledge can arise lends credence to the model of knowledge itself, and provides a composite model which is stronger than a model which speculates only on the nature of the knowledge that already exists. We could describe these theories as mental meta-models, since they set out to describe the processes that underlie the creation of mental models in the human.
Moray [85] endorses the work of Holland et al., and gives a different angle on what a process operator knows. He suggests that an operator's model includes an appreciation of the plant as made up from subsystems which are more-or-less independent, and their interactions are known to the operator to an appropriate degree of accuracy. He goes on to suggest that decision aids could well be based on a view of the plant consistent with the operator's model: he says that there are ways of predicting what a likely decomposition of the plant into ‘quasi-independent subsystems’ may look like. Of course, there may at times be a need to look at the state of the plant in more detail than usual, particularly when faults occur or errors have been made. A good decision aid would support presentation of information at the appropriate level of detail.
Moray furthermore claims that there are methods which could automatically discover the plausible subsystems of a complex system. This would mean that cognitive task analysis could proceed by identifying these subsystems, and using them as basic terms in the language describing the task from a cognitive point of view. The same subsystem structure could also be used as the basis for organising the information to be displayed to the operator.
We should note that Moray offers no evidence about the extent to which actual models of operators match up with the methodical analyses. Furthermore, it is not clear to what extent individual operators can or do develop their own models, differing from those of others. It would be surprising, though far from incredible, if a methodical analysis could show up a range of possible subsystem decompositions to match a range of individual models. If these questions are taken as challenges to further work, particularly towards discovering actual human mental models and representations, Moray's suggestions could be forerunners of a task analysis approach that was cognitive without being arbitrary or irremediably intuitive.
These approaches give some substance to hopes that there could be decision aids, and more general systems design methods, based on a much richer picture of mental models. These models could be scientists' models of users' or operators' models of a system, based on more general theoretical models of the users' or operators' cognitive processes.
It is patently obvious that people reason about the world, in a reasonably effective manner for everyday life, without recourse to detailed theory of, for example, physics. Much the same could be said of process operators: they manage to control complex systems by using knowledge which appears not to be equivalent to the engineering knowledge which went into aspects of the design. It seems reasonable to suppose that this knowledge is qualitative, rather than quantitative, and if we knew more about it, we may be able either to design decision aids which interact more effectively with the operator's knowledge, or to apply the principles learned towards the better design of human-machine systems.
The literature on qualitative models and reasoning (e.g. [37, 38, 69]) does not deal with HCI questions. Currently, it attempts to provide a model of the knowledge and reasoning processes which could support the kinds of commonsense reasoning that we know in everyday life.
In modelling commonsense reasoning, this approach implicitly tries to capture some of the underlying common knowledge that we have about the way the world works. This can be seen not as propositions, but as the framework which binds together the factual content in these models. While none of the authors here claim to model more than a fraction of commonsense reasoning, this approach at least offers a start where most others do not begin.
Qualitative modelling is not immediately very useful for the systems designer, since the methodology it provides is open-ended, but it has the advantage that for some of these systems (e.g. Kuipers' QSIM [70, 71]) the time development of the model has been implemented, so that if a researcher or analyst provides a qualitative description of a system, they may get qualitative predictions of the future possible behaviours of the system. Using this to model human reasoning would mean that the model predicts what the human should be able to predict, and thus we could say something about how the human should reason, based on their current knowledge.
But it can be difficult to express the functioning of a system in qualitative terms that lead to sensible predictions. The degree to which these models actually correspond to human thought processes is unknown. Hence this approach does not yet provide a practical means of modelling the operator controlling a complex system. It has, however, been used to model some systems as a preliminary to performing exhaustive analysis of what faults could occur in qualitative terms [97].
We could say that qualitative reasoning models are highly idealised models of people's knowledge and reasoning about systems.
This (see [42]) is an AI approach to describing common-sense reasoning in terms of formal logic. It attempts to capture something of the essence of default reasoning, and therefore could potentially be applied to mental modelling, possibly yielding insight into knowledge and inference structures that people use when controlling complex structures. However, this approach has not been applied yet to HCI issues, and its concentration on formalisms familiar to logicians tends to indicate a lack of concern with modelling human thought processes and structures, beyond a correspondence between the output of the human and of the model.
Here we have a set of considerations that are complementary to those arising from formalisms and models of cognition. Whereas some of the formalisms are well-developed, but not closely relevant to complex tasks, here we have a collection of points that are relevant to complex tasks but not well-developed.
Surprisingly little seems to have been written in detailed direct criticism of current mental modelling and cognitive task analysis approaches. The first paper discussed below gives one way of comparing a number of mental model and cognitive task analysis approaches. The four papers discussed next give the most direct criticisms though they are critical of different things. This is then followed by general criticisms that have a principled nature, somewhat in complement to the direct criticisms that have been offered in situ in the review section above, §2.3.
When a researcher devises a cognitive modelling method, there are bound to be some features that are more important in his or her mind than others. We would expect this to lead to the observed situation in the literature, where different models tackle the problem of modelling human-computer interaction in different ways, and from different viewpoints. In that there is no single ‘best’ model, there are likely to be trade-offs between different features, and for this reason, it makes sense to criticise modelling techniques only from stated viewpoints or with particular purposes.
A paper by Simon [127] gives us an analysis of cognitive models in HCI based on the trade-offs as he sees them. He considers a representative selection of models:

Figure 2.1: The two continuous dimensions of Simon's trade-off space
The diagram that is central to his analysis gives two continuous dimensions (Figure 2.1) and two discrete dimensions, given here with the models that Simon assigns to each category.
The first of the continuous dimensions, placed vertically on his chart, ranges from models dealing with fixed and/or errorless behaviour, with the actual operations not specified, at the top; to dealing with adaptive and/or errorful behaviour, where the actual operations are specified, at the bottom. It is difficult to see how this is a trade-off. The bottom of the diagram seems to be the ideal place to be, and perhaps the trade-off encountered by the authors of models at the top was that it was more difficult to devise a model lower down on the scale. The bottom of the chart is correspondingly bare, with the lowest entry, PUMs (see §2.3.2.2) being at present more of a concept than an elaborated model. Simon obviously sees Barnard's Interacting Cognitive Subsystems model to be in a class of its own, and it is also nearer the bottom of the diagram. But as we discussed above (§2.3.2.4), ICS is not yet in the same league as GOMS and others.
This void at the bottom of the diagram would be filled in properly only by some model that managed successfully to formalise the principles of human cognition that are relevant to HCI. Models that aspire to fill this gap must, among other things, justify why they are relevant.
The second of the continuous dimensions is displayed from left to right on Simon's diagram. When this dimension is seen in terms of knowledge operationalisation, the left is a high representation of knowledge, i.e., the knowledge that users employ is laid out rather than being recast into abstract form (in terms of memory, for example); when this dimension is seen in terms of parameterisation, the right means that there are more explicit parameters governing mental performance, such as decay rates of memories. Perhaps this trade-off is a temporary phenomenon: symbolic representation may be incompatible with parameters only because no parameters have yet been devised for higher-level mental operations.
Indeed, the search for higher-level parameters could be seen as one of the higher-level goals in cognitive research for HCI, in that it would be very helpful for system designers. Perhaps a trade-off analysis would be more successful when the field of HCI is more mature, with more clearly defined issues.
Rips [112] takes issue with some of the models which fit into the category of “more general mental models” in §2.1.5, and which serve the purpose of aiding the understanding of (mostly) psychologists studying cognition. The criticisms are levelled from the point of view of a psychologist or a philosopher, not a systems designer.
Rips suggests that by taking the idea of mental models too literally, some authors end up claiming that models help with questions of semantics and reference; some claim that the idea of ‘working models in the head' helps to explain how people reason about the everyday world; and some claim that people perform everyday logical inferences using mental models rather than internal logical rules.
The important point which Rips makes is that the concept of mental models does not suddenly solve philosophical or psychological problems. If we can be described as possessing mental models, then is it sure that the possession of them does not give us any privileged access to truth about the world, and mental models as explanations have no a priori advantage over other, previously established theories.
Rips acknowledges the usefulness of considering “perceptual representations” as well as symbolic representations, and if that is all that is meant by ‘mental models’ than he is quite happy with it. He also recognises that many writers use the idea of a mental model simply as an explanatory device, without any great ontological implications. The focus of theorising in the mental models fashion should be to explain the phenomena under consideration, rather than to gather support for the existence of theoretical entities; and just because a particular explanatory framework fits certain observations, this should not lead researchers into making assumptions about the status of the theoretical entities that are part of the model.
Lindgaard [73] delivers a brief attack of mixed quality on the idea that mental models can be used by system designers. It is claimed that mental models are of their nature subjective and individual, and that claim, although it contains a lot of truth, ignores the possibility that the common points between individuals' models may be of relevance and interest; and then it is stated baldly that “a good user interface can be designed entirely without reference to mental models”: hence the idea of mental models is “somewhat irrelevant” to system designers.
While it cannot be denied that it is possible to design an interface without explicitly thinking about mental models, one is led to wonder whether the author would also claim that it is possible to design a good interface without considering the information needs of the user, or the possible ways that the user may respond to information presented. These questions are questions about the designer's model of the user, whether explicit or implicit, whether consciously acknowledged or not. As we have seen in previous sections, many approaches to mental models have a bearing on these matters: whether it is by providing formal simplified approximations to the user's behaviour, or by discussing the digested fruits of experience working with operators controlling systems, or just by attempting to elucidate the mental workings behind the person's activities. Mitigating this over-general and sweeping criticism of the present state, Lindgaard implies that more research and development at a theoretical level could bring mental models to a point where they could be used in practice.
Booth [16] offers a much more detailed critique of the usefulness of a more closely defined class of model. In the context of the quest for the best understanding and modelling of the user, he casts doubt on the usefulness of predictive grammars within the design and development process. As an example of a predictive grammar, he focuses on TAG [96], which has been described above (§2.3.1.4). However, grammar models are not the only kind of predictive models that have been produced, and we will here discuss Booth's criticisms with respect to formal methods in general, realising that this may entail us arguing against something that, strictly, Booth does not claim, but in any case it is more relevant to us here than discussing grammar models alone. Since Booth lists eight specific criticisms, let us discuss them one by one.
As mentioned above for GOMS, in all the formal methods, what is taken as an elementary action is to some extent arbitrary. There is no established method for deciding what a human takes as being elementary, which itself may not be a stable quantity. Different grains of analysis would produce different analyses. This indeed means that in any model produced, the grain of analysis may not match that of the user, and so the model is in danger of failing to represent the user's model accurately. It is a commonly acknowledged potential failing of formal methods, that they give no guarantee of accurately representing the user's model [127]. There still remains the question, whether formal methods, using a common formalism for the various systems, may provide a useful comparison of complexity even though this may not be identical with user's true cognitive complexity. The point is that the ordering of complexity may be similar even if the actual measure of complexity differs (consistently) between human and formal analysis. Booth is content to conclude that the grains of the formal model and the human are unlikely to match.
A user or operator brings prior knowledge and experience to a task, along with expectations and patterns of meaning and significance. This could be expected to vary from person to person, and for one individual it could vary across different situations and even across different times for the same situation and person. Booth points out that this means that there is no single definition of consistency for all situations. In terms of TAG, the abstract “features” used to give structure to the task are not fixed. This supports Reisner's critique [109] given above (§2.3.1.4), and also discussed below (§2.6.2).
Whether this is counted as a failing of formal methods depends on one's point of view. It is true that the formal model may not reflect all the varying views on consistency, but there are potential ways of circumventing the difficulties that arise from this. A system designer could propose the incorporation of training attempting to ensure that people shared the same understanding of the features of the task. And even if this was not possible, this would not prevent any variant sets of features from being worked into the formalism, if the analyst could discover what they were.
The next round of questions could include “should people be forced to be consistent with themselves, and with others?” and “how good or bad are various formal models at allowing the description of natural human inconsistency?” Booth does not address these.
Booth argues that human actions are based on that human's specific knowledge, which may be sufficiently different from the background knowledge of the designer or the analyst to prevent reliable prediction of the user's behaviour. He suggests that the actual knowledge used in practice is not practically amenable to formalisation into cognitive grammars. In what can be seen as a related point, Suchman [134] has argued that the situation in which an action occurs is crucial to the interpretation of that action. It is the very independence of formal models from their contexts that persuades both Suchman and Booth of the models' inability to account for action in real life (as opposed to laboratory experiment).
While this may be an argument against current formal methods, advocates of formal methods may regard it as a challenge to extend their formalisms to be able to take into account more background knowledge and context-dependency. It would be very difficult to argue convincingly that formal methods were in principle incapable of this, though it might be seen as unlikely that something as specific as a grammar would have much chance. Moreover, the more routine a situation is, the more the relevant world knowledge is likely to be a known quantity, and hence formalisable. This argument of Booth's looks more like an argument of degree than an argument of principle, liable to progressive erosion as the tendency to incorporate context-dependency and background or real-world knowledge into formal models develops.
Booth points out that an ideal in system design is to find out from the users what they actually want, and thus to involve them in the design process. One might argue that this could happen most easily in the context of iterative design, where every stage acts as a prototype, with feedback from users, for the next stage. If one is committed to this kind of design process, or one wishes to focus on this stage of design refinement, then it makes sense to consider the responses of actual users rather than models, where possible. However, this cannot be the whole story. After all, there is always the question of how the first prototype is designed. The closer this first prototype gets to the desired final result, the more efficient we can expect the design process to be.
One of the points of the formal methods mentioned above was the possibility of avoiding having to use prototypes. There may be reasons why user involvement is impractical, undesirable, or even impossible, whether for reasons of time and money or otherwise. It would be these situations where we would expect formal techniques to come into their own.
The essence of this criticism is that design does not in practice proceed by means of construction of a number of fully-fledged and specified designs, to be tested against each other competitively. Formal methods appear to assume that this is the context for their use, since their main claim to usefulness is to provide the capability of comparative evaluation.
This is quite probably a valid criticism. But this does not prevent the possible usefulness of formal methods, particularly in cases where for some reason comparative evaluation is wanted, for example if there is no experience of a certain kind of design being preferred for a certain system. In this or other ways, formal method studies could still inform design decisions, even if they are not carried out in most instances of design.
Here Booth makes the point, that in the early stages of design, the assumptions being made about the system may not remain valid as the details are worked out, and as changes of approach are made to circumvent newly discovered difficulties. This calls into question the usefulness of formal studies based on unreliable assumptions.
However, it is also possible to envisage formal methods playing a part in that very process of revising one's assumptions. Assessment by a formal method could reveal an unenvisaged area of unacceptable complexity, which could prompt the designer to turn the design towards more reasonable options.
It would appear that designers find current formal methods daunting, and Booth doubts whether even the originators of formal methods could use them to describe real complex systems.
Possible solutions to this could either involve the education of designers, so that they were familiar with and competent in the methods, or better formal methods, which are easier to use. None of this would be to any avail however, unless the concerns of designers are actually addressed by the formal methods. It is possible that influencing designer's concerns (or maybe those of their management) might help formal methods to gain acceptance and use.
This criticism compounds the previous one: current formal methods do not offer evaluation of all areas of concern, therefore a designer would have to learn more than one, with all the resultant effort to master a number of methods that are already seen to be too complex individually.
The validity of this criticism depends on whether or not one identifiable method by itself can provide useful results. It may be that for many design problems, one method (possibly different in different cases) may be able to do the needed evaluation, because there may be one issue in the design which is salient, and obviously more important than the others. None of the authors studied here would claim that formal methods provide a complete paradigm for system design, which has to be followed the whole way, though they differ in the degree to which they see formal methods as helping or guiding the process of design.
Taking in the spirit of all of Booth's criticisms, one could retort that it may well be that there are aspects of systems design which could be helped by formal methods in some circumstances. Fancifully, we could see Booth as providing us with an armoury for a joust against formal modellers, complete with suggestions as to how the weapons might be used; but Booth does not see it as his business to force the model knight off his white charger, out of his armour, and back into scholar's rags. In the course of this fray, I have suggested that there will be a second round, after both contestants have been unhorsed, thrashing out the possible lesser claims of formal models.
This is not to argue that current methods are actually substantially and practically helpful. It is just that the questions have not been argued in conclusive ways. There are further general arguments given below (§2.4.6–§2.4.9), intended to strengthen the case against the adequacy of current formal methods in the modelling of complex dynamic systems.
Bellotti [11] gives reasons, gathered from studying real design projects, why designers do not use what she calls “HCI design and evaluation techniques” (which include GOMS and TAG). This is directly a criticism of current design practice, and only indirectly a criticism of the modelling techniques themselves. The main reasons discovered are that there are unavoidable constraints (as well as some avoidable ones) inherent in the commercial systems design environment, which mean that current HCI techniques are not appropriate. Bellotti suggests that future design and evaluation techniques should bear in mind these constraints in their development. One might suggest, even, that HCI authors should take a little of their own medicine by considering the usability of their proposals. She gives the following as a summary of constraints.
From this analysis it would seem that mental models have a long way to go before they are of such evident use that designers not only learn about them, but also are prepared to put in the effort needed to overcome the current constraints imposed on them by their environment.
As is obvious, and has been pointed out in several places above, people often do things in different ways. Similarly, it is not surprising that there are usually many ways, in principle, to construct a model which does the same overall task, i.e., produces the same overall output from the same overall input. Because many tasks which humans perform are difficult to emulate by computer, the focus of some AI research has been simply to get any one emulation running effectively, that being a major achievement.
But if we are content with a model only of the overall performance, we may fail to model many aspects of human performance, because we cannot know to what extent such an overall model works in detail like a human until we have specifically tested its similarity. It is particularly important in the study of control of complex systems to know about errors and their origins; and to be able to predict human errors, a model must faithfully simulate not only the overall input and output of the human operator, but also all the separate intermediate processes that are liable to error. Rasmussen [101] makes it clear that for his purposes, a model must not only be shown to work, but its points of failure must be investigated before we can be said to know how good that model is. In modelling the human operator, a model is more successful the closer its errors correspond with errors of the human.
Despite these observations, some authors seem to have fallen for the temptation of assuming that just because their model works, producing the right output in a plausible way, that there is no need for further discussion of its suitability for modelling human cognition. For example, Woods & Roth [148, p.40] are satisfied with a model that provides a “psychologically plausible effective procedure”. The trouble is that, if one has sufficient imagination, there may be many plausible effective models, which may differ radically from one another. They cannot all be equally good as models of the human.
As mentioned above (§2.3.1.2), the CLG model [83] assumes that analysis in terms of certain ‘levels’ reflects the structure of human knowledge. Presumably Moran does this because it is plausible (to him) and it produces in the right kind of results. There is no obvious justification why his levels should be the only right ones, nor does he give any reason for supposing that they are.
Authors using production systems in the execution of their models generally do not justify the appropriateness of production systems for modelling human mental processes. A notable exception is Anderson [5] who is concerned with the realism of his model in describing the mechanisms of human cognition and accounting for many different experimental observations from human cognitive psychology. All this shows, however, is that a production system is adequate or sufficient, not that it is necessary nor that it is the best way of modelling cognition. Anderson describes other production systems which are far less well matched to the realities of the human. And there is no reason to suppose that the same insights could not be captured through the use of some quite different formalism, suitably restricted, for example first-order logic, or the kind of language envisaged in the PUMs study [151].
When authors fail to discuss the appropriateness of their modelling formalism or program for representing actual human mental processes, one can only assume that either they do not think it is important (an odd view, considering the obvious nature of the remarks above), or that they have failed to notice and question a tacit assumption, that there is only one way in which an intelligent system can do the task that they are investigating. The same tacit assumption seems to be in play when failing to consider possible variation between individual humans.
It may be that some of the perceived difficulties with mental models, as well as their lack of generality, stem from their lack of theoretical rigour. It is easy to see how a lack of theoretical foundation could pose problems. As remarked above, there is often plenty of room for doubt about how well a model matches the relevant characteristics of what is being modelled. In the absence of theoretical argument, the problem of validating a system is merely moved, rather than solved, onto a problem of validating a mental modelling or task analysis technique.
One may at first suppose that a particular technique could be validated, after which it could be taken as reliable: the trouble is that there is no theory to suggest what range of other applications are sufficiently similar to the validated one to benefit from the validating exercise. For example, suppose that we had shown the validity of the TAG model for a range of word processors. Could we rely on its results for another new kind of word processor? for a speech-driven text system? for an intelligent photocopier? for a business decision aid? The problem is not just that the answers might be “no”. It is also that there is no sound basis for judging. It is not therefore surprising that available mental model techniques are not reckoned to be very good value.
Essentially, models not based on firm foundations of theory are less useful to systems design than they might be because they make little impression on the problem of validation.
It may be that formal methods work best on systems simple enough that the formalism can be applied without much ambiguity or room for choice. As much has been suggested above (§2.3.1), with reference to text editors. The tasks for which we use text editors are uncontroversial, in that when we have made up our mind exactly what to change, the editing process has a result which is clearly specified, even if (as is usual) there is more than one way of performing such a task.
We may imagine a system, perhaps many years in the future, which interacts by means of voice and touch screen, so that the author of a document could edit it with no more effort than it would take to tell someone else what to change. There would no longer need to be a task of text editing (as in the studies discussed above) distinct from the author's task of marking revisions.
We might speculate that the same end may befall many tasks that are easily formalisable, leaving humans in the long term with jobs that call for such things as judgement, insight, intuition, or whatever can only be formalised by making many arbitrary assumptions: for example, deciding what changes to make in a document. Formal methods have up to now not been applied to such tasks, so it is reasonable to suppose that those methods as we see them now would be unreliable on such tasks. Easily analysable tasks, on the other hand, should yield to automation or redefinition sooner or later. There need to be developments in the methodologies of formal analysis to deal somehow with this range of choice and individuality, before they could be applied to systems where there is room for human choice: both choice between methods of the performance of tasks, and choice between methods of application of the formalism to the analysis of the system.
Many authors remark on the dissimilarity between the performance of the learner and of the expert; and between their supposed respective mental models. Expertise comes with practice and experience. But in any complex system, the expert is only practiced at the range of systems or states that are encountered frequently. When that range is exceeded they are no longer experts by virtue of knowing what to do, from experience, in a particular situation. If anything, their expertise is then based on the relevant aspects of their mental model of the plant and process, and consists of some kind of problem-solving ability. In Rasmussen's terms, the mental processing moves to the knowledge-based level, and here operators may not have much advantage over others whose knowledge of the plant does not come from the experience of operation. Working at the knowledge-based level is usual for people learning to operate a system, so any information system should be prepared to treat the operator more like a learner at the appropriate times; and this is important because these situations are often the ones in which accidents occur. Differences between individuals have a bearing here, in that different operators may develop different areas of particular skill, and these differences need to be taken into account if we are to be able to model their expertise accurately, in the kind of way necessary if we are to model their proneness to errors, or know anything about the variation between their individual information requirements.
Rasmussen's ‘stepladder’ model of mental processes [101] (above, §1.3.1) is one attempt to characterise this issue. But there are no current attempts to make a formalisable or predictive model that captures the same insights.
A number of authors have expressed what they think would make a good mental model, though for obvious reasons they cannot say exactly how this would be achieved, or indeed whether it is in principle possible.
Green, Schiele & Payne [45] give six tentative criteria (here abbreviated) that they think a formalisable model should meet in order to be directly applicable by systems designers.
Models that would be currently appropriate, according to Hollnagel [57], would be those that describe intentions, goals, plans, strategies and the human ways of thinking about these.
Sheridan & Hennessy [125] suggest both qualitative and quantitative models of the various parts of the human-machine system, which would then give to the systems designer the goal of harmonising these various models.
In giving these desiderata, these authors either state or imply that no model currently comes up to all of these standards at once, and also they imply that they do not see any model coming up to those standards in the near future. This points towards the need to develop theories, that are currently still in the realm of speculative psychology, into formal implemented models; to broaden current formal theories to take into account more of the realities of human cognition; and to package them into a form that matches the needs of their users, the designers.
A model of a human operator which could be combined with a task description, and from that predict what information the operator would need, at what time, would make the task of the designer much easier. For whereas in the simplest systems it is possible to present all relevant information all the time, in a complex system this is not practical, and thus the designer needs to know about the operator's information needs. In order for the designer to know how to prioritise information for the operator, the model of the operator needs to tell the designer much about the presumed mental processes in progress in the operator. Such a model would at least have to cover the operator's representations both of the task, and of the tools by which he or she is going to perform that task; and the operator's ways of combining together and processing that information.
Needs are perhaps only the converse of desires, but the points that can be made about the general deficiencies in mental models differ somewhat from the desiderata.
Woods [145] states that the problem in designing decision support systems is “the lack of an adequate language to describe cognitive activities in particular domains”. The formalisms reviewed above are too idealised for this task, as they rely on unsubstantiated assumptions. In the opinion of Hollnagel & Woods [59], “practically every attempt to make a formal description of a part of human activity” fails to recognise that one cannot formalise human activity on the same basis as the logical models of the physical world.
The models of cognition are off target, dealing with cognition at the wrong level. Suchman [134, p.178] characterises the research strategy in cognitive science as first representing mental constructs, then stipulating the procedures by which those constructs might determine action: this is seen as relying on an explicit enumeration of the conditions under which certain actions are appropriate. Suchman wishes to “explore the relation of knowledge and action to the particular circumstances in which knowing an acting invariably occur.” Suchman goes on to say that the way each person interprets and uses particular circumstances depends on the particular situation. Her views tally with the recognition that skilled behaviour does not have the explicit nature of problem-solving tasks, such as the involvement of detailed stable plans. The AI view of planning is also regarded as inadequate for characterising human cognition in HCI by Young & Simon [152]. They suggest an approach based on partial, rather than complete, plans.
The literature seems to be saying that neither formal nor more general mental models are able to deal with the particularities of real complex tasks. Further, if we are to model an operator in a situation where there are a number of concurrent tasks, this would obviously compound the modelling problem with the need to model the tasks separately, and it may also introduce the added need to model the way in which the operator allocates attention and effort between the various tasks. All this underlines what may be regarded as the central message from the literature, that there are currently no experimentally derived and tested models of human performance in complex control tasks.
The problem we are left with, having reviewed a selection of the current literature, is two-edged. On one side (§2.3.3), there is the literature concerned with communicating important insights into the mental processes that go on in complex control. The concepts here (such as the skill, rule, and knowledge distinction) make good sense intuitively, and it is easy to see their importance and relevance to the subject. However, it is not clear from the literature whether these concepts could be formalised, and if so, how. This requires moving towards more formalism, attempting to detail how these general concepts are realised in individual humans.
On the other side (§2.3.1), there are the formal task analysis and modelling techniques, from which can be built up structures that are plausible as models of human cognition, but fail to connect with the concepts that are seen as central to the realities of process control. Here we need to move towards right structure, by finding out how to formalise the concepts that we are really interested in. Thus both sides are seeking to answer the questions, what concepts, or mental structures and processes, do humans actually use in these complex tasks? How do humans represent systems and tasks internally? The goal of both sides is to enable the building of predictive models which are also relevant.
But if this is a representation problem, it is not closely related to the way in which representation is treated in many studies, particularly some of those from Artificial Intelligence. There, the problem is more usually how to represent the structure and interrelationship of concepts that are given—they are already part of human knowledge explicitly. Amarel [4], for example, discusses different ways of representing the ‘missionaries and cannibals’ puzzle, while Korf [68] discusses the Tower of Hanoi and other problems. The present study, in contrast, is looking for concepts that are not already explicitly known or defined. The human ability to create new concepts to structure an area of knowledge or experience has not been well analysed or explained in the literature reviewed.
How is it that formalisms alone do not solve the representation problem? We have already noted above (§2.3.1.4) how in TAG [96] the way the analysis is done relies on the intuition of the analyst to select features that have psychological validity. Payne & Green fear that there is nothing analysts can do to ensure that ideal of psychological validity, rather than being bound by his or her own intuitive preconceptions about the task. The present study would agree that nothing a priori can be done to check the validity of a representation, but that experimental evidence may be able to bear on this, in a way not anticipated by Payne & Green.
The difficulties may be even easier to see with GOMS. Card, Moran & Newell [20, p.224–5] give a GOMS analysis of the use of a text-editing system, BRAVO. We shall consider this here in more detail than above, §2.3.1.1.
There is a single overall ‘Goal’, to edit the document. Whether this is the only goal might have an effect on the way in which the task is done: if the user was interested in the content of the document, or particularly hurried or at leisure, one could imagine differences in performance. But let us for the moment ignore these factors. At the other end, that of ‘Operators’, clearly, the system that is being used ultimately defines a set of actions that can be performed with it. This would be unequivocal at the level of the keystroke.
It is the intermediate levels where most room for doubt exists. This is the realm of the ‘Method’, and for each method given in their analysis, one is tempted to ask, are there any other ways of doing this? Because the domain is a relatively straightforward one, the answer will often be that there are no sensible alternatives. For example, for the goal “Acquire-unit-task”, “Read-task-in-ms-method”, which is simply to “Get-from-manuscript” seems reasonable enough. But then, how about unmarked spelling errors that are seen in passing? Maybe one is prohibited from dealing with these, if it is a restricted enough working environment.
But how about the goal “Select-target”? The “Zero-in-method” given for this seems rather contrived. The problem is not in the way in which it is written out, but in the content. The method implies a series of approximate targets, which are pointed to on the way to finding the actual target (the goal “Point-to-Target”). One is left with the feeling that perhaps what is given is plausible, but is it possible to specify the method to that extent, without alternatives? What are these “approximate” targets?
Even if one was happy with the way a particular method was specified, there is the question of alternatives. For the goal “Point-to-Target” there are five methods quoted. How would one know whether this list was complete? One possible approach, avoiding the need to specify, is to say that if another method is found, it would be included, and selection rules added. This may be a model of the way people refine their task performance, but it does not help us to model the behaviour of an operator who has already achieved a refined skill, much of which is beyond the level of conscious expression.
One should be careful to distinguish questions of method, which are questions about the representation of actions, from questions about selection rules (for which there are again five for the goal “Point-to-Target”). Simply changing a parameter in a selection rule does not alter the representation language needed for the complete analysis, but introducing selection on the basis of a new criterion would be changing the representation, i.e., it would be altering how the situation would have to be perceived by the user to use those selection rules.
In essence, what is uncertain in the GOMS methodology is to what extent the structure of methods and selection rules matches any particular user's internal representation of both situations and actions. Neither Card, Moran & Newell, nor Payne & Green, nor any other authors of formalisable models, give ways of deriving this intermediate structure from analysis of the actions of the users themselves. But if a way to do this was found, much of the uncertainty of their analyses could be eliminated, and researchers could profitably debate what formalism was the most apt for codifying the representational language and structure of users.
The point about formal methods can be focused a different way by looking at how formalisation relates to consistency, amplifying the point made by Booth, discussed above (§2.4.4). Reisner [108] was searching for “a single, consistent, psychological” formalisation in which to describe human task performance, although she noted that it was not clear how to define consistency and inconsistency. Payne & Green [96] carried further the aim “to capture the notion of regularity or consistency. Consistency is difficult to define, and therefore difficult to measure, but is informally recognised to be a major determinant of learnability.” If there were one favoured way of formalising a task, which somehow maximised consistency, then that would define a good representation for that task, and formal modellers would be able to produce logically equivalent formalisms to capture this.
A recent paper by Grudin, “The case against user interface consistency” [47], strongly suggests that formal ideas of consistency, springing from a priori analysis rather than patterns of use in the work environment, are bad guides for systems design. He illustrates the point by considering the “household interface design problem” of where to keep knives. The ‘consistent’ approach, of keeping them all together, conflicts with the common sense approach based on usage, in which we keep most of our dinner knives together, perhaps, but not together with the putty knife (which is in the garage) or the Swiss army knife (with the camping equipment). The scope for analogy with computer systems is clear. Applying this to analyses, if we are guided by formal consistency, we may miss the common-sense human representations of tasks or problems, which are used only because they have been found to work in practice, rather than in theory.
What can we then say about consistency? Reisner [109] takes up all these points, focusing the question onto the issue of partitioning the universe into classes. “There is more than one way to partition the universe”, she states, because “semantic features are (probably) context dependent.” The important issue in systems design can then be seen clearly to be, not any a priori consistency, but whether the way the system designer partitions the world is sufficiently similar to the way the user partitions the world. If it is not, then inevitably the user will mis-classify things (according to the designer), which could lead to mistaken expectations, or actions whose effects are other than intended. It is perhaps a related point made by Halasz & Moran [50], in the paper, “Analogy considered harmful”. We could see analogy bringing in a way of partitioning part of the world, based on a successful way of partitioning a different part, to help with a new task: but this is unlikely to match exactly, and it is very likely to lead to problems if the learner extends the analogical representation beyond where it fits. They judge that an abstract, conceptual model is preferable to an analogical one, for training.
The chief point in this discussion is that, in general, since humans have no standard of consistent representation, formalisms cannot capture ‘it’. This is equally true of analysis, and of making models of human performance, as of design.
There are no generally known formal analyses of complex task performance: what literature there is discusses the question in a more general way. Woods [146] identifies the problems of interface design, and support system design, with the problem of representation design. He does not mean by this the details of exactly how information is displayed (e.g., its visual appearance), but rather the structure of the information, in the sense of the mapping between basic measurements and the entities that are to be displayed.
Woods makes a number of useful points about this aspect of representation in HCI. The context determines what is vital information, and this can be seen as a ‘context sensitivity problem’. Simply making information available, according to some supposedly logical scheme, can invite problems, in cases where an operator cannot simultaneously keep track of all possibly relevant information. The challenge, in designing interfaces or support systems, is to structure the information so that the operator can most easily use it, by ensuring that the structure of the information matches as well as possible the structure of the actual task as done by the operator (not some idealised laboratory or prototype version of the task performed by the designer). The HCI challenge amounts to fitting the presentation of information to the operator's representation (which we can think of as an aspect of their mental model). Woods goes on to give more ideas about general ways that information can be integrated, computationally or analogically, in order to suit supposed requirements of some kind of general user, but he gives no leads on the question of distinguishing the needs of different users or classes of user.
In process control tasks, with a very large number of measurements available, it is tempting to think of the problem of representation as selecting relevant facts from a single, supposedly complete, set; whereas the choice of representation is a wider issue, including the possibility of higher-level concepts that are not measured directly, and covering the choice of ways of describing the whole situation. Any calculation of the number of possible representations of a complex situation (the size of representation space) gives an extremely large number—so large that it is very difficult to imagine any established general method being able to produce worthwhile results.
To illustrate this, let us suppose that we wished to control some complex process, and we were given some rules in the form of condition–action pairs. If we consider all the concepts or terms present in the rules, that defines the representation necessary for the use of those rules. For instance, we may be given a set of rules in terms of raw gauge readings. For these, we would have to know which gauge was which, and how to read them. Rules in this form might be long-winded and cumbersome. Alternatively, we may have some rules framed in terms of higher-level concepts. In this case, before we could operate the system effectively, we would have to learn how to tell what facts were true about these higher-level concepts. So a representation is like a mapping or a function (but in general, a program) which takes the raw, uninterpreted real world (about which we can say nothing without interpreting it), and delivers facts, in the first case (low-level) such as “valve A is open”, “the pressure is B”, “the speed is C”; and in the second case (higher-level) such as “system P is unstable”, “Q is dangerously hot”, “R and S are on a collision course”. To reiterate, the representation is the connection between the real world (before it has been described in any formalism) and the terms used in—the language of—the facts and rules relevant to the task.
From this discussion of representation, it should be clearer both why it would be useful to study the actual representations that humans have (e.g. of complex systems), and what the object of that study would be. In essence, deciding how operator support systems should present information to the human, without having firm knowledge about human representations, is shooting in the dark.
We have eschewed detailed consideration of training and learning, on the grounds that the models there are used in a different way for a different purpose (§2.1.6). But it may be helpful at this point to imagine the way in which representations that people have of tasks and systems relate both to the stages of learning a task, and to Rasmussen's distinction between skills, rules, and knowledge. This is meant as an imaginative aid to help focus on what these internal mental representations might be.
At the initial stages of learning a new task, we can imagine a trainee working with general-purpose problem-solving representations, or with representations based on analogy or metaphor, and working at an explicit, knowledge-based level. He or she would be selecting and starting to shape a representation suitable for the new task: in particular, the overall structure of the system and the task, and the meaning of the terms used by others to describe it.
At an intermediate stage of learning, a representation of the system and task would be being refined, combining lower-level into higher-level concepts, and building up compound actions out of elementary ones. We can imagine rules being learnt, rules that are made up from the representational primitives that have been identified. This process could then iterate, if the rules found were not able to support an adequate level of performance, by refining or altering the representation. This would start off at the conscious level, and progressively become more automated.
At the final stages of learning a skill, we can imagine the faculties having become so attuned to the task that much of the learning would be at a subconscious level. There would be continuing refinement of representation, but at this level, the operator would not be able consciously to express how the representation was being refined. The grosser structure of the representation could have stabilised, giving more chance for experimental study, while the parts that were being further refined could be the lowest-level parameters of the representation.
It seems reasonable to suppose that a human, or other intelligent system, would do well to have many different representations of the world, suitable for different circumstances. Because facts and rules are based on the representational system, we would expect to see facts and rules being learnt and used in a context where there was also a well-defined (even if not verbally expressible) representation. Analogy may be an exception, with the representation from one domain being used to provide initial structure for the learning of informational knowledge in another domain [56, 65].
The review of literature repeatedly revealed what seemed like a lacuna, blocking the way to integrating formalisms and theories with vital practical considerations and observations about the realities of complex tasks. This focused around the question of representation, and it was not at all clear from the literature how to proceed, if not all the way to bridging the gap, at least to surveying and laying some of the necessary foundations for the bridgework.
The studies reported in this chapter were not done as a consequence of the literature findings, but rather served to complement them. These studies were not only investigations of their own branches of literature, revealing similar problems to the main literature, in different contexts. They were also investigations into the practical aspects of the subjects, revealing practical as well as theoretical difficulties.
As such, these studies were very important in beginning to define areas of experimental research which might be more fruitful than others.
Collision avoidance between merchant ships at sea was originally chosen, by those who instigated the research, as an exemplar area of study, for many good reasons. Some of these reasons will be explained in this section. Because it is a good representative task, it also shows the problems of representation clearly, and these will be discussed next. Collision avoidance is described here in some detail in order to get an appreciation of the kind of problems faced when attempting to study a real-life, complex task. These considerations are a significant part of the whole work, despite the fact that there were too many problems standing in the way of research directly on the subject. These obstacles are also described here.
Collision avoidance is a good example of the kind of system, and task, described in the introduction (§1.2). Ships come into view, either visually or on radar, at unplanned times, and have to be dealt with in real-time, no matter what else is happening. Ships are expensive, and a great deal of effort is put into allocating blame for collisions, so that the cost of damages can be apportioned as fairly as possible. A nautical disaster can cost many lives. There can be a large amount of information to be dealt with, though the task can also be uneventful for long stretches. The amount of information that needs to be dealt with depends firstly on what the situation is: in the middle of the ocean, not much happens, whereas in busy shipping lanes near the coast, there are more vessels to keep a look-out for, and more work with the chart keeping a track of the ship's position. The amount of information that needs to be dealt with depends secondly on the kind of ship and the number of people on duty at once. The historical trend is for fewer people and more automation, away from the style of operation associated with navies [60], towards the ‘one man bridge’, where the automatic systems have interfaces within the control of the ‘conning officer’.
Relating to the categories of §1.3, collision avoidance is clearly a dynamic control task, rather than a problem-solving task. Let us take the question of complexity firstly in terms of Woods' categories [145], §1.3.2 above. There is dynamism, though the time constants involved are of the order of minutes rather than seconds—a property shared with nuclear power plants and other process industries. The task can have strong interconnections, particularly when more than one ship presents a potential threat, but also because the different tasks that make up watchkeeping impinge on each other. There is uncertainty, in that it is never certain what actions other ships will take. And there is risk: this is not only the risk of collision (and grounding), but sometimes also the commercial risk of missing deadlines. So collision avoidance would count as fairly complex according to Woods, though perhaps not as complex as nuclear power plant control.
Collision avoidance also has a clear involvement of regulations (the collision regulations [61]), and multiple tasks. Observation of cadets in a high-fidelity night-time training simulator showed, perhaps even more clearly than observing experienced mariners would have done, how there were different elements to the task. (The author spent a week observing cadets in the ship simulator at Glasgow College of Nautical Studies.) As well as giving orders for desired heading, engine speed, and occasionally rudder angle, the watchkeeping officer has to take at least supervisory responsibility for maintenance of the chart and log; for lookout, both visually and by radar (which often involves calculations on the radar screen); for communication with other vessels, pilots and port authorities (including responding to distress calls); for looking after the cargo; and for managing the other people involved in the control and maintenance of the ship, including making sure that people are awake, doing what they should be doing, organising relief or time off vital duties, etc. This kind of human multi-tasking is common in the kind of complex tasks that we are considering in this study.
The present author's definition of complexity (§1.3.2) is in terms of the variety of possible strategies, and by implication (now that we have discussed representation) the variety of possible representations of the task. This is particularly interesting for collision avoidance, as this variety can be approached in more than one documented way.
Around 1970 a number of articles appeared in the Journal of the Royal Institute of Navigation concerned with a possible revision of the collision regulations (see, e.g., the discussion, [116]). Much of the writing focused around the question of whether the existing basis of the rules was satisfactory. The existing rules are based around the concept of right-of-way. In most situations involving the risk of collision, they say that one vessel has to give way, and the other vessel has to ‘stand on’ (i.e., maintain course and speed), to avoid the possibility that any action taken by the stand-on vessel might counteract an action by the give-way vessel. The alternative is to have a system whereby both vessels are expected to manoeuvre, but in such a specified way that their actions add to each other's effect, rather than cancelling it. Cockcroft [25] gives the diagram of manoeuvres that was generally favoured at that time. This discussion establishes the point that opinions differ about the best strategy to adopt as a general rule, and about the concepts that would underlie that strategy.
Although Curtis [29] did not set out to show differences between individuals, his simulator experiments show a great deal of variation between the actions of different individuals presented with an identical experimental arrangement. Since his object was to determine reaction times, Curtis did not publish the reasons the mariners gave for their actions, but he reproduces in diagrammatic form the tracks followed by the 30 individuals. These are remarkably varied. Looking at the diagrams, it is difficult to believe that the mariners were all following the same strategy.
At both Liverpool Polytechnic and Plymouth Polytechnic, there was recent work on collision avoidance advice systems. In making a system capable of giving reliable advice, the task has to be given an explicit logical structure, and the obvious way to do this is on the basis of rules. To make rules, one has to have a representation language that provides the primitives in terms of which the rules will be written. Investigating some finer points of these proposed systems gives some insight into the problems with representing the collision avoidance task.
This takes input from an advanced radar system, in the form of headings and speeds of ships detected by the radar. These raw data are then interpreted into categories that are used and understandable by mariners, and of the type also used in the Collision Regulations, such as “crossing from starboard to port, passing ahead”. In the Liverpool system, there are 32 valid combinations of this kind of descriptor, and five other descriptors dealing with other information relevant to the collision regulations and the likely inferences of an officer of the watch. 14 possible collision avoidance actions are identified, the last of which is a default category of “emergency” when none of the other 13 actions are appropriate. The derivation of the best appropriate collision avoidance action from the descriptors is governed by rules and procedures internal to the advice system. The rules were derived from expert mariners, who did not always agree, while the procedures to find the solution consisted largely of orderings and heuristics to guide the search for a reasonable solution, avoiding the necessity of trying out every possible manoeuvre with every target. After generating a likely action, that action is tested against all the targets, to ensure that no advice given could lead to a collision or near collision.
Liverpool's system is geared to providing advice to the officer on the bridge, and the complete calculation is reworked every 15 seconds. If advice has been given, but not taken, it may become appropriate to offer different advice. This is what is done.
The system represents consensus opinions on reasonable actions to take in the situations as described. However, a number of questions may be raised about the representation used. Firstly, the descriptors chosen were derived from the Collision Regulations, plus a consensus of mariners. If the regulations changed, this would be likely to invalidate the descriptors, not just the rules: this might be acceptable on the basis that everyone should be working within the same regulations. But what if certain mariners had other descriptors that they used, consciously or not, in their collision avoidance strategy? This would imply that the Liverpool system might give advice that was inconsistent according to some mariners' views. The research issue here would be to establish that mariner's descriptors were fully covered by the system's descriptors. Secondly, some mariners might characterise the range of actions available to them differently from the system. Again, the research called for here would be to investigate the actual range of actions that are used, and to ensure that all actions taken by mariners are given in the system. However, this would still be a problem, in that the system might give advice to a mariner to take an action that is not within that mariner's normal repertoire.
The possible use of situation descriptors other than the ones recognised by the system raises a yet more troublesome point: what if some of the descriptors used by mariners are not available to a system electronically? The lights that a target vessel shows are an obvious example. But more worrying still, how about the feeling that a watchkeeping officer gets, that the crew of a certain vessel are not going to comply with the rules?
Another problem for advice systems of this kind comes from the varying usefulness of such a system in situations where the user has different amounts of experience. Among collision avoidance situations, some occur more frequently than others. Generally, it would be reasonable to expect that in the more commonly occurring situations, there would be more knowledge and opinion available in the nautical community about good ways of responding to such situations. Equally, any particular mariner is more likely to have a worked-out strategy for dealing with these cases. These are the cases where the advice system will be at its most reliable, but also the cases where it will least be needed. On the other hand, in situations that occur only infrequently, watchkeeping officers are likely to still be at the learning stage, trying out different possible actions, and learning from experience. Following advice from the system would at least work most of the time, although this will not allow an officer to learn from different possible approaches, and develop a personal style. But it is in just the least familiar situations that the system gives up, leaving the mariner with an ‘emergency’ that is at best ill prepared for, and even less prepared for if, due to the availability of the advice system, a personal strategy has not been developed.
Research at Plymouth has had automation more in mind, and perhaps for this reason the published paper has different priorities from Liverpool's publications, and does not describe the decision process in detail. The principles of the system design are clearly similar, with a rule-based approach being used. However, even at this relatively early stage of development, it can be seen that the representation used is not identical to that used by Liverpool. For example, they use different ways of calculating the time at which an avoidance manoeuvre should take place. This reflects debate in the Journal of Navigation about what criteria to use for modelling mariners taking avoiding action (e.g. [30]). As we consider levels of detail finer than given in the publications, it would be even more likely that differences would emerge, simply because of the difficulty of unambiguously describing a correct approach to the collision avoidance task.
An authority has suggested that ship's masters often feel the need to imprint their own personality on the job, and that all certificated officers took pride in their ability to “interpret a situation”, and that the heuristic knowledge gained from experience “is more valuable to them than their slavish knowledge of the Collision Regulations” [48]. This reinforces the idea that different watchkeeping officers have different personal styles, and therefore probably different representations of the task.
There is also hearsay about the usage of modern electronic aids to navigation. It is thought that there are ships where the officers do not know enough about their radar equipment to make proper use of it. This applies particularly to the more modern equipment such as ARPA (Automatic Radar Plotting Aid), which provides the facility to predict, and display graphically, where vessels will be at a future time, assuming they hold their course and speed. In many collisions in fog, there is a suspicion that at least one of the parties was not using their equipment properly [19, p.163]. On the other hand, some channel ferry operators are thought [48] to base their (very effective) collision avoidance strategies around a modern electronic aid that shows danger areas to be avoided round other ships (the Sperry PAD system).
It would seem that strategies, and representations, are built up in the context of what information is available, and people may not be very good at adjusting their old strategy, built up over many years, on the introduction of new equipment.
Despite the wealth of interest in a study of maritime collision avoidance, there were obstacles preventing its direct study. The first of these was the inability to secure machine-readable data.
Real ships would be the ideal place to secure data on collision avoidance. However, they do not have automatic recorders, such as the ‘black box’ devices on aircraft that are analysed after crashes, etc. To install such a device on an operational ship would be technically very complex, and it is doubtful whether ship owners would be happy having their radar equipment interfered with, and doubtful whether watchkeeping officers would be happy having all their actions recorded.
Despite the fact that nautical simulators are driven by computer, it is difficult to get machine-readable data from them. The computer architecture tends to be specialised, with little or no provision for data links to other systems conforming to any standard. Only one such link in Britain was known to the author, at the College of Maritime Studies, Warsash. This connection has been used in the study of collision avoidance behaviour [49], but the simulator is heavily used in routine training, and not readily available to outsiders for extensive experiments.
Even if the problems with data were solved, there would be still further problems in using lifelike maritime collision avoidance as an object of study.
The multi-task nature of collision avoidance has been described above, §3.1.1. In current simulator training (as observed by the author), the tasks that do not normally have a mechanical or electronic interface are simulated by having a very skilled simulator operator, who takes on the role of all the agents not immediately present, such as the engineers, pilots, port authorities, other ships, etc. In training simulators, with cadets, the other unformalised aspect of the task is the interaction of the officer of the watch with the other people on the ship's bridge. To include all this information, or to leave it out, both have problems. Including it would mean recording by hand and formalising data that it is not clear how to formalise. A realistic situation would result, but the complexity of this full realism would make the task more complex, and lengthy to learn. Lifelike collision avoidance involves long stretches of time at the task, and this too would cause problems for experimentation. It is not easy to formalise the time relationships of events which either have long-term consequences or need long-term planning (of the order of hours). On the other hand, leaving out this kind of information would make the task unrealistically easy, perhaps so easy that there would be little complexity to the task, and a logical analysis would suffice. That would mean that it would be an unsuitable object of study here. A one-man bridge simulator would be another alternative, eliminating the social side of the task, but such simulators are not widespread, and none was known that would be available.
This difficulty in simulating the collision avoidance task could be traced back to the question of whether collision avoidance actually constitutes a separate task of navigation. Clearly one can think of it as a separate aspect of the task, but perhaps it only acquires its particular character in the context of the wider task of navigation. Although it is quite easy to set up exercises on collision avoidance in ship simulators, it is notable that there are in general no such separate exercises in the use of ship simulators for routine training. If one cannot helpfully think of collision avoidance as a separate task, then analysis of it would only make sense if one analysed the task of navigation as a whole, which, as has been pointed out above (§3.1.1), has many aspects, and some of those aspects might frustrate attempts at formalisation and modelling (discussed below, §8.2.1).
In the attempt to study human control of complex systems, studying collision avoidance in a realistic situation was a direct approach: but since that proved to have too many difficulties, a more roundabout approach was worthy of consideration, going via studying the control of a simpler dynamic system. The idea would be to start off modelling how people perform a task that is relatively easy to specify, and then gradually to extend the model to cover the control of more and more complex systems, until one is able to model realistic complex tasks. The realisation that there are no successful models even of human skills acquired in childhood, such as bicycle-riding, suggests that the approach via simpler skills is at least challenging.

Figure 3.1: The pole and cart, or inverted pendulum
One of the simplest dynamic control problems to be studied is that of the inverted pendulum, or pole-and-cart system (see Figure 3.1). In this system, a rigid pole is connected by a hinge at its base, to a cart which is constrained to move along a linear horizontal track. A force is applied to this cart: if appropriate forces are applied in a timely fashion, the pole can be kept from falling over, and the cart kept from wandering too far away from its starting position. Typical values used in the simulation are:
The problem of balancing a pole using a continuously variable force can be solved by straightforward control engineering techniques. If the problem is simply to keep the pole from falling over (without any idea of optimality) there are many possible detailed solutions: within control engineering; from other theoretical standpoints; and by unformalised human skill. Some of the solutions studied here use, instead of a continuously variable force, a force of constant magnitude, which can be changed only between two states: pointing one way, or pointing the other. This is referred to as ‘bang-bang’ control. For an early introduction to the control theory side, see Eastwood's paper [34].
In some ways, the task of pole-balancing is at the opposite end of the spectrum to collision avoidance. As we have discussed above, collision avoidance has much complexity, and consequently there are problems in research methodology. A real pole-and-cart system may have relatively few problems, depending on the details of the physical system: in an idealised version, simulated on a computer, there are no unknown influences on the system. If machine learning is being studied, and no humans are involved, the research methodology is relatively straightforward.
In amongst the early literature on controlling the pole-and-cart system, there are mentions of involving humans, and possibly learning a skill from a combination of human input and machine learning techniques. The objects of this section are to examine this literature, considering how it reflects on the issue of representation, and to consider the implications for the study of complex human control tasks.
Donaldson [31] uses the pole-and-cart apparatus essentially as described above, to demonstrate a technique of learning which he terms “error decorrelation”. This is an early suggestion of a way in which one might learn from a human how to perform some skill. The task in this case is to give as output a suitable value for the force to be applied to the cart. This output is constructed by taking a number of measured system variables (which we can think of as defining the ‘situation’) and multiplying these by a set of coefficients. If there is more than one output variable, the same arrangement would be be replicated. The system learns from example: that is, an ‘expert’ output is given from some other source, and the learning mechanism attempts to adjust the coefficients so that it matches the expert output as closely as possible. If the expert control signal correlates at all with any of the measured variables, the response of the learning system will become closer to the expert output.
We see here the dependency of learning on an adequate representation of the system. If the expert signal is not correlated to something that is measured, Donaldson's learning process will fail to learn.
Eastwood [34] makes the point that in order to construct a control engineering solution to a problem it is necessary to “identify as many as possible of the contributory variables and to express their interrelationships in terms of mathematical models which can be simulated on the computer”. Using control theory, he derives a method of controlling the pole-and-cart system that we have described above. Eastwood gives results in the form of graphs plotting the behaviour of simulated, and real, pole-and-cart systems. For the idealised simulation, the control, and recovery from disturbances, is very quick, efficient and smooth. Applying the same control to a real pole and cart, the resultant motion is more erratic, though still well controlled. No mathematical model of a real system can ever be perfect, and the results from the real system illustrate the effect of the imperfections in modelling.
Human control of such a system differs in appearance from the control engineering solution. In pole-balancing, human physical control is not based on explicit mathematical analysis, and hence it does not suffer from the need to have detailed mechanical descriptions of things before being able to control them. For systems that are able to be thoroughly analysed, human control is liable to be less accurate, smooth, or efficient than theoretically-based control, but for systems that have not been thoroughly analysed, humans are still able to learn control where theoretical solutions are not yet possible.
Control theory is rooted in continuous algebra, and is quantitative rather than qualitative. Using qualitative control techniques [24] results in a response that at least superficially appears to be more like human control and less like that based on control engineering. So it seems reasonable to assume that the investigation of qualitative techniques would lead us closer to an understanding of human control.
An early qualitative approach to pole-balancing is given by Widrow & Smith [141]. Their approach has some similarities to that of Donaldson, but is based on a discrete, rather than continuous, representation of the problem. They also introduce ‘bang-bang’ control, in keeping with their qualitative approach. However, they are much more concerned with demonstrating that their system can learn something, than with the relationship between this and human skill. This paper is one of the prototypes of the research which is now termed ‘connectionist’ or to do with ‘neural nets’.
Michie & Chambers [80] take a much more explicit approach to learning to control the pole-and-cart system, and the learning is not from an expert, but purely from the experience of failure, which in human terms is a much harder learning problem. Their basic strategy is to divide up the state space of the problem into ‘boxes’ (hence the algorithm name), which are defined by thresholds—particular values of each dimension of the state space. One can imagine the boxes as box-shaped regions of state space.
‘In’ each box, a separate learning process is going on. The data which is passed to each box includes what time, or how many moves, elapsed between that box's decision and ultimate failure. So, by a process whose details do not concern us here, each box learns what is the best decision to take. When each box has learned a good decision, the decisions of all the boxes put together constitute a strategy for the task as a whole.
Fundamentally important to the ability to learn well is the selection of the state space dimensions, and the choice of thresholds to divide the state space up into boxes. Each box is a region of state space that is treated as uniform for the purposes of the learning algorithm. If a box includes regions where a good strategy would recommend different actions, then this may compromise the ability of BOXES to learn any effective strategy at all. Attempting to avoid this problem by having very many very small boxes leads to long computation times, and strategies which are even less homogeneous and comprehensible.
Given the importance of the choice of dimensions and thresholds, one would expect the authors to discuss it in detail. In fact, they accept the problem dimensions as they would be defined by engineers, without comment. One could at least say that the dimensions given (x, x dot, theta and theta dot) are able to describe any possible state of the idealised system. Of the thresholds, they say very little. It seems as though the values were derived by a process of trial and error, guided by human intuition, and therefore difficult to document. The choice of dimensions and thresholds is clearly a problem area, and this corresponds to our problem of representation, as already discussed.
Chambers & Michie [22] discuss possible human-machine cooperation on the task of learning to balance the pole-and-cart. It must be pointed out that their objective was not to replicate a human skill by using machine learning, but rather to short-cut the process of learning, which in Michie & Chambers is entirely by experience of failure.
Chambers & Michie envisage three kinds of cooperative learning. The first is where the BOXES algorithm just accepts the decisions from the human, without effecting any decisions itself. The second is where there is provision for the human not to give a decision, and to leave it up to the algorithm, so that the decision-making would be shared. In the third case, some criterion would govern whether the algorithm had enough confidence in its decision to override any decision that the human might take.
The authors point out that BOXES can complement a human by providing consistency where a human might be inconsistent. However, whether this is an advantage depends on whether the representation is a good one. If the thresholds are badly placed, or the dimensions wrong, ‘inconsistency’ within a bad box may be the optimal strategy, and in this case BOXES would be reducing appropriate ‘requisite variety’ that the human had. On the other hand, if we knew what dimensions and thresholds were used by the human, then enforcing consistency might well improve performance, and BOXES would be truly cooperating with the human. There is, however, no discussion in this paper about what a human representation might be, or how to discover one.
More recent work on the pole-and-cart system adds little to the originals, from the point of view of the present study. Makarovic [75] derives qualitative control rules by consideration of the physical dynamics, together with many simplifying assumptions. Bratko [17] derives control rules from qualitative modelling. Sammut [118] extends the original BOXES work by performing rule-induction on the decisions generated by BOXES rules, to get a humanly comprehensible and concise set of rules not unlike Makarovic's. Between the time of consideration and the time of writing, researchers at the Turing Institute have done some work on the human control of a pole-and-cart system [79]. They do not derive any new representations for human control.
Little work has been done on the human side of pole-balancing. No empirical tests of representations have been made, to assess how closely they correspond to human representations. No-one has claimed to have discovered a specifically human representation of pole-balancing.
Makarovic's rules [75] are in fact for a double pole system, where a second pole is hinged to the top of the lower pole. For the sake of simplicity, we here give the form of the rule for balancing one pole, which comes from assuming that the top pole is perfectly balanced at all times. The notation is also simplified to accord with that already introduced.
IF theta dot = big positive THEN Push Left
IF theta dot = big negative THEN Push Right
IF theta dot = small
THEN IF theta = big positive THEN Push Left
IF theta = big negative THEN Push Right
IF theta = small
THEN IF x dot = big positive THEN Push Right
IF x dot = big negative THEN Push Left
IF x dot = small
THEN IF x = positive THEN Push Right
IF x = negative THEN Push Left
The “big positive”, “big negative” and “small” values are exclusive exhaustive qualitative ranges.
Although this rule is given in terms of the four basic physical quantities, its derivation used the idea of desired reference values for the quantities, justified in terms of control concepts. The present author also used this kind of approach, but justified in terms of human understandability, in devising an alternative representation for the pole-and-cart system. This was attempting both to enable a physical pole-and-cart apparatus (functioning at the time in the Turing Institute) to balance for longer than was being achieved by other means, and also to try out a representation that had more human flavour to it. The principle of this representation is to calculate desired values of the various quantities, and to represent explicitly the deviations of the actual values from the desired values, which would in turn affect the desired values of other quantities.
In the pole-balancing task, we may fix a particular position on the track as the place where we wish the cart to be. The difference between the actual position and this desired position—the distance discrepancy—determines what we wish the velocity to be. The connection between distance discrepancy and desired velocity may be done in two ways: either quantitatively, for example by making the desired velocity a negative factor times the distance discrepancy; or qualitatively, by dividing up the range of distance discrepancies into a small number of sub-ranges, and for each of these sub-ranges, assigning a particular value to the desired velocity. We may continue in the same fashion, qualitative or quantitative. Comparing the desired velocity of the cart to the actual velocity, we obtain a velocity discrepancy, and a desired acceleration of the cart can be fixed as a simple function of the velocity discrepancy. The desired acceleration may then be converted directly into a desired pole angle, based on the fact that the pole would be in unstable equilibrium at a particular angle, depending on the acceleration of the cart. Comparing the desired angle with the actual angle can give us a desired angular velocity, analogously with position and speed. Finally, comparing the desired angular velocity with the actual, we can derive a control decision, whether to apply the force to the right or to the left.
Implementing this strategy requires the setting of the functions which derive a desired value from a previously measured discrepancy. In practice, all except the last function were linear relationships, with constants that had the nature of time constants in exponential decay. It was discovered, by intuitively-led trial and error, that good results were obtained by setting what was effectively a short time constant for the last part of the decision (going from the angular velocity to the force), with progressively longer time constants, the longest governing the connection between discrepant position and desired velocity. This strategy was tried on a simulated pole-and-cart, producing control with apparently no time limit. The quantitative version led to an apparently static system on the graphic display, while the qualitative version led to small oscillations around the desired position. The quantitative version, suitably adapted to the physical apparatus, produced runs balancing for longer than had been achieved using Makarovic's rules implemented on the same apparatus (this was of the order of a minute or two).
It cannot be claimed that this was in any way a model of human control of the pole-and-cart, because no comparison was attempted. However, it does show that using a different representation of the problem can lead to solutions that are at least as good, and at least as comprehensible, as the representations already tried.
The problems in representing human control are more obvious than the problems in representing expert knowledge of the type used commonly in expert systems. In medical diagnosis, for example, the decision classes are the different possible diseases, and at least in many cases, these diseases fall into well-defined natural kinds. There is no disease ‘half-way’ between mumps and measles. Also, as a consequence, much of the knowledge is able to be written down, and discussed, and the general kinds of symptoms that are relevant for diagnosis are reasonably well-known. It follows that representation of the problem is relatively easy, even though the rules for diagnosis may be intricate and uncertain, and probabilistic rather than definite. It is in this context that the classic study of soy-bean diagnosis [77] shows such success for machine learning. Because representation in this field is so clear-cut, Michalski & Chilausky did not report any difficulty, or even alternatives, in the choice of representational primitives for soy-bean diagnosis.
Many other papers in machine learning, up to the present, have considered methods of learning classifications based on some predefined set of attributes. Some recent algorithms extend the representation language, by introducing new predicates (e.g. [86]), and other recent work [154] considers the effect of differently aligning the axes of the problem space, to allow more effective rule-induction. Indeed, the idea of change of representation is now established as a topic within machine learning (see, e.g., [121, 137, 149]). Nevertheless these new techniques generally rely on the assumption that there is some underlying fundamental adequate description language known for the problem, which implies that the problem of change of representation could be seen as a search through a large but bounded space of possible representations.
This approach does not fit well onto discovering human representations. Our set of possible concepts is at least exceedingly large, if not actually unbounded, and there are no known laws restricting human ingenuity and imagination in representing problems or tasks in various ways. We certainly do not yet know what the principles governing human representations might be, and so we cannot predict in detail how a human might represent a problem, or what the possible range of human representations is.
Unassisted machine learning, purely from experience, is still a long way from being able to deal with complex tasks. To that extent, it as yet fails to give us a model of human learning about complex systems. It neither ties in with, nor validates, the study of mental models used in training, discussed above (§2.1.6). Nor is there much current concern with the structure of human representations. In a way, this is surprising, because the concept of the ‘human window’ into intelligent systems has been discussed for some time [81]. It would seem obvious to the present author, that if intelligent systems are to have an effective human window, much more must be learnt about human representations, so that human and computer can share a language in which to communicate.
Certainly, the mere fact that a representation is qualitative rather than quantitative does not mean that it is human-like. Machine learning, of itself, does not reveal human representations. The machine learning community is aware of the centrality of representation, but offers no systematic approach to discovering representations, either of human performance, or of unstudied applications, where also there is no known underlying representation out of which to select and build a new one.
Learning about human control rules depends on having a satisfactory representation language in which to describe the rules, and because we do not have any techniques for discovering that representation language, machine learning cannot yet provide a good model of human performance at a complex control task.
Further work for machine learning will be dealt with in the appropriate place (§8.3), but this study now continues with experimental approaches to discovering more about human representations and complex task performance.
The early studies of the last chapter gave conclusions which usefully bounded the desired area of study on two sides. On the one hand, the study of a real-life task seemed to be so complex that it prevented effective progress towards the fundamental objective: the modelling of the cognition involved in complex tasks in terms at least of the representations used. A more restricted and well-defined task was needed. On the other hand, machine learning alone did not promise to reveal human representations or human rules: there being too large a space of possible representations, a plausible qualitative guess was not good enough. It was clear that the research needed to include the study of human control. The encouraging aspect of these conclusions was that there was plenty of scope between these two extremes, and that the extremes had at least delimited the areas of study that were more likely to be fruitful.
Following on from the previous chapter (§3.2), an immediately apparent idea was to study human control of an actual, or simulated, pole-balancing task. The objection to this was that, even if balancing a broom on a finger-tip was a practiced skill in many people, balancing the pole-and-cart system with bang-bang control is not a skill which many people have picked up in their normal course of life. Therefore this would be largely a learning situation. However, there is a common system with similar characteristics that many people have experience on: the bicycle.
Though most adults can ride a bicycle with great skill and coordination, there are no reports of people giving a full account of the content of that skill. On the contrary, in the author's experience of asking people, it is normal to have misconceptions about how bicycle riding is performed. Certainly many authors have used it as an archetypal example of a skill that is not communicated by words.
The technical difficulties of studying real bicycle control put it out of experimental reach of a project such as the current one, perhaps further out of reach than the study of real maritime collision avoidance, discussed above (§3.1). The alternative was to create a bicycle-like simulation, using the computer equipment available. The author had a reasonable understanding of the fundamental physics involved in bicycle dynamics, but did not feel confident to start modelling the finer points such as the gyroscopic effects of the wheels. To distinguish this model from a high-fidelity mathematical model, it was decided to call it the Simple Unstable Vehicle, or SUV for short.
There were two parts to this study of the SUV. In the first, a mathematical model was implemented, which could test the performance of different hand-written control rules, and the results were displayed graphically. In the second, a handlebar interface was constructed to enable a human subject to control the simulation interactively, while watching a display showing the view from riding the SUV.
The literature on control engineering is outside the scope of this study, but it has been reported [78, p.214] that orthodox methods find the problem of bicycle control very difficult. It would appear that there have not been any published claims to have discovered supposed rules that humans might use for riding bicycles, nor rules that describe specifically human bicycle riding.
Logically, after deriving a supposed human or human-like control rule for the SUV, it would need testing to assess its success in use. In fact, a program to test control rules was written first, because it followed on naturally from previous pole-and-cart work. Initially, a pole-balancing simulation program written by Michael Bain of the Turing Institute was adapted, with help from him, to simulate the SUV rather than the pole and cart (this was the author's first experience of C).
The present author alone then continued to adapt and modify the program, adding a routine to display a grid of lines as it would appear to a rider of the SUV, so that some visual impression of the performance of the rules was available. Since this was implemented using black and white, on a Sun workstation without any special graphics facilities, the quality of the graphics was rudimentary. An alternative drawing routine plotted the position of the vehicle on an X-Y grid, so that one could see the time development of the path traced out by the vehicle. The source code for this program, written in C, amounted to around three hundred lines.
In this program, the SUV is represented by a state vector of seven components:
| x | the X-coordinate on the ground |
| y | the Y-coordinate on the ground |
| φ (phi) | the angle of the direction of motion (yaw) |
| θ (theta) | the angle of inclination from the vertical (roll) |
| ω (omega) | (i.e. dθ / dt) the rate of change of the roll |
| α (alpha) | the angle of the handlebars |
| v | the speed along the ground (constant) |
The simulation equations, devised by the present author,
are not based on an exact analysis of the system,
but incorporate a number of linear approximations
valid for small angles and small time steps.
At each time step
Δt (0.02s)
the following calculations are performed:

where
s
stands for distance travelled along the path taken,
t
stands for time
(their conventional meanings),
ks is a constant
related to the angle of the front fork and the wheelbase,
and += has the same meaning
as in C, i.e., add the RHS to the LHS.
Various values for the physical parameters were tried out, based on
an adult mountain bike and a child's bike.
A good set of adult bicycle parameters were:

At each time step, a decision was made about how to change the
handlebar angle.
As in the case of pole-balancing, this was done in a number of
variant ways.
The closest in spirit to pole balancing was for control along a
straight road.
For this arrangement, we define desired quantities
in the form y0 (for
y), and discrepancies between
y and
y0
in the form
y′.
In this case,
y0
is the value of
y
that defines
the desired path of the SUV.
The calculation then becomes:

where Lwb is the wheelbase length.
The discrepancy in the handlebar angle,
α′,
then dictates which of five set increments will be added
to the current handlebar angle.
The constants
k1
…
k4
were set by intuitively guided trial and error.
Values which gave good results were:

This means in practice that discrepancies in roll rate
(ω) are dealt with most quickly,
followed by roll (θ), yaw
(φ), and position
(y).
It may be instructive to compare this strategy with
a qualitative strategy for riding in a circle.
In these calculations (which, for the sake
of clarity, omit some implementation details),
r
is the distance from the centre of the circle,
r0
is the desired value of
r,
r′
is the discrepancy of
r
from its desired value,
r dot
is the rate of change of
r,
and
θ
ω
and
α
are as before.

As before, the discrepancy in the handlebar angle,
α′
dictates which of five set increments will be added
to the current handlebar angle.
Again, the constant values were experimented with intuitively.
Values of the
Q
constants that gave good results were:

The quantitative rules, such as the ones described above for the straight road case, gave very smooth and accurate performance, which, looking at the display, did not look like what one would expect from human control. In contrast, the qualitative rules, such as the ones most recently discussed, give more erratic behaviour. This behaviour is still too regular to look very human, but it certainly looks more like human behaviour than the quantitative rules. We have intuitions about what a natural human performance of bicycle-riding looks like, and this is something that is much less clear for pole-balancing.
The program allowed the initial setting, via command line parameters, of the angle of roll, the speed, and, for some configurations, the desired angle of roll. Setting different initial values of roll ensured that the course followed was not a special case dependent on initial conditions. Variations of speed proved particularly interesting. For the adult bike configuration, the interdependencies were clearly complex, but around 1m/s even the quantitative rule control was inclined to fall over. The child's bike configuration could, on the whole, tolerate lower speeds than the adult bike. Though these results were not explored in great detail, it is reassuring that they are qualitatively similar to the results that one would expect of human control.
Things may be learnt from these tests.
People are unable accurately to describe the skill of bicycle-riding in words, so there is room to doubt whether there is one single human control strategy used. Control engineering does not offer a straightforward solution either, so one might wonder whether there might be a variety of possible strategies. This would make it ‘complex’ under the definition adopted for this study. In turn, this might mean that a study of human control of this kind of system could reveal individual human strategies, and a study of those strategies, and their differences, could serve as a good beginning for studying human control of more complex tasks.
Accordingly, the aim of this experiment was open-ended. The lowest aim was to construct a simulation and to see if this would provide a suitable experimental vehicle. If it did, then one could continue to investigate human rules and representations of human control.
The task chosen was to ‘ride’ the SUV freely around a 100m square area, which we may think of as an empty, level, car park. (From here on, terms appropriate to bicycle-riding will appear without quotes. The reader is asked to bear in mind that these terms are being used by way of analogy.) This task was chosen as a first one, with the idea that if it should prove successful, it would be possible to introduce further constraints into the task. The computer chosen for use was the Silicon Graphics Iris 3130, which gave good quality colour 3-D graphics with sufficient speed to use as a real-time display. The underlying bicycle simulation was very similar to the one used in testing rules, §4.1.1.
The graphic display was from a rider's eye point of view, showing a dark riding area, criss-crossed by white lines at 10m intervals, and surrounded by four uniform walls 1m high, each of a different shade. The area between the top of the wall and the horizon was green and above the horizon blue. This meant that when the SUV was not leaning over, a reasonable amount of green could be seen, but as it leaned further over, less and less was visible. As well as this static scenery, visual feedback of the position of the handlebars and front wheel was given, again based on the way which would be expected on a real bicycle.
At first, the display was drawn as if the rider's head and eyes stayed fixed relative to the SUV, so that the horizon tilted on the screen when the vehicle rolled. Later, following comments from users, this was changed to make the horizon remain horizontal, with the parts of the vehicle drawn tilted instead. Though this seemed a little less disconcerting, there was no clear difference in difficulty of the task.
The steering of the SUV invited a number of solutions. The standard keyboard or mouse could be used, but this would not be very realistic, and it was thought that this could lead to the task taking longer to learn than if more realistic controls were used. It was hoped that using handlebars would help to associate people's bicycle riding skill with the task. The author made some wooden handlebars, designed to match approximately the dimensions and angles of the top section of mountain bike handlebars. To provide a signal, a potentiometer was built in to the stem. A battery connected to this gave an analogue voltage linearly dependent on the handlebar angle. This was connected to an A-to-D converter card on the Iris workstation at Charing Cross Tower (YARD).
The SUV's speed was set at a constant 5m/s, and there were no controls provided for speeding up or slowing down. It was thought that providing such controls would add even more difficulty to the task.
Controlling the SUV when the simulation was running at a lifelike speed proved to be very difficult indeed. Therefore a facility for slowing down the simulation was introduced. Slowing the vehicle down would not have worked, since it becomes much more difficult to control at low speeds. So slowing down simulation time itself was enabled. By pressing any of the numeral keys on the keyboard, the time would be slowed down by that factor, and the simulation could run as if in ‘slow motion’, making the simulation more easily controllable. As an added help in difficulty, it was arranged that when the left mousebutton was pressed, the action would stop until the middle mousebutton was pressed. This was to allow a rider to think about setting the handlebars to a sensible value at leisure.
As the simulation program ran, data was collected into a large array, and at the end, stored into a file whose name was constructed from the time, to ensure uniqueness. These files contained the values, at each time step, of the state vector variables, in their internal form, not immediately readable as an ascii file would be. This amounted to 28 bytes per time step, and since there were 50 time steps per (simulation) second, these files were reasonably large even for short runs. The record files did, however, successfully allow replaying of the runs. During replays, the user had the option of seeing a simple representation of the scene viewed from above, as well as the rider's-eye view which was given during the runs.
Several records files were made. However, the author was the only person of those who tried to control the simulation, who developed any degree of reliability. Other volunteers generally did not spend sufficient time at the task to progress beyond the stage of losing control within a few seconds of starting, even at speeds such as five times slower than real (which was given as the default). In the course of some hours of practice (during program development and testing), the author learnt to control the simulation running at half proper speed, and just one run at this speed was initially selected for detailed analysis. This run comprised 8900 time steps, which represents 178 seconds of simulation time, or 356 seconds of real time, and it ended without falling.
Of the state variables (see above, §4.1.1), x, y, and φ (phi) are not primarily relevant to the task of keeping from falling over, and v is constant. It is the remaining three variables that would be expected to determine the larger part of balancing control actions: θ (theta), the angle of roll; ω (omega), the rate of roll; and α (alpha), the handlebar angle itself. What is not clear is how to represent the control actions.
A first possibility to consider is that the rider's actions
consist in choosing an appropriate value for
the handlebar angle in any given conditions.

The time units are seconds of simulation time,
each equivalent to two seconds of real time in this run.
The angular unit is the radian.
“ANGLE” is α, “ROLL” is θ.
Figure 4.1: Handlebar angle and SUV roll against time for the initial
part of the analysed run
Figure 4.1 shows that there is some connection
between the roll angle of the SUV and the handlebar angle.
Examining the simulation equations (§4.1.1)
reveals part of the reason.
The roll acceleration omega dot is zero when

and since

the relationship between alpha and theta is

The values used in the simulation,
ks = 0.854, v = 5.0 and g = 9.81,
leave us with

Statistical analysis of the data was carried out
on one in twenty of the data points (455 out of 8900),
and one of the results of this was to find a best fit
model for alpha in terms of theta and omega.
Ignoring the very small constant term, this gave

A further method was developed specially for the analysis of this data, and was termed ‘subduction’, after Mill's fourth ‘canon’. (“Subduct from any phenomenon such part as is known by previous inductions to be the effect of certain antecedents, and the residue of the phenomenon is the effect of the remaining antecedents.” [90]) The principle was to find a factor connecting two variables by using a very simple measure of the extent of the match between two corresponding strings of data. The degree of match was evaluated on the basis of how often both quantities appeared at the same time on the same side of their mean value. This also had the feature that the two strings of data could first be given a time offset relative to each other, to see what time offset would give the best match. The factor connecting the variables was that which, when that factor of the independent variable was subtracted from the dependent variable, gave a minimum value to the matching function. The method is not further described here, since it was not highly developed or evaluated.
The subduction method gave

as the best description of the connections present in
the analysed run.
A zero offset was found to give the best initial match.
Thus a simple model of correlation between the rate of
roll and the handlebar angle explains part of the
experimental data.
Another reasonable hypothesis is that the control action is manifested in the rate at which the handlebar angle is changed. Since the handlebar angle is tied to the roll angle, it is reasonable to expect at least some connection between their respective rates of change. The rate of roll (ω) is immediately apparent on the display, and intuitively it seems to be one of the chief quantities determining the rider's actions. However, one problem is that changes in the time-delay factor mean that the same (simulation time) rate of roll appears as a rate that depends on that time-delay factor. Thus, when the time-delay is greatest, with the simulation time much slower than control time, the visual feedback of rate of roll is least apparent.
In the following Figure 4.2, the time units are seconds of simulation time,
each equivalent to two seconds of real time in this run.
The angular unit is the radian per second.
“DANGLE” is α dot, “DROLL” is ω.

Figure 4.2: Handlebar angle and SUV roll rates of change
against time for the initial part of the analysed run
Examination of Figure 4.2 shows a very sharply fluctuating pattern for the rate of change of angle. This is in part due to the quantised nature of the handlebar angle measurement, where the size of one increment is about 0.004 radian, or roughly one third of a degree. The method of calculation meant that the rates of change of handlebar angle were multiples of this amount divided by two time steps (0.04s), i.e., approximately multiples of 0.1 radian/s. This can be seen in the figure.
This graph clearly does not reflect accurately the rider's actions, because of the limitations of the recording equipment. Moreover, it is unclear what would actually reflect the rider's actions. If the graph were smoothed, that would give a better approximation to the angular speed of the handlebars. When the graph is heavily smoothed, its shape gets much closer to the shape of the “DROLL” graph, but since this is anyway implied by a correlation between angle and roll, it does not reveal anything more about the nature of the actions.
Some exploratory statistical analysis was performed on “DANGLE”. This was not taken far, and no results are given here, for reasons that will be covered in the discussion.
Another approach to modelling human control of the SUV is to attempt to construct (by whatever means) control rules that have similarities with human control, either analytical similarities or similar results. We have already seen above (§4.1) how qualitative rules can be constructed. Further rules were constructed with the human data in mind, from intuitive ingenuity based on knowledge of the problem.
One such rule works in two stages. If ω, the rate of roll, is too large, the handlebars are shifted in the direction that will reduce the magnitude of ω. If ω is within a reasonably small region close to zero, the handlebar angle is set to a multiple of the roll angle similar to that obtained above from the experimental data. To enable steady turning, the handlebar angle calculation can be divided into two parts. The first part of the angle is simply that needed to hold the SUV in equilibrium at the current value of roll, that is, 0.46θ. The other part, corresponding to the difference between the 0.46 and the 0.53 or 0.59 factors above, can be set at any of a range of values around 0.1 times the difference between the current roll and the desired roll. Suitable choice of parameters allow this strategy to give anything from highly unstable performance to very smooth, stable performance.
What this hand-written strategy does not deal with, however, are the psycho-motor factors influencing and limiting the human's performance, and the noise. Because of this, among other things, it would not be justified to put this forward as a model of human performance. Also, in the process of writing the rules, there are assumptions made that have no foundation in the empirical data.
The first major doubt to raise in respect of the SUV experiment concerns the extent to which it looked likely to achieve its aims at all. One of the ideas was that humans would be able to relate to the task, because it was to some extent familiar; and that this might lead to a transfer of skill from actual bicycle-riding. The fact that no-one managed to ride the SUV at full speed suggests that, for whatever reason, no extensive transfer of skill had taken place. To anyone who had the experience of controlling the SUV simulation, it was apparent that it did not feel like a bicycle. This may have been due to some unrecognised defect in the model itself, or due to the lack of provision of suitable information and feedback for the subject. There were many channels of information and control in real bicycle-riding that were absent from the simulation. These included:
We can only speculate that some or all of these channels are necessary sources of information or means of control for human bicycle-riding. If confirmation were wanted on the relevance or not of bicycle riding to the SUV, it would need an experiment where bicycle-riders were compared with non-bicycle-riders. Since the latter class are fairly rare, none casually encountered the simulation, and it would take some effort to locate sufficient of them. Such an experiment was not carried out here.
Given that humans could not use their unconscious bicycle-riding skill, the task was likely to involve much learning. The simulation allowed the possibility of concentrating on this knowledge-based kind of performance (in Rasmussen's terminology again) by slowing the simulation down sufficiently to allow time for problem-solving, or conscious thought; but if this was going to be the kind of approach used, there was little point in basing the task on a motor skill. There would be much more obvious ways of studying knowledge-based information processing, if that was what was wanted. But, as discussed in §1.3, the aim of this study was not to explore the knowledge-based area. Alternatively, it might be more fruitful to study pole-balancing skill, since that relates more closely to work already done, and it seems that pole-balancing would have no disadvantage over the SUV simulation as a human control task for study.
But a greater problem, effectively ruling out pole-balancing along with the SUV control task, is the importance of the psycho-motor level of analysis to these actions. Looking at the last section (§4.3), human control of the SUV seems to have much that is difficult to account for with a straightforward cognitive model of control. A full analysis of the SUV control data would have not only to take account of the imperfections in the measurement of human actions, but also to account for the ‘noise’ inherent in the human manual control. A possible approach would be to create a predictive model of the human control actions as a whole, within the tolerances of this noise, along the lines of ones developed in the context of (manual) ship manoeuvring, based on engineering-style approaches (e.g. [136, 139]).
However ship control is not generally considered to be a skill in which fractions of a second are very important. In Sutton & Towill's paper [136], the frequencies of the power spectrum of wheel demands (human and model, compared) lie below 0.15Hz, which is an order of magnitude away from the predominant frequency in our “DANGLE” data, which appears to be around 1–2Hz.
If one wanted to take account of response times, a much more complex model would have to be constructed, where the action effected at a particular moment was dependent on the information available at a slightly earlier time. One of the most interesting features of the data from the SUV experiment is that they show little or no average delay between ROLL and ANGLE, and between DROLL and DANGLE. This would point towards a model of control actions as based on predictive quantities, not just the most obvious current quantities. In other words, the rules governing a detailed predictive model of human control would probably not be based on exactly the same quantities as those underlying the hand-crafted rules for SUV control.
As well as the unfathomed complexity of the finer details of the psycho-motor mechanisms by which actions are effected, there is also the problem of relating these actions to intentions which could be present at a conscious level. We can clearly imagine a conscious intention to place the handlebars at a certain angle, or to move them for a certain period of time at a certain rate. But the pace of actions in such a task is too fast for a verbal report of intentions at this level, and it seems unlikely that any conscious monitoring of actions would reveal reliably what was being done.
If there are rules governing the control actions, then there must be a way of representing those actions in harmony with the way actions are represented in those rules. If we cannot reliably infer that representation from verbal reports, then we would have to infer the representation from the records of actions alone. It is unclear how this could be done, given the presumable complexity of the psycho-motor processes, which mediate intentions to physical actions, in this kind of task.
The possibility of writing fairly simple control rules suggests that there may be simple control processes at a higher level, which are masked by the contortions of lower-level processes which attempt to make up for psycho-motor limitations. We may infer from this that modelling a manual task is likely to involve modelling at the psycho-motor level: perhaps involving both mechanisms of perception and mechanisms of effecting actions. Although this is an important area of study in its own right, it does not have great implications for the kind of real-life task that we have in mind throughout this study.
Worse, the involvement of an important psycho-motor aspect will tend to obscure the other, more cognitive aspect of performance. This may happen from the point of view of the operator, for whom a task can demand much motor-skill learning while being relatively straightforward at higher levels; and from the point of view of the researcher, who would have to unravel the motor-skills before gaining a clear impression of the cognitive skill.
The main conclusion must be that in this type of task, it is unclear how to represent human actions, and this blocks a deeper analysis of the human skill. Thus, we need to study a non-manual task where the complexity would have a more cognitive character.
If human response to complex tasks was to be studied, experiments were needed to obtain relevant data. To help in the evaluation of experiments, let us distinguish a few constituent parts of a suitable experiment.
Considering these elements together brings up a number of criteria for the prospective evaluation of any candidate experimental system. These criteria are partly based on reasoned reflection a priori, and partly on experience from other systems, and knowledge gained from previous study.
The following criteria are not seen as specific to the author's actual position, and therefore they are presented as general methodological points, with the possibility that the same criteria could be relevant to other research into the same area. Specific options will be considered in detail below, §5.2.
The idea that the study of games can be relevant to understanding complex dynamic systems is supported by Rivers [113]. He suggests that study of games and simulations could address questions such as: how do people generally make decisions and cope with complexity; how does the surface representation of the underlying dynamics of a situation affect people's understanding of it; how do people generally learn to behave in relation to complex dynamic systems; what is the variability between individuals on these dimensions; to what extent is it possible to predict performance in the real situation from performance in a game? This further motivates the consideration of games as well as higher-fidelity simulators and live applications, as relevant to the general aims of the present study.
The nature of complexity is not unambiguously defined, but has been discussed above, §1.3.2. There are factors weighing both for and against greater complexity in an experimental task.
The argument in favour of greater complexity is that the relevant real-world systems and tasks are highly complex. The more like these tasks is an experimental arrangement, the more relevant an experiment would be to these tasks. In particular, the more complex a task is (using a common-sense meaning of complex) the more likely it is to exhibit complexity as has been operationally defined above (§1.3.2), namely, that a variety of strategies is likely to be employed either across time, or across different subjects.
When we come to consider tasks and systems of equal or comparable complexity to these real-life systems, problems emerge. Subjects will either be fully trained or not fully trained beforehand on the task. If they are fully trained, they are unlikely to be readily available as experimental subjects, as their training tends to be expensive, leading to a high cost of their time. If fully trained personnel were to be used, the experimental system would have to closely match their normal working environment. This entails either using real-life equipment, or (usually expensive) high-fidelity simulators. If, on the other hand, subjects were not previously trained on the target system, they are likely to take a long time to develop a stable skill in performing the task. This, in turn, means either that the experiments would have to be extended over a long period (with consequent expense), or that the subjects would still be learning about the task and system as the experiments were performed. If subjects are still learning, instead of there being a stable set of rules underlying their behaviour, the rules would still be changing. Modelling a stable set of rules is the more fundamental aim: so it would seem unwise to try to model rules in a learning situation without, either at the same time or beforehand, being able to model stable rules.
If a realistically complex target system is desired, but no actual system can be used as it is, there is an unknown amount of work needed to realise an effective experimental system. In the case of building a computer simulation from scratch, the time necessary is likely to be prohibitive.
The conclusion of the arguments on complexity is that we would like the most complex target system and task that come within all the practical limitations. In practice any system that conforms to these limits is likely to be not more than fairly complex.
A related aspect of the choice of task is the choice of level of control. This considers the task with respect to the operator interface, rather than the underlying target system.
In the design of any complex task interface, there is a choice of level for the sensors and effectors. At the lowest level the primitive components of the interface correspond to individual elements of the target system—the raw sensors and effectors that are implemented in hardware. At a higher level there would be some composite sensors or effectors that in some way combine more than one lower-level sensor or effector. Let us illustrate this with a few examples.
A raw sensor might give the revolution speed of a motor, or the temperature or pressure of a certain part of the target system. There are many possibilities for higher-level sensors. A sensor which gave the estimated time to a particular condition being satisfied would have to integrate information on current values and current rates of change. A sensor for the working state of a ship's rudder needs information about the rudder angle and the angle of the water flow past the rudder. Further examples can be imagined. Any operational concept that depends only on measurable quantities could in principle have a high-level sensor built to display it.
In complex systems, the lowest level effectors sometimes have servo systems on them which cannot be bypassed, and for this reason among others the effectors do not necessarily directly alter the quantities sensed by the lowest level sensors. In ships, typically, the direct controlling actions are to set demands for the propeller speed or rudder angle, since it is not possible for these to respond immediately. Servo mechanisms then bring the actual value towards the demanded value over a period of time, perhaps several seconds. In more everyday examples, low-level effectors often take effect simultaneously with the physical control action—gear changing in a car, for example. Higher-level effectors are set up whenever programming is done. In mechanical systems, a higher-level effector might have the same effect as a number of lower-level ones. As with sensors, construction of higher-level effectors is not constrained in principle. In terms of a game or well-defined task, the highest level effector possible would be a single button that started automatic execution of the whole task.
The level of control has important consequences for what can be learnt by observing control actions. Observing control actions at the highest possible level would not reveal anything about the mental structures involved in task performance, because there would be no structure in the control actions. At low levels of control, the salient features of the control actions are likely to concern the lower levels. The extent to which higher-level structure is present and established in human control would depend on the extent to which the human had mastered the lower levels, and gone on to develop higher-level control strategies. Lower levels preceding higher levels of control is reflected in many human activities, where you have to learn ‘the basics’ before you are able to learn the more advanced points, and this is largely dependent on experience gathered through time. If one wishes to study higher-level strategies, the situation to avoid is where a low-level interface is being used by a person who has not had the time to master the lower levels completely. For complex systems, mastering lower levels could take a long time.
The different levels of control are also reflected in Rasmussen's categorisation of skill-, rule-, and knowledge-based behaviour [101]. The lowest level of sensors is most likely to correspond to the skill-based level, where Rasmussen characterises the information as signals. When humans act at the skill-based level, their actions can often be clearly seen as effectors at a similar level—consider steering a car or bicycle, or being a helmsman on a ship without the autopilot. At an intermediate level of control, corresponding with Rasmussen's rule-based level, the actions taken are more abstract, but still without knowledge-based processing. For information to be appropriate to this level of control, it must be presented in terms of the antecedents of the rules being used. Rasmussen calls this information signs. Higher levels of control are more likely to correspond with Rasmussen's category of knowledge-based behaviour. However, at the highest possible level of control, where the task is completely automated, human cognitive processes are no longer necessarily involved at the time the control is being carried out.
The knowledge-based level is where both conscious mental processing, and explicit learning, are most likely. If explicit learning it going on, this suggests that some salient aspect of the cognitive structure is changing, and this is more difficult to study than an unchanging cognitive structure.
Overall, considerations of the level of interface suggest a fairly low level of control as appropriate to an experimental arrangement, but not so low as to make the task too complex and difficult to learn thoroughly.
In contrast with these arguments for a low level of control, the experience of the Simple Unstable Vehicle experiment (above, Chapter 4) warns us against control that is too much motor-skill based. There it was noted that investigation of motor-skill tasks is likely to require discovering about relatively low-level perceptual and psycho-motor skills.
In practice, complex tasks such as the ones we are holding as exemplars tend not to involve any motor skill. A ship's master would rarely take the helm: most actions are initiated by spoken commands. In most supervisory control tasks, there are no analogue controls present on which motor skill would be appropriate (beyond the everyday skills of pressing buttons, etc.). Therefore excluding motor skill from an experimental arrangement would benefit the relevance of the experiment.
There are various ways in which motor skills and psycho-motor limits could appear. One is hand-eye coordination: for example in which the mouse could be used to guide the cursor following an intricate route; or the cursor coordinates on the screen could be used as an analogue input to a simulation. The limitations here would be more obvious in cases where a human had impaired limb movement. Another aspect of motor skill is in the precise timing of actions: either doing a planned action at an exact moment, or reacting as quickly as possible to an unexpected stimulus. Everyone knows about their own limit of reaction time.
Having no motor skills in an interface means ruling out a whole level of interaction. This is in opposition to the idea of “direct manipulation” (e.g., [126]), where the advantages of physical, reversible, incremental interaction are stressed. But removing much of the vast range inherent in analogue interaction makes the job of precisely recording the interaction much simpler, and may lose a great deal of variation which did not have any significance for the present study. A further advantage is that a task with a limited range of interaction could provide a fairer comparison of unmediated human ability with the performance of pre-programmed rules.
Whatever the target system, and interface to it, there is still the question of how the task is specified. Without a specified task, users of a system might explore it, or experiment with it, in whatever way comes to mind at the time. They may set their own goals explicitly, or may rely on unspoken implicit goals to guide their behaviour. They may not appear to have any goals at all.
Being goalless is not what is wanted for this experiment, for two reasons. Firstly, real-life complex systems rarely permit much exploration or experimentation. Typically, some aspects of an operator's task are clearly defined by his or her employers, and this may well be sufficient to prevent exploration, particularly when there is risk or danger involved. Secondly, in order to study the human approaches to a complex task, we need to have as much data as possible relating to the same task. Thus, we do not want to allow users to make up their own tasks as they go along, with the twin risks of the task changing frequently, and it being not easy to know at any time what the effectively current task is.
In real-life tasks, any operator may be motivated by a number of factors, some of which may be common to all operators, and some which may be personal, or may be varied in the strength which different individuals attach to them. In this sense, the tasks performed by different people in the same job are not necessarily identical. This is even more likely to be true in complex tasks, where there are a variety of possible strategies, than in straightforward tasks, where there is a highly constrained set of methods and acceptable outcomes. Ideally we would want to dispense with this variation of motivating factors, for the sake of this stage of experiment.
Explicit predefined goals would avoid these problems, and provide a stable and well-defined task for operators to adapt to. This may be more motivating than trying to achieve one's own ad hoc goal, if only because it is difficult to give oneself finely-graded feedback on a self-defined task, and without fine feedback, the improvement with practice will be less noticeable, and therefore probably less motivating. An experimental subject is even less likely to set goals of the type usually encountered in complex systems: that is, multiple conflicting ones.
Another important factor for the potential subject is the inherent interest and challenge of the task. While a well-defined task is an important element in this, another important element is the nature of the task itself. It would seem likely that an operator could relate more easily to a task that has some realism in it, and where “things happen”. This realism need not be the strict engineering realism of high-fidelity simulators, especially not so if the subject has no detailed knowledge of the target system. But it should give the sense to the subject that he or she is engaged in a real task. One way of spoiling this sense of realism is to have a component of the simulation behaving counter-intuitively. This is less likely to matter if it is only a weakly-held intuition about something of which the subject has little experience, but even in unfamiliar situations there will be some strong expectations based on general knowledge of the world, and these should be respected.
We turn now from the requirements of the subject to those of the experimenter. What does the experimenter do, if the experimental arrangement turns out to be producing data more relevant to another study than to this one, as was the case with the SUV study (Chapter 4)? In principle, the target system, the definition of the task, or the interface could be modified to change the nature of the data produced. An experimental system would be better, on this criterion, if it was able to be modified. A simulated target system may need to be altered if the behaviour of some part proves counter-intuitive. The task might need alteration if it produces behaviour which is either too knowledge-based or too motor-skill-based. The interface might need modification if it is too much of an obstacle in the way of performing the task.
Modifying the target system itself would be difficult for a system not written by the experimenter. The task could be changed in any case, but if the interface was not able to be changed, the task definition would have to be on paper, which may not be so satisfactory (as argued above). Altering the interface has similar constraints to altering the target system, except that no knowledge of simulation mathematics would be required. The main point here is that modifiability is not easy criterion to satisfy, and therefore needs close consideration.
The need to log data is a briefly statable but centrally important criterion for a good experimental system. Without the ability to log data and analyse it, the experimental method would be severely constrained, and would have to rely on verbal reporting (for a discussion of verbal reports, see Bainbridge [6]).
Detailing this requirement, data needs to be logged in such a form as would permit the complete regeneration of of experimental trials: both the situations which occurred during the experimental runs (in terms of information presented), and the actions taken by the operator. This must be machine-readable. The practical considerations of storing the data must also be taken into account.
A final practical criterion of choice is the obvious one, that whatever system is chosen must be realisable in some way or other. For systems tied to bulky hardware (such as training simulators), this means in practice that access is needed. For ready-built simulations, the code must be available in a form which can be run on an available machine. For unimplemented simulations, the mathematics must be available, and it must not be too difficult to code. If the simulation and the interface are separate, the same considerations apply to both.
Subjects must also be obtainable, which means taking into account any need for skill or experience, and the time the subjects are needed for.
Some choice of experimental system needed to be made to enable the further study of this thesis. The consideration of possibilities ranged widely. For completeness, we will here briefly discuss the options examined at the time of decision, along with others, already rejected, which have been discussed more fully above. The following options for the object system are discussed here, with reference to the criteria given in the previous section:

Key: see text
(ascii version available)
Table 5.1: Comparing experimental options against criteria
Table 5.1 gives one-word summaries of the suitability of the options on each criterion. A question mark indicates an uncertain evaluation, and “poss” indicates that the relevant criterion is at least to some extent under experimental control.
A choice of implementation platform also needed to be made. This was largely dependent on the choice of object system, and will therefore be mentioned at the end of this section.
This has already been discussed above (§3.1), along with reasons why it is impractical to gather data from such simulators.
This system is described in a paper by Hollan, Hutchins & Weitzman [55]. The fact that there appeared to be no working versions in Britain at the time of enquiry limits this review to the contents of that paper. STEAMER is included here because it appeared at first sight to be a candidate worth considering as an experimental vehicle.
The STEAMER project was aimed at evaluating techniques for the construction of computer-based training systems. They chose a naval steam propulsion system as the domain, and constructed an “interactive inspectable simulation” with the aid of high-level graphics and AI tools.
About 100 diagrams both illustrate the operation of the system and its many subsystems, and provide a means of controlling the simulation. The intention was to make the simulation at least conceptually realistic, if not high-fidelity in an engineering sense. The paper does not describe in detail how to use STEAMER as a training tool: however it is fairly easy to imagine a control task being defined using STEAMER, and training being given for this.
The problems with STEAMER in the context of this thesis stem from the different motivation behind its design. It is intended to provide the kind of interface that allows trainees to develop their own mental models of what is going on. Hence there is much emphasis on the graphics, with ‘direct manipulation’ where possible. It would appear that exploration plays a big role in the kind of training that these authors envisage. This may very well be an important part of training, but it does have a negative correlation with the definition of the task. In some ways, STEAMER could be seen as aiming at the stage of training before (and perhaps also while) definite tasks are introduced with the idea of trainees honing their skill against definite performance criteria. One can imagine trainees with STEAMER saying to themselves “Let's see what happens if I do that”, and “Ah! So that's how it works!” In this context, it makes sense to provide the maximum amount of information, and undoubtedly graphical interfaces can help in this to a great extent. However, the same design philosophy does not lend itself to providing detailed feedback against external objectives. It is difficult to judge how much task definition and feedback could be introduced without having seen STEAMER at work.
STEAMER is put together using a sophisticated graphical editor designed specifically for the job. This means that, in the ways the editor permits, it would be easy to adapt the system, simplify it, or even build a new system from scratch. But the very specificity of the graphics editor, and the complexity of the system in which it is embedded, means that it would be very difficult for someone without extensive experience of that system to adapt it in any way that was not specifically envisaged by the system's designers.
The flight simulator game on the Silicon Graphics Iris 3130 takes us down in complexity and realism, but still retains enough realism for the simulator to be interesting, and naturally used as a recreation, even though, in the absence of another similar networked machine, there is no clearly defined task other than landing the aircraft in a manner as close as possible to a preset way which has a maximum score.
The level of control is almost entirely near the lowest level that one would have in an aircraft. This means that manual skill plays a large part in successful landing, as is the case in (unaided) real life. Hand-eye coordination and speed of reaction are probably both limiting factors here.
The chief positive points that this system has are firstly that it is obtainable, and secondly that there is a logging mechanism from which one can replay previous flights. However, these positive points are not strong enough to overcome the big problems that this system would encounter if used as an experimental vehicle. There are two problems with the logging mechanism. Firstly, the log files take up a very large amount of space, and it would be impractical to store more than a few on hard disk. Secondly, the log only stores the situations that occurred, not the control actions. Even if the control actions were stored, it would be difficult automatically to characterise control actions at a higher level, starting at such a low analogue level.
The best aspects of existing computer games are their good task definition and feedback. Evidently, these are important features for any game to have intrinsic appeal.
Many computer games, including all those of the ‘space invader’ type, are heavily based on manual skill. These can immediately be written off as desirable experimental vehicles. Another category is the adventure game with verbal interaction. These are not dynamic control tasks (see above, §1.3.1), but are of a different class which is of less interest to us here. At the time of choice, there were no obvious candidates which escaped these two complementary problems.
Another problem with commercially marketed games is that the source code is not available, and this means that the game is not adaptable, nor is any automatic logging of actions possible.
Nuclear power plants feature strongly in the literature related to HCI and complex systems (see above, §1.2.3.2). For this reason among others, the idea of a power plant simulation was interesting. A simulation system had been set up in Denmark several years ago, called the Generic Nuclear Plant (GNP), which is a simplified version of a pressurised water reactor, designed with experiments into operator control in mind.
Enquiries for the source code revealed that it was written in Pascal, but not generally available. It was not clear whether there was any particular interactive interface already built for the GNP simulation. If not, then the task of building an interface would be not much less in scale than the task of building a whole system complete with interface. Even if an interface was built, it would be very surprising if it did not need substantial modification to provide all the facilities required for the present work.
In other respects, the task was clearly a promising one. The dynamic nature, and long time constants of the system ensure that there are no psycho-motor limits to contend with, and that the skill is more a cognitive than a motor one. But with no available complete system with interface adapted to the present experimental requirements, the idea of a nuclear power plant simulation had no particular advantage over a task that had to be constructed without the help of a target system simulation that had previously been implemented.
Having rejected the idea of nautical collision avoidance, there remained other possibilities in the same field. Mathematical simulations of some of the relevant objects were available, which would make possible reasonable realism. A task could be chosen to lie in the acceptable range of complexity, with a reasonable level of control. The interface could be designed to eliminate psycho-motor limits. Task definition, feedback and logging could be built in, and having constructed the system, adapting it would be no more difficult than necessary.
The great disadvantage was the need to implement all the software without external help, which would inevitably detract from the time available for experimentation.
An important extrinsic factor in the final decision was the fact that the area of study originally envisaged had been nautical. Resources, expertise and interest were available in this field in a way that they would not have been in another. Despite the burden of needing to implement the software, a task built from nothing appeared to be the only way of securing a suitable experimental vehicle. On these grounds, a nautical task simulation was chosen. A platform to implement the experiment then needed to be chosen.
Since the chosen task had an important spatial content good graphics were desirable, preferably colour; and good graphics primitives on a system make graphics programming less difficult. The systems that were available were the ones already used in the Simple Unstable Vehicle experiment (Chapter 4): these were various Sun workstations, and the Silicon Graphics Iris 3130 computer. Of these the Iris was clearly preferable, in virtue of its superior graphics primitives and fast dedicated graphics hardware. An added bonus was that two almost identical machines of this type operated at the Scottish HCI Centre and at YARD Ltd., and time was available on both systems for development and experimentation. No other system available at the time had the same advantages.
The choice of implementation language was restricted. Although an object-oriented approach may have been tidier, or in other ways preferable, such languages were not at the time installed on either computer. The availability of compilers at the time of writing the programs, the ability to write low-level code where necessary, and the ease of the interface with the graphics commands, all dictated that C would be the language chosen. UNIX was the operating system for the chosen workstations.
We have studied the suitability of different possibilities for experimental systems, and the conclusion was that a new system needed to be built. The aim of the simulation system was to produce data from human control of a system: then this data would have to be analysed, prepared and explored; with the ultimate aims of firstly trying out the method of using data gathered in this way, and secondly of exploring the nature of human control.
An objective study of controlling complex systems was wanted, not relying on verbal reports, or purely subjective interpretations. The most promising focus for such an objective study appeared to be the representational primitives used by humans in the cognitive processes underlying their control decisions. The justification for this comes from considering a key feature of rule-induction algorithms.
Since rule-induction algorithms are noted for their dependence on the suitability of the representation primitives (as we have noted, §3.2.3), the possibility exists of turning this connection round, and using the effectiveness of rule induction as a measure of merit of the representation. We should note, however, that we could fail to get good results on many grounds, only one of which is the quality of the representation. If some other problems exist (e.g., see below, §6.4.2), there would be some limitation on the performance of the rules, and we might get only relatively small effects from changing the representation.
Hence subsidiary aims were to produce a means of preparing the data in accordance with a variety of representations, then to test the performance of a rule-induction program with the prepared data. The relative performance of rules generated following the different representations would then reflect their relative merit, and hence give some lead on the correspondence of varying representations with a supposed inherent structure of the data. In human control of a complex system, this would in turn be evidence for or against the claim that certain concepts were salient features of an operator's ‘mental model’ of the task or the system, irrespective of whether the concepts were verbalisable or not.
Inevitably, the aims of this first experiment could not be defined more closely than this in advance, since it was not at all clear where difficulties would occur, and where progress would be halted.
Since the objective of the research was to investigate human performance of complex tasks, a task had to be built. The chief factor of importance in the design both of task and interface was to provide a source of data suitable for analysis.
The key criteria influencing the design have been discussed above (§5.1). It was generally accepted that the important aspects of a program implementing these design principles were principally that it worked, secondarily that it was able to be updated as required, and only last and very much least the elegance or finer details of the coding. Discussion in this section therefore concentrates on the important design decisions and how they were implemented.
The simulation program, and all the analysis programs with the exception of the rule-induction program, were written by the author.
The general approach taken in the construction of the program was that of top-down functional decomposition. In the main function, after initialisations, there is a main loop from which are called other functions, which deal with the simulation of each simulated object, the scoring, the interface interaction, and the logging of the actions.
On-line help had the advantage that access to it could be recorded in the same way as the other interactions. For that reason, the main function was designed to cope not only with the simulation interactions, but also with the ancillary interactions, including access to help, that surrounded the individual games.
The total length of code in the simulation programs was around 10000 lines. Of this, the code specifically for replaying accounted for about 1500 lines, help accounted for some 1000 lines, the interface for about 3500 lines and the simulation itself for approximately 4000 lines. These are approximate values, not only because the layout of the code is arbitrary, but also because there was not always a clear separation between the code for the different functions. However, these figures do give a general indication of the relative complexity of the various aspects of the program.
The obvious approach to maintaining a simulation in real-time is to do everything that is necessary for one step, then to wait, checking the system real-time clock, until the time comes to do another step. In this program, the simulation steps need to be performed, and the interface display refreshed, both of which would clearly take more than a few milliseconds.
For consistency, a particular length had to be chosen for the time loop, and the choice of length was influenced by two factors: firstly the maximum amount of time that the necessary program steps might take, and secondly the suitability of this time interval from the user's point of view. This second consideration can be further broken down into two points: on the one hand, the refresh rate had to be fast enough to allow the user to have a sense of immediacy in control and feedback, but on the other hand, if the refresh rate was too fast, the user's performance would depend more on exact timing, reintroducing the effects of psycho-motor limits, which were seen as undesirable.
After the initial coding had been done, it was clear that a decent simulation and interface could be performed on the chosen system within about 0.2 seconds. However, following the discussion in §5.1.3, it was undesirable to set the refresh interval too close to a typical simple human response time as this would create the possibility that non-cognitive aspects of response time would be an important factor. Half a second was therefore tried, and no subjects complained about the refresh rate being too slow. This timing was therefore accepted. (On other available systems, the same machine computations could well have taken over 0.5 seconds, and therefore forced an undesired choice of timing.)
It was found that using the same interval of 0.5 seconds for the length of the simulation step caused problems with the cable simulation, and was in any case unnecessary since one simulation step for all the objects took only a small fraction of a second. After trying different values, a simulation interval of 0.1 seconds was fixed on as giving a reasonable balance between accuracy and low computation time. In each half second therefore, five simulation steps for each object are performed, in immediate sequence.
The overall task was to identify all suspicious objects in an area of sea-bed, to dispose of the mines, and to return to the starting area. This was done with a ship, a ‘remotely operated vehicle’ (or ROV: a small unmanned submarine), and an umbilical cable that connects the two together. A short way of describing how to perform the task was thus:
Repeat
find a target;
send the ROV to look at it;
if it is a mine, fly the ROV to the required position, and at some later point, detonate the mine;
until all targets are dealt with.
Return to home.
The task was more closely defined by the scoring system. This was as follows:
All the values were changeable, the idea being that changes in the scoring system can be used to modify the characteristics of the task. In the first experiment, these values were 5000 for completion, 500 for identification, 100 for misidentification, 500 for mine disabling, 10 points per half-second for going within 100m of an unsafe target, and a variable damage score if a mine explodes with a vessel within range.
It can be seen from this that there were trade-offs between on the one hand speed, with low time penalty, and on the other hand care, to avoid the risk of explosion. This kind of trade-off is common in the control of complex systems, wherever the areas of danger lie close to otherwise desirable paths, and it was generally seen as important to the relevance of the game that such trade-offs were set up. Another way of describing the same aspect of the task is that there may be multiple conflicting goals at any time, and the operator has to find his or her own balance.
The simulation is divided into four parts, one each for the ship, the ROV, the umbilical cable, and the targets. The first three, which are the controllable ones, also have their own sub-displays, only one of which is able to be seen and used at one time. Since the cable potentially affects both ship and ROV, it is done first. This is followed by the ship and the ROV, and finally the targets, which explode if the ship or the ROV has done the wrong thing.
This was the most problematic part of the simulation. Cable models exist based on finite element analysis [74], but these tend to be computationally very intensive, and probably therefore inappropriate for a small-scale real-time model such as the one built. Simple models are easy to imagine and implement, such as an elastic cable without water resistance lying in a straight line between the ship and the ROV. The problem with such simple models is that their behaviour is both counter-intuitive and unrealistic. This lack of realism could easily distract the operator from the task, to trying to discover how the cable in fact behaves.
For this task, the author therefore constructed an original model. This model is based on the fiction that the cable can be represented for many purposes by a single point halfway along its length. The elastic forces can be dealt with reasonably in this way, and the motion of the representative point provides a basis for calculation of overall water-resistance. It was not clear how good this model would be, so it was implemented, and tested by manoeuvring the simulation in ways that would discover the model's limits.
The model was then refined a number of times, by introducing factors which appeared to be relevant to the discrepancies between the actual and the desired behaviour. Since intuitive plausibility was more important that technical accuracy, the desired behaviour was that which did not appear counter-intuitive. The author makes no claims about the accuracy of the resultant model, only that it seems to behave in a reasonable and interesting way.
Other problems that had to be tackled included unstable oscillations of the cable in tension. This can be due to the length of the time step being too large to enable quick changes to be dealt with properly (cf. [93] “As is well known, explicit finite-difference methods for initial value problems are susceptible to numerical instability if too large a time step is taken”). This was solved by insisting that the cable mid-point could not go to the other side of its equilibrium mid-point position in one simulation step.
Accuracy was more important here, since in YARD there were numerous experienced mariners who had more finely-tuned ideas about how a ship should behave. The model constructed was based on a mathematical model of an actual vessel design [8]. Since the design of ship was not entirely up to date, the information was not highly sensitive: however, as a precaution, the parameters were altered slightly without having a large effect on the behaviour of the ship. The original model was on paper (not programmed) being a detailed model of a ship's behaviour in calm to moderate weather, taking into account all six degrees of freedom: roll, pitch, yaw, surge, sway, and heave. Douglas Blane of YARD simplified the model by cutting out roll, pitch, and heave, and making simplifying assumptions about the rudder; and the author implemented this simplification. The model takes into account wind, waves, and tide, although these were not used in the first experiment other than in a casual exploratory way.
The propeller and rudder controls were modelled as if controlled by servos, with a fixed rate of alteration, so that it took a reasonably realistic amount of time to achieve a given control demand. These parameters were decided on after informal consultation with experienced personnel at YARD.
YARD had a model of a particular ROV (Remotely Operated Vehicle) implemented as a mock-up simulation, with a scenario of inspecting the legs of oil drilling platforms. This vessel simulation, based on previous research [92], was slow, ungainly, and asymmetric, and had directable thrusters and a camera that could be tilted and panned. This simulation was too slow for the kind of situation envisaged, with too much unnecessary detail and high fidelity in the hydrodynamics, which would have made it difficult to adapt to the chosen implementation environment. The author therefore implemented a much simpler vessel, with much simpler hydrodynamics, in which the original six degrees of freedom were reduced to four by ignoring (setting to zero at all times) roll and pitch.
A number of additional features were included. The effect of the umbilical cable on the ROV was modelled, and turned out to be an operationally important constraint even before the cable became fully taut. Clearly realism and plausibility were to be enhanced by modelling interaction of the ROV with the sea bed. The author devised a model of sticking in the mud, which resulted in gentle collisions with the bottom being able to be freed using upwards thrust, while heavier collisions needed the cable to be reeled in to free the ROV. As with the ship, the effect of tide was modelled, but not used in the first experiment. Not modelled in the first experiment was collision of the ROV with the target objects, nor collision of the ROV with the ship.
To maintain player interest and uncertainty, it was decided to have the sea-bed targets randomly positioned in a given area. The precise time of giving the order to start a game gave a random number seed, and pseudo-random numbers generated from this seed gave the number, type and position of the targets. This seed was recorded so that precisely the same set-up could be regenerated for a replay. Randomly varying the type of targets meant that the player did not know whether a target was dangerous or not before observing it at close quarters, and the random number of targets (with a mean value of five, but soon constrained to be at least five) prevented the player from going back to base before checking in all corners of the minefield.
There was no official information on which to base the behaviour of the mines, so the author implemented his own idea of how an acoustically operated mine might work. In the simulation, it is set off by the ship propellers or ROV thrusters being at too high a speed too close to the mine.
As discussed above (§5.1.2), the task needed an interface that was on the one hand sufficiently low-level to require both substantial learning, and creation by the operators of higher-level structure above the level of the interface; but on the other hand not so low that the task took too long to learn (as would have been the case with a typical live complex system). Pitching the game fairly near the lowest level of the task described would enable the observation of learning higher levels which were easily understandable. The level of interaction would be confirmed as not too low if the subjects were able to learn the task to a fairly stable state in the allowed time.
In contrast with, for example, the Iris flight simulator, it was decided to conduct all user input through pressing the mouse buttons. It is a natural extension of the mouse terminology (and common, if slightly loose) to refer to the active areas on the screen as buttons, and the action of pressing on the mouse button while the cursor is in a particular active area as a “button-press”. The advantages of this are that firstly all the ‘buttons’ can be labelled with their effect, eliminating the need for the user to memorise codes or consult help screens in the middle of a run. Secondly, immediate visual feedback can be given, which in the case of this interface was done by highlighting the background of a button that had just been pressed.
Also discussed earlier was the goal of minimising the significance of motor skill, and psycho-motor limitations. The interaction was therefore designed to rule out the effects of small fractions of a second. Only one button-press was taken into account in one half-second, and implementation was only at the half-second boundaries.
The ‘Seeheim’ model [44] of user interface management conceptually separates the interactions that deal solely with presentation of information from those that affect the controlled system itself. This was adopted as one of the design principles. This decision having been made, there were four general divisions of the interface:
These four divisions were reflected on the screen by having four columns with different coloured backgrounds, one column for each division. So as to maximise the distinction between presentation and simulation effectors, these were situated on opposite sides of the screen.
The next important design decision was whether to have all the information present at once. There were three good reasons why not. Firstly, to put all the information on one screen would produce very small areas of screen which could not hold many characters of a reasonable size font, and the effectors would be difficult and slower to locate than ideally. Secondly, practical complex systems, if their interface uses VDU screens, tend to need to split up the information into a number of different screenfuls. Thirdly, by having less than all the information on the screen at once, the obvious possibilities for the information being used at any particular time would be limited. This would help the analysis of operators' decisions. The sensors relevant to a group of effectors should be displayed along with those effectors.
The highest-level divisions apparent were between the different objects of the simulation: the ship, the ROV, and the umbilical cable. It was therefore decided to divide the screen horizontally into two parts, one of which would show information relevant to the task as a whole, or all the objects of the task, and the other would show sensors and effectors either for the ship, or for the ROV, or for the cable. The resultant appearance of the interface is shown in Figure 6.1, with the ship sub-display showing.

Figure 6.1:
The interface in the first sea-searching experiment
One of the main considerations in the design of the interface was modifiability. Thus, the program had to be designed so that it was easy to change the details of any of the interface elements, or add new elements or take them away.
For example, let us consider adding a new element to the interface. To do this, at least the following steps need to be considered:
The basic conceptual structure used in the implementation of the interface was a hierarchy of sub-displays, columns, rows and elements. This was reflected in a four-dimensional array of structures, each one of which contained the information relevant to the display element. The positioning of the elements on the screen was taken care of by automatically allocating them equal spaces in their row, which were allocated equal heights in their column. The overhead involved in this was the maintenance of hard-coded arrays of the number of rows in each column, and the number of elements in each row. This was much easier to keep updated than would be the alternative approach of changing the element positions by hand each time the number of elements changed. Columns were sized in a hard-coded fashion, since changes were not anticipated at this level.
One function was responsible for calling the many functions needed to effect the actions. The rest of the information about the interface elements was kept together hard-coded in a function which was used at initialisation. For the addition of a new element, one therefore needed to do little more than:
#define);The main time loop executed once every half-second. In order to avoid the effect of precisely timed actions, two measures were taken. Firstly, button-presses occurring during a half-second interval were stored until the end of that interval and actually executed during the next interval, simultaneously with the button being highlighted on the screen. Secondly, the interface only accepted one button-press per half-second, and ignored any others coming in the same half-second in which one press had already been stored. Nor were the button-presses queued.
Obviously, for such a complex task, a user would initially be in great difficulty if there were no explanation of the game. The provision of help also enabled some useful knowledge to be presented, so that the user did not need to discover this from experience, which would retard learning in general. Provision of help was able to be fitted in to the form of the interface as designed for the game, thus providing help on-line, which had the added advantage that it could be monitored, and studied if thought worthwhile. Another feature provided was the ability to replay previous games. Two demonstration examples showing the operation of the ship and the ROV were included, but none showing a complete game by another player, as this was thought likely to influence the style of the beginner.
The text of the help messages was kept in separate files, read in when a particular section of help was requested. This enabled changes in the format of the display without needing changes in the text itself; and changes in the help without recompiling the program. The content of the help for the second experiment, which is slightly different from the first version here, is given in Appendix A.
Logging data was achieved by maintaining an internal array of the actions taken, at the level of individual button-presses. (See below, Figure 6.2.) This table was written out to file at the end of the run. Writing to file during a run could have caused brief interruptions in the continuity of the game.
Replaying of runs selected through the help screen was implemented by reading in the appropriate trace file, and executing the same process as in an ordinary game, with the entries in the trace file being used instead of player's button-presses. This replaying relies on identical simulation steps being performed and the actions being presented at exactly the right time, because, since there is no record of the process variables, any small error would quickly accumulate and disrupt the correspondence between conditions and actions. To get this right was difficult.
As it is, the interface is not portable to any other system. This is because of the non-standard nature of:
However, as far as possible, the non-portable code was kept in one source-code file, which accounts for some 10% of the source code.
It would be a substantial task to re-implement the program on a different system.
The stand-alone nature of the game, with all the necessary information incorporated on line, allowed a user-directed experimental setting with minimal supervision. Identical versions of the game were used on two sites: George House and Charing Cross Tower. In George House (GH), people were not prevented from watching each other, and indeed this was part of the method of stimulating interest. Hence the amount of observational experience obtained by the subjects before starting the game was unrecorded. At Charing Cross Tower (CXT), the more structured environment meant that the subjects had little or no prior exposure to the game.
Unpaid volunteers were requested by word-of-mouth and local posters. The selling pitch was that the simulation was more interesting than, and different from, other computer games. A spirit of competition was fostered firstly by providing a scoreboard as part of the help, secondly by offering a small prize (unspecified at the start) for the highest overall score in a single game at the end of a given period. Four subjects at GH, and two at CXT (other than the author), achieved at least a basic competence allowing them to complete games within a reasonable time-span. We will abbreviate those at GH to R, G, S and M. Those at CXT we will abbreviate to DM and DJ.
As explained above (§6.2.3),
the interaction with the simulation
was entirely through the mouse.
The keyboard itself had no effect, except that
during the course of the experiment, a facility was introduced
so that players could skip short amounts of time (when they
knew in advance that they would not want to take any actions)
by pressing a number key.
The key 1 skipped about 10 seconds-worth of action,
2 about 20 seconds-worth, and so on.
In no case could this increase the score, and
these actions were not recorded in the first experiment.
The primary data consisted of time-stamped records of every legal key-press. This was recorded in a format of five blank-separated numerical fields per line, one line representing one key-press (see Figure 6.2). These files will be referred to as ‘action trace files’ or simply ‘trace files’.
00018 2 3 2 4 Both_Props_Full_Ahead 00021 2 3 5 0 Rudder_Hard_Port 00049 2 3 5 2 Rudder_Centre 00053 1 0 8 1 Scale_over_2 00054 1 0 8 1 Scale_over_2 00056 1 0 2 0 Fix_Ship 00058 1 0 2 1 Centre_Ship 00160 2 3 5 0 Rudder_Hard_Port 00195 2 3 5 2 Rudder_Centre 00201 2 3 5 3 Rudder_Gentle_Stbd 00207 2 3 5 2 Rudder_Centre 00223 2 3 2 0 Both_Props_Full_Astn 00356 1 3 1 0 Stop_Return_to_Help
Figure 6.2: A commented example game trace file
There were two types of action trace file. Each game had its key-presses recorded in a separate file, and each session of zero or more games had the ancillary key-presses (starting and stopping the game, reading the help information provided, etc.) recorded in the same format, together, without the key-presses from the games themselves.
The first field of each trace file gives the number of half-seconds since the beginning of the game, or session. This varies from zero up to several thousand (7200 being equivalent to one hour). The remaining four fields are single digits, representing in turn the sub-display, the column, the row, and the element within that row. These refer to the obvious divisions of the interface screen.
Including the files due to the author, covering the period Oct 8th to Jan 16th, there were over 300 files from GH and nearly 150 files from CXT. These occupied over 1 Mbyte and over 400 kbyte respectively.
All plausible actions were recorded, which included those actions that were impossible or ineffective at the time, and which caused an audible warning to the player at the time of the game, coinciding with the highlighting of the selected area. However, there were some mouse-button-clicks that occurred while the cursor was in an area that was generally inactive, and these were not recorded. Such button-clicks also caused an audible warning at the time of play, but did not cause any highlighting of the selected area of the screen.
In addition to the action trace files mentioned above, there was one file for each site, in which each game has a one line entry. The fields in this file (called the ‘Runindex’) were:
A section of a Runindex is shown in Figure 6.3 (runs by the author later than the experimental period).
calm_weather s 17282750 Apr14-00:29 -546 1036 20262 calm_weather s 17283514 Apr14-00:42 982 998 10535 calm_weather s 17338726 Apr14-16:02 5799 2201 571 calm_weather s 17339722 Apr14-16:19 7044 2456 10535 calm_weather s 17340482 Apr14-16:32 6845 2155 20262 calm_weather s 17341776 Apr14-16:53 7781 3219 1940 calm_weather s 17447710 Apr15-22:19 6637 2363 8818
Figure 6.3: Part of a Runindex file

Table 6.1: Subjects' times, scores, and dates (1989–90)
An idea of the amount of data gathered can be obtained from Table 6.1. “No. Runs” is the total number of games played. Only a few of these were false starts, abandoned after a very short time. “Total Time” is the hours and minutes spent on the games themselves, not counting ancillary activities. “Best Time” is the total time spent at the end of the game that gave the best score, recorded in the next column. “Start Date” and “Best Date” allow the calculation of the calendar period from first trying the game to scoring the recorded high score. “Finish Date” represents the date of the last game played before the (arbitrary) cut-off date of 16th January 1990. There were in fact only a few games played after this, with no-one improving their score. The subject with the highest score, G, was also the one who had put in most hours of practice. For comparison, the author, with substantially more practice than any of the subjects, achieved a score of over 9000. A practical ceiling would appear to be around 10000, though this did depend on the random fluctuation of the arrangement of the mines. A score as high as this was only possible (even in theory) on a small proportion of games. Uncertainties in the scoring system are discussed below (§6.4.1).
Since the analysis of the data involves many stages, it might be helpful to review the overall pattern before describing the details. This overall view, from which some details have been omitted for clarity, appears here as Figure 6.4. In this figure, the rectangles represent types of file, and the ovals represent programs for transforming one type of file into another.

Figure 6.4: Simplified data flow during analysis
It was clear from very early on in the analysis that a single action from a human point of view was not necessarily equivalent to a single key-press. In particular, after practice on the task, short sequences of key-presses were frequently apparent. This happened particularly in the case of manoeuvring the ROV. Because there was no simple effector to turn left or right, players had to create their own sequences of actions that performed the function of turning. Even for the same direction of turn, different sequences were performed in different contexts. When going full ahead with both thrusters, a left turn of a few degrees would most probably be executed by selecting half ahead on the left thruster, followed immediately (0.5 seconds later) by restoring the left thruster to full ahead, using the full-ahead key for either the left thruster or both thrusters together. In contrast, when near a mine, gliding along with both thrusters stopped, a left turn would most likely be executed by selecting the starboard thruster half ahead, and then stopped (or both stopped). Other variations were also observed.
With these turning manoeuvres, the time interval between the unbalancing and balancing actions was crucial to determining the magnitude of the effect of the action. Due to the delayed response of the thrusters, leaving an interval of 1 second produced an effect approximately four times the size of the effect produced by an interval of 0.5 seconds. Thus, in situations where the former would be an appropriate action, the latter would not, and vice versa—the two were, in effect, different actions. There were other sequences of actions where time interval and order were not important. For example, when recovering the ROV, the first step was to reel in the cable. This was effected by setting the cable tension to ‘grip’ and the take-in speed to ‘fast’; but the ordering and interval of these two actions was immaterial.
Perhaps these considerations could in principle be derived from the data. However, in this study, they were deliberately introduced, as background knowledge, in the attempt to get the best classification of actions possible in the available time.
The problem then remained to find what compound actions actually occur in different players' task performance. This could be attempted by observation and questioning; but, without any objective measure, it would be difficult to assess how much of the resulting discoveries were artificially produced by the biases and preconceptions of player and experimenter. Thus a prime objective was to devise a program to compile a list of these compound actions given only a quantity of raw data. Programs for learning macro-operators in games or puzzles have been devised, but the methods used and quoted (e.g. in [120]) do not explicitly deal with time or dynamic systems, and were thus unsuitable here.
The basic program to perform this was called
summ (for summary).
The program first completed a large table,
of the frequency of occurrence of each key-interval-key, for
intervals between 0.5 seconds (coded 0) and 2 seconds (coded 3).
Two seconds was judged to be a reasonable maximum between two
sub-actions that formed a higher-level action.
The program then wrote out a summary
of the more commonly occurring sequences.
Depending on flags given on the command line, this summary
was either intended as a general summary for human reading,
(see Figure 6.5) or as a list of 4-tuples
specifying key-interval-key sequences and single
replacement keys (see Figure 6.6).
The summary in Figure 6.5 gives on the first line:
and on each of the subsequent lines:
3 3 1 3 relative 0.050 freq :1342 Port_Ths_Half_Ahd
0 3 3 1 2 freq : 17 Port_Ths_Stop Slow_Turn_Stbd_0
1 3 3 1 2 freq : 55 Port_Ths_Stop Slow_Turn_Stbd_1
2 3 3 1 2 freq : 38 Port_Ths_Stop Slow_Turn_Stbd_2
3 3 3 1 2 freq : 31 Port_Ths_Stop Slow_Turn_Stbd_3
0 3 3 1 4 freq : 370 Port_Ths_Full_Ahd Diff_Turn_Port_0
1 3 3 1 4 freq : 66 Port_Ths_Full_Ahd Diff_Turn_Port_1
2 3 3 1 4 freq : 11 Port_Ths_Full_Ahd Diff_Turn_Port_2
0 3 3 2 2 freq : 24 Both_Ths_Stop Slow_Turn_Stbd_0
1 3 3 2 2 freq : 70 Both_Ths_Stop Slow_Turn_Stbd_1
2 3 3 2 2 freq : 65 Both_Ths_Stop Slow_Turn_Stbd_2
3 3 3 2 2 freq : 55 Both_Ths_Stop Slow_Turn_Stbd_3
0 3 3 3 1 freq : 228 Stbd_Ths_Half_Astn Pure_Turn_Stbd
1 3 3 3 1 freq : 75 Stbd_Ths_Half_Astn Pure_Turn_Stbd
3 3 3 3 2 freq : 9 Stbd_Ths_Stop
Figure 6.5: A fragment of a summary
3 3 1 3 0 3 3 1 4 0 3 3 0 3 3 1 3 0 3 3 3 1 0 3 0 1 3 3 1 3 1 3 3 1 4 0 3 3 1 3 3 1 3 1 3 3 3 1 0 3 0 1 3 3 1 3 2 3 3 1 4 0 3 3 2 3 3 1 3 2 3 3 3 1 0 3 0 1 3 3 1 3 3 3 3 1 4 0 3 3 3 3 3 1 3 3 3 3 3 1 0 3 0 1Figure 6.6: A fragment of a replacement chart
One deficiency with this basic summary program was that
it could not deal with sequences of more than two actions.
This was overcome by using the program iteratively.
First a basic replacement chart was made.
Next, actions were fed through a filter that
makes the changes specified in the first chart.
This program was called actrace
(not shown in Figure 6.4)
from its effect of changing the
actions in the trace file.
The output of this filter was then fed in to
summ again, giving a second chart,
some of whose input keys may have been new composite ones.
A C-shell script (named chart) was written
to govern this iterative process.
In the final version of chart,
the first application of summ output only more common
sequences, and two subsequent iterations included
progressively less common sequences.
The typology of actions is further discussed below (§6.4.2).
The trace files only had information concerning
the actions taken, not about the situations.
The files had therefore to be expanded before
analysis to include full details of the situation,
and this was done by a program called exp,
which was a modified version of the simulation program,
without the graphics or interaction.
The input was an action trace file, and the output was
a binary file containing all the data on which
the displays were based for each half-second step.
This produced an increase in
the file size of a factor of 250–300.
(Thus it would be quite impractical to
store many of these expanded files on disk.)
An expanded file also permitted a more flexible form of replay. Replaying from the trace file was possible, but it was only one-way (forwards), and took considerable time to execute, since all the original mathematics have to be performed. With an expanded file, on the other hand, one was able to jump to any place in the game, stop, or go backwards. This proved to be a help in getting an intuitive feel for what the various subjects were doing. It allowed an observer to study the circumstances of a certain action in a flexible, easy way.
The expanded file then had its actions modified in
accordance with the required replacement chart.
The program that effected this was called actrep
(for action representation).
This was done twice, in series,
so as to enable longer sequences to be converted
than would be possible with only one application.
As well as the explicit actions, there was also the question of a reasonable human representation of the null action. The original expansion gave null actions for every time step (0.5 seconds) where there was no explicit action. Since one of the priorities of the simulation was to get away from an over-dependence on critical timing, it seemed unreasonable to class the time steps immediately preceding an action as null—after all, the player may have just been a bit slower than intended or desired. A thinking-time parameter was therefore introduced, imagined to be around 1 to 3 seconds, and for this amount of time around an action no null actions were passed on. This was tried with thinking time extending only before, or before and after, any action. Another way of describing the purpose of this would be to say that we want null actions to be registered when everything is fine, not in the thick of hectic action. Compare this with Card et al.'s ‘M’ operator (“mentally prepare”) in their Keystroke Level Model [20]. The value for the ‘M’ operator is given as 1.35 seconds.
Having thus reached the stage where the representation of actions was altered to what we may suppose is a more human-like form, it was left to decide what to do about the representation of the situations. Whereas the basic representation of actions was unequivocal (discrete key-presses), the representation of situations implied by the interface was not completely clear (see below, §6.4.3). The approach taken was to remain agnostic about the exact information provided, because in any case the aim of the methods investigated was to be able to tell when a representation was closer to the human one.
Having decided on a representation to test,
the selection of the attribute values in that
representation was done by the program called
sitrep (for situation representation).
The representation was defined by a hand-crafted file, listing
the attributes to be selected (see Figure 6.7).
(RT01) (RT2)
2 1
rov_degrees rov_off_head
rov_target_head 4
4 rov_height
rov_height rov_speed
rov_speed rov_r
rov_r rov_target_range
rov_target_range 4
4 sub_display
sub_display rov_av_revs_demand
rov_port_revs_demand rov_turn_demand
rov_stbd_revs_demand rov_status
rov_status
3
3 0 3 0 1 Pure_Turn_Stbd
3 3 1 3 Port_Ths_Half_Ahead 0 3 0 3 Pure_Turn_Port
3 3 3 3 Stbd_Ths_Half_Ahead 0 0 0 0 NO_KEY
0 0 0 0 NO_KEY
Figure 6.7: Example representation files
The three sections of situation attributes are respectively
integer variables, floating-point variables,
and qualitative variables.
The fourth group is a selection of actions (classes) in
the single ‘decision’ attribute, along with their key codes.
Lower-level representations
(such as the one marked (RT01))
contain only attributes that are explicitly
present in the unmodified expanded data.
Higher-level ones (such as the one marked (RT2))
have some quantities that are not explicitly present in the
original data, and therefore have to be calculated on the spot.
In the example case, rov_off_head is the relative
bearing of the closest active target from the ROV.
It is calculated from rov_degrees,
the heading of the ROV, and rov_target_head,
the true bearing of the target from the ROV.
Rov_av_revs_demand and rov_turn_demand are
calculated from the two demands in the old representation RT01.
Pure_Turn_Stbd is a combination of
Port_Ths_Half_Ahead and Stbd_Ths_Half_Astn,
as shown in Figures 6.5
and 6.6 above.
Pure_Turn_Port is defined similarily.
In the expanded file,
the number of half-second intervals where there was
no key-press outnumber those in which there was.
Any individual key, therefore, is greatly outnumbered by
what might be regarded as null actions (NO_KEY).
It would be unhelpful to include all these as examples
for a rule-induction program, for two reasons:
For these reasons, sitrep also performed the function of cutting out a large proportion of null actions. The precise proportion was controllable via a command-line parameter, or settable to a ‘good guess’ value dependent on the number of non-null keys being investigated.
After sitrep had output the selected data
(now in readable, ‘ascii’ form), it was a straightforward
matter to format this for a rule-induction program.
This was done by a program called indprep
(for induction preparation), which had a
command line flag determining which rule-induction program the
data should be prepared for, since there is no standard format.
Other flags determined whether indprep should output a file
of examples (data) only, attributes (names), or both together.
As an example, the attribute file and
example file (containing 30 examples)
for subject G, representation RS2
(see Figure 6.9, below),
interval 4 (as in Table 6.2 below),
is given here as Figure 6.8.
In each example, there is one entry for every attribute,
in order.
**ATTRIBUTE FILE**
rov_off_head:(FLOAT)
rov_u:(FLOAT)
rov_v:(FLOAT)
rov_target_range:(FLOAT)
rov_height:(FLOAT)
rov_speed:(FLOAT)
sub_display:ship rov umb env;
rov_av_revs_demand:f_astn hf_astn h_astn q_astn stop q_ahd h_ahd hf_ahd f_ahd;
stage:initial searching placing far close final pull_in infringe;
class:Both_Ths_Full_Astn Both_Ths_Half_Astn Both_Ths_Stop Both_Ths_Half_Ahd
Both_Ths_Full_Ahd NO_KEY;
**EXAMPLE FILE**
48 7.98 0.00 1000.0 48.0 0.00 ship stop initial NO_KEY;
3 7.97 0.00 418.9 48.0 0.00 ship stop initial NO_KEY;
11 7.94 -0.22 320.3 48.0 0.00 ship stop placing NO_KEY;
30 7.60 -0.11 231.4 48.0 0.00 ship stop placing NO_KEY;
52 4.08 -0.01 150.4 34.5 4.14 rov stop far Both_Ths_Full_Ahd;
15 3.21 -1.08 134.9 34.5 3.39 rov f_ahd far NO_KEY;
15 3.19 -0.27 50.6 30.2 3.68 rov f_ahd far NO_KEY;
21 1.34 -0.72 16.1 12.1 1.53 rov f_ahd final Both_Ths_Stop;
15 -0.13 -0.11 14.1 8.5 0.88 rov stop final Both_Ths_Half_Ahd;
28 0.30 0.26 11.9 3.0 0.56 rov q_ahd final NO_KEY;
-56 0.24 0.56 15.7 2.0 0.61 rov q_ahd final Both_Ths_Half_Ahd;
-8 1.04 0.33 8.7 1.8 1.09 rov h_ahd final Both_Ths_Stop;
-49 0.13 0.25 4.5 2.1 0.29 rov stop final NO_KEY;
-20 -0.12 0.07 6.1 2.6 0.15 rov stop final Both_Ths_Stop;
27 0.06 -0.06 6.9 2.8 0.08 rov stop final Both_Ths_Stop;
-15 -0.15 -0.08 6.8 3.0 0.16 rov stop final Both_Ths_Stop;
56 0.09 -0.24 4.3 3.4 0.26 rov stop final NO_KEY;
-5 -6.69 -1.41 65.7 19.7 7.04 ship stop pull_in NO_KEY;
2 -0.67 1.12 1000.0 36.3 1.31 ship stop searching NO_KEY;
2 -1.44 -5.76 1000.0 37.9 6.86 ship stop searching NO_KEY;
2 0.59 -7.44 1000.0 39.2 7.98 ship stop searching NO_KEY;
-157 0.62 -8.28 487.4 39.8 7.57 ship stop searching NO_KEY;
-169 0.55 -7.37 465.4 40.3 8.36 ship stop searching NO_KEY;
178 0.61 -8.21 463.9 40.9 7.51 ship stop searching NO_KEY;
166 0.58 -7.49 483.1 41.5 8.18 ship stop searching NO_KEY;
-132 -5.27 -6.18 424.4 42.5 7.37 ship stop searching NO_KEY;
-129 -7.05 -4.36 229.7 45.2 7.55 ship stop placing NO_KEY;
-109 -3.64 -2.69 119.6 47.0 4.59 rov stop far Both_Ths_Full_Ahd;
5 1.94 1.50 80.1 47.4 2.46 ship f_ahd infringe NO_KEY;
-14 2.78 0.88 60.1 47.7 2.91 ship f_ahd infringe NO_KEY;
Figure 6.8: An instance of an example and attribute file for the CN2 induction program.
Three rule-induction programs were readily available: C4, ID3 and CN2 [23] (for a description and comparison of some algorithms, see [39]). (The version of CN2 used was developed by Robin Boswell of the Turing Institute, as part of ESPRIT project 2154, the Machine Learning Toolkit.) C4 is based on the ID3 algorithm, and like ID3, produces output in the form of decision trees. When C4 was tried on larger data sets (a few thousand examples) it was found to be excessively slow, taking several hours to run, and on the largest ones it ‘crashed’. It was then decided against as a primary tool. Of the other two, CN2 was chosen as the more appropriate, because
There are two major modes of CN2: ordered and unordered. The ordered mode produces if–then–else rules, where, when the rules are being executed, the search through the rules stops when a match is found. In effect, later rules have as part of their conditions the negation of the conditions of earlier rules. This means that the ordering of the rules is significant, and that the application of any rule cannot be understood out of context. Thus, from the point of view of human comprehensibility, there is little advantage of the ordered mode over a decision tree, as in ID3.
The unordered mode produces if–then rules where the condition is made up of a conjunction of conditions on any of the attributes. Disjunction (‘or’) is produced by having a number of rules all for the same decision class.
A standard method for generating and testing rules was adopted. This is to take a training set of data, and use the program to generate rules, then to take the training set and unseen test sets, and to evaluate the prediction performance of the rules on these data. This process leads to figures for the effectiveness of the generated rules for each decision class considered, and an overall prediction performance figure, which must be carefully compared with the prediction performance of a default rule before being able to assess its value.
The first comparison of representations was between those given above in Figure 6.7 (see also §B.1). This used CN2 in its ‘unordered’ mode, where the rules produced are independent of each other (the order of them is immaterial). This was, however, a new facility to be added to CN2, and it was still to be fully tested.
The example was interesting, because although it looked
as if the second case performed better, in fact,
comparing the prediction performance of the rules
with the default rule reveals that these rules
did not score better at predicting human actions
than the rule “do nothing all the time”.
The default rule is that all examples belong to the modal
(most frequent) class, which in these cases is NO_KEY.
So we obtain a figure for the default rule by
summing the actual frequencies of NO_KEY and
dividing by the total number of examples.
In the unordered case, with the representation RT01,
the prediction performance of the rules
even on the training set was very close
to the prediction performance of the default rule.
On the test data, the prediction performance
was substantially worse than the default.
Looking at the individual rules (§B.1),
the second rule makes sense in that it is saying that
when the first key-press of a ‘pure turn’ has been
carried out, the corresponding part then needs to be done.
In contrast, the fourth rule is quite implausible.
Simply from considerations of symmetry, we could
call into question a rule where there were symmetrical
conditions but an asymmetrical action.
In this case, the rule must be presumed to have emerged
from a coincidence in the data.
The figures after the rule indicate that it is not very
well supported even in the training data: we might
expect it to be even more poorly supported in test data.
But many of the other rules can be criticised in a similar way.
With the new representation RT2, the overall accuracy
figures are not much different from the default rule figures.
But the rules look much better than
in the representation RT01.
Firstly, there are fewer of them, which is an advantage.
Secondly, most of them can be made good sense of.
After discovering some unresolved issues
with the unordered mode in CN2,
the same data were reworked using the ordered mode
(see Appendix B.2).
This appendix illustrates the kind of rules
obtained using the ordered mode.
Briefly, the test data results on the representation
RT01 still are below the default values.
For the representation RT2, the results
just manage to be better than default.
The subject with the longest experience was G, at George House.
His trace files were grouped into four equal calendar time
intervals: 02, 03, 04 and 05, in order from earlier to later.
The calendar divisions are October 19th, October 30th,
November 10th, November 22nd, and December 4th.
The data was fed through the actrep filter,
using action replacement charts generated for
the subject G from all his games together.
The 05 games (including the subject's best scoring game)
were used for generating rules.
Rules were generated on three representations of
ROV speed control, named RS0, RS1 and RS2.
(See Figure 6.9.)
(RS0) (RS1) (RS2)
2 1 1
rov_degrees rov_off_head rov_off_head
rov_target_head
3 5
5 rov_target_range rov_u
rov_u rov_height rov_v
rov_v rov_speed rov_target_range
rov_target_range rov_height
rov_height 3 rov_speed
rov_speed sub_display
rov_av_revs_demand 3
3 stage sub_display
sub_display rov_av_revs_demand
rov_port_revs_demand 6 stage
rov_stbd_revs_demand 3 3 2 0 Both_Ths_Full_Astn
3 3 2 1 Both_Ths_Half_Astn 6
6 3 3 2 2 Both_Ths_Stop 3 3 2 0 Both_Ths_Full_Astn
3 3 2 0 Both_Ths_Full_Astn 3 3 2 3 Both_Ths_Half_Ahd 3 3 2 1 Both_Ths_Half_Astn
3 3 2 1 Both_Ths_Half_Astn 3 3 2 4 Both_Ths_Full_Ahd 3 3 2 2 Both_Ths_Stop
3 3 2 2 Both_Ths_Stop 0 0 0 0 NO_KEY 3 3 2 3 Both_Ths_Half_Ahd
3 3 2 3 Both_Ths_Half_Ahd 3 3 2 4 Both_Ths_Full_Ahd
3 3 2 4 Both_Ths_Full_Ahd 0 0 0 0 NO_KEY
0 0 0 0 NO_KEY
Figure 6.9: Three slightly varying representations for ROV speed control
These were intended to be progressively more human-like.
The CN2 parameter ‘star’ was set to 10,
and ‘threshold’ was set to 10, and ordered mode was used.
The rules generated were then tested against the data
from each of the divisions, 02, 03, 04 and 05.
The results are summarised in Table 6.2.
The numbers in the body of the table are the percentage points
difference between the prediction performance of the rules
and the prediction performance of the default rule.
The high scores for the interval 05 are due to
the fact that 05 interval provided the training data.
The default rule generally scored around 60% to 70%,
and the 05 interval absolute scores are over 95%.

Table 6.2: Testing rules for interval 05, subject G, against defaults
There are two trends immediately apparent in this table. One is that RS1 and RS2 perform substantially better than RS0, with RS2 being slightly the better of the two. The other is that whatever rules were induced for the interval 05 were not much in evidence during interval 02, and progressively became more so. This is reassuring in two ways: firstly it suggests that the rules found are not imaginary, or due to random effects; and secondly that these rules are being adopted increasingly as time goes on. This is consistent with a common-sense view of learning.
An alternative way of dividing up the examples
is into sets of similar size.
This was done with subject M, but otherwise the
same procedure was followed as with subject G.
Table 6.3 summarises the results for M.

Table 6.3:
Testing rules for interval 0499–0508, subject M, against defaults
The rules were again constructed on the data containing the highest score, which in this case was the 0499–0506 interval. The same general trend is apparent with respect to the representations as above.
The prediction performance of the rules across time again shows a build-up of prediction performance towards the training interval; but now also shows a subsequent decline. This could in principle be due either to a decline in task performance, with the acquired rules not being followed as strictly as before, or due to new rules supplanting the old ones. In this table, the overall accuracy figures have also been included, to show that there is in fact no rise in overall accuracy between the fourth and fifth intervals. The rise in the relative figure is due to a fall in the default rule accuracy, which, in this interval, implies that there were fewer null actions.
G and M were both in George House, and took an interest in each other's games. It is perhaps not surprising that similar patterns emerge in their results, and that a representation that was able for one of them to produce rules performing substantially above the default rule, should also be able to do so for the other. This is not so, however, for DM, one of the Charing Cross Tower subjects. His results, derived by exactly the same process as the above results, are summarised in Table 6.4.

Table 6.4:
Testing rules for interval 065–1, subject DM, against defaults
This table suggests that the rules do not reflect the actual rules being used by this subject. The first two columns suggest, rather more strongly, that the rules are substantially different from those used at the earlier stages of learning. The pattern for all the representations is similar, and this suggests that none of RS0, RS1 or RS2 cover the attributes actually used by subject DM. However there is, if anything, a slight favouring of RS1 over RS2, contrary to the other subjects. Another representations would have to be found, if we were to find results as satisfactory for DM as for G and M.
A number of issues arose in the previous section that will be further expanded here. This leads on to a review of what was learnt from this experiment, and arguments pointing towards what needed doing next.
The reliability of the total score as a measure of experience was compromised by the random number and distribution of the mines. The number was random to ensure that the search could not be broken off without covering all corners of the minefield, which would enable an unfairly quick return, as well as being unrealistic. In an attempt to counter this problem, the scoring system allotted points for each mine found. However, the scoring was fixed before a great deal of experience had been gained, and it was subsequently discovered that experienced players gained more points by dealing with a mine than they lost through the extra time taken. Hence higher scores could be obtained when there are more mines, and the actual highest score of a player depended not only on their skill, but also on their luck in the allocation of mines.
A further problem with the reliability of the scoring comes from the catastrophic nature of an accidental mine explosion. A subject could be performing very well, but such an explosion would cause the total score to be highly negative. Thus good scores would be mixed in with very bad ones. For these reasons, it was felt that any graph of raw scores over time would be of little value.
The psychological impact of the scoring system is difficult to evaluate, and this will not be attempted. It may be noted that the task would change depending on whether the subjects were instructed to achieve the single highest score, or to achieve the best overall average score, or somewhere in between these two extremes. The emphasis in the experiment was only on achieving the highest single score, and this meant that when a subject accidentally blew up a mine, or did something that led to a long delay, the game was sometimes abandoned at that point, presumably on the grounds that a high score could not be obtained.
Detailed consideration of the task, a priori, suggests several possible types of action that the player might perform. Correct identification of the type or types of action performed is potentially important to any analysis of this kind, since an analysis designed to find certain kinds of action might fail to find other kinds. These could include:
Of these, the methods of the current study can only deal with those actions that fall into the second category, i.e., those that follow a rule. Therefore the success of the rule-induction depends, as well as on the quality of the representation, on the extent to which the actions analysed belong to this class, as opposed to one of the other classes.
Dealing first with slips, we may note that
some of the unintended key-presses have no effect.
These can be taken out in the process
of analysis, by actrep.
Other slips will contribute noise to the data,
with the result that the induced rules will be less
accurate and perform worse on prediction.
With knowledge-based processes, we could expect in theory to be able to induce rules if we know all the factors that are taken into account, and the intermediate concepts involved, in the knowledge-based process. This would be comparable with defining the terminology with which to construct an expert system, and would involve defining appropriate higher-level concepts in terms of lower-level ones: there is nothing in general to prevent this being done, but it may require much knowledge or theory about the knowledge-processing mechanisms. We are unlikely to be able to capture much of this level with the relatively straightforward methods that are used in the present study.
Information-seeking actions could be of two types: either actions directly altering the selection or presentation of information, or actions affecting the simulation itself. The information selection actions may reveal something about the information being used or considered at a particular time: however, in the first version of the simulation game, there was still so much information present concurrently (especially graphical) that our knowledge of the player's information usage is advanced only slightly, if at all. This approach to understanding the player had yet to be explored. More difficult to formalise are the actions which may be characterised thus: “give it a nudge to see how much it moves, and then you'll know how much to push it”. If this kind of action were being used, it would tend to obscure rules about how large an action to make in differing circumstances, since the initial nudge might be similar in the different situations, with only the following action differing; and that action not differing on the basis of the static quantities, but on the dynamic response of the thing that was nudged. However these information-seeking actions are dealt with, there are likely to be fewer of them the more practiced the subject is, since the desired quantities will be more likely to be known. For exploratory actions, again, the more practiced the player is, the less likely they are to occur. This reinforces the desirability of concentrating on well-learnt situations.
There is also a philosophical aspect to the question of the nature of actions, i.e., how we are to represent actions in general. This has a large effect on the methods of analysis. Firstly, we could consider an action as directly corresponding to the state that it brought about. An analysis on this basis will work if every situation has corresponding unique control settings appropriate to that situation. For example, if the ship is moving forwards at a reasonable speed, and the desired direction is more than (say) 15 degrees to port, then the desired rudder setting is hard port. This fits into the paradigm of pattern recognition and means-ends analysis: knowing how things ought to be leads to appreciation of the discrepancies between the actual and the desired state, and thence to steps to reduce the difference.
A second approach is to consider all actions as interventions, not necessarily determined by the objective state that is brought about. One can characterise the above example in this way, by adding that if the rudder setting is not hard port, then set it to be so. In this second approach, the dependency of actions on the current control setting is emphasised. It may be that this is more appropriate for serial actions, and explicit rules; while the first may be more appropriate for parallel actions without conscious attention.
Which approach is taken has implications for treating null actions. It is evident that at times, an operator is consciously not intervening, because everything is within the operator's limits of acceptance. If a ‘desired state’ approach is taken, the concept of action has no default: there is always some desired control state; every situation has some appropriate response, even if this does not entail altering the controls. If the correct response is not known, some measure of closeness will give a situation which is similar, and whose action can fill the unknown. With an ‘intervention’ approach, on the other hand, there is a default action of ‘do nothing’, in just those cases where there is no appropriate intervention. This does, however, raise the problem of granularity of actions, in that it is far from clear how many null actions to attribute to any given space of time free from positive actions.
Choosing exclusively one or the other approach seems over-rigid. However, purely for ease of analysis, we may note that one can always express desired-state actions in terms of interventions contingent on the current state of the controls, as well as the outside world; whereas one cannot always express interventions in terms of desired states. For this reason, the analysis in this study is in terms of interventions.
The choice of approach with respect to actions is to some extent a pragmatic rather than a theoretical one. Constructing a complete theory incorporating all these types of actions would be a huge enterprise, encompassing a great deal of cognitive psychology. The choice of rule-governed actions may be justified as a starting point firstly by considering the relevance of regularities to the kinds of applications we are considering (and the relative lesser relevance of other actions); secondly by recognising that knowledge-based actions have been the subject of much investigation, both in AI and in learning systems (e.g., [41]); and thirdly by discounting the practicality of investigating information-seeking, exploratory and whimsical actions as being a much more difficult place to start.
The information displayed at the interface falls into two sections. The ‘sensor’ section contains only numeric data displayed as numbers, and this clearly defines a set of primitives which we can take as the basic representation of these quantities. But for the ‘graphic’ sections, it was much more difficult to decide what was being displayed. One view might take the content of what is displayed to be the system variables that are used in the construction of the graphical display. However, the inference of other quantities is so immediate and intuitive, that it is difficult to avoid the idea that this information is also being presented in the display.
A simple example concerns the ROV's heading. One numerical sensor gives, in whole degrees, the heading of the ROV in the conventional way (000 to 359 clockwise from North). Another sensor gives the bearing of the closest unknown or unsafe target. There was no explicit offering of the bearing of the closest target relative to the ROV's head, and yet this was obviously going to be a significant quantity, and it was one which was immediately apparent (though in an unscaled form) from the ROV graphic display, as long as the target was within the viewing region. A very close parallel exists with the ship's heading and associated quantities. In the case of the ship, the relative bearing can be immediately seen from the general position indicator.
Thus, it is a real difficulty with graphic displays to achieve any degree of objectivity about what information is being provided, and hence, for any higher-level representation, how much information processing is being done by the interface and how much is being done by the human. The uncertainty of interface design remains unclarified in this case, because there is no a priori way of being sure that you have presented the information that you wish to present effectively.
One possibility for formalising some graphic information is to focus on significant events, and allow that the display effectively gives a rough idea of time-until-the-event. Of course, this need not be displayed as such, but the combination of perceived distance and motion can easily be seen as giving a time measure. Such time measures have an established history in theories of mariners' actions in collision avoidance. For a discussion of the “RDRR” criterion (Range to Domain over Range Rate) and its use in an intelligent collision avoidance system, see [15, 27, 28, 30]. A slightly simpler concept, “TCPA” (Time to Closest Point of Approach) is also used in many places (e.g., [111, 129]).
Another difficulty with representation arises in connection with the manoeuvring of the ship. The general position indicator (the upper graphic display present at all times) sometimes confronts the player with a pattern of targets that have complex implications. What is the best place to stop the ship, so that the most targets can be dealt with at once, and leaving the ship in an advantageous position to proceed? To come to a decision on this clearly requires an overall view of the disposition of the targets, and since the precise pattern of targets repeats itself extremely rarely, any routinizing of these decisions could not be linked to precise identity of the conditions.
It is plausible to consider this as an example of knowledge-based behaviour, since in the time available people are likely to still be trying out different approaches, and developing ways of categorising arrangements of targets into groups indicating the best action to take. In the author's experience, a considerable amount of conscious thinking goes on in the consideration of where to stop the ship, though this thinking may not be verbal. Alternatively, one could consider it as a visual pattern-matching process. An attempt to analyse this in symbolic terms would inevitably involve many pattern and shape concepts, which would be difficult to derive from data such as is in the present study, because this experiment was not designed to address pattern issues. In the longer term, we might be able to ascertain which attributes were relevant to ship positioning decisions, and we might be able to devise a method of learning how to recognise values of these attributes from the original Cartesian data of the simulation. These questions are difficult enough to constitute independent problems, and since there is little necessary overlap with the present lines of enquiry, issues involving the processing and use of patterns are not followed here.
Reviewing the state of results at the end of the first experiment:
The most salient need was therefore to overcome the problem of generating better representations of situations, in the absence of automated methods. Three ideas had clear merit.
Also having discovered something about the turning of the ROV, new higher-level controls could be made, which could make the task easier. To compensate for this, weather could be introduced, as was originally planned. These steps would change the task substantially; but since the idea of the task in the first place was only to provide a sufficiently complex and interesting task in the chosen field, this should not be detrimental to the experiment as a whole.
The experience from the first experiment, and the directions emerging from it, which have just been summarised, stimulated a number of changes to the task, which will now be discussed.
Costing the information was the main identified potential means of obtaining data about what information the operator was actually using at any time. Duncan & Prætorius [33] report experiments involving the withholding of plant information relevant to diagnosing faults, with the aim of checking verbal reports from the operator about how they performed the diagnosis task. Duncan [32] cites Marshall et al. [76] as originators of the technique of withholding information. But the task in the present study is quite different from the kinds of diagnostic task studied by Duncan and others. In the sea-searching task, if the information was automatically switched off before each time step, the operator would have to ask for all the information needed before making any action, and the task would be unrecognisably different, and slower. On the other hand, if information could only be switched on permanently, and asking for some information resulted in its being present at all times thereafter, information used in situations that had passed would be mixed in with information freshly required, and the experimenter would be in a situation little better than the original one, where all information is shown at all times. The sea-searching task needed the capability to switch the information both on and off, and the operator had to be induced to switch off the information not required at the time. The obvious method of inducing this was to deduct some score for each time interval for each sensor used.
The implementation of this information costing required considerable alteration to the program code. For each sensor, a price had to be associated with it, and a variable to hold the information indicating whether that sensor was currently on or off. Also, a simple means of turning sensors on or off was needed, and this was done by a mouse-click on the appropriate area. When a sensor was off, the price was displayed instead of the sensor value. To guard against careless misreading, all prices were prefixed by “pr”, whereas all sensor values were simply numerical, without any prefix. The prices of the sensors that were on were summed, and displayed as the information rate—that is, the number of points deducted per half second for the collection of currently selected sensors. Another display in the scoring panel kept a running total of the total cost of information from the start of the run.
To get an idea of the magnitude of the information cost, the price of the different sensors can be compared to the time penalty, which remained the same as in the first experiment at 1.0 points per half second. The general position indicator price was set at 6.0 (points per half second), and the other graphic displays at 3.0, since these were the sensors that were most problematic for analysis. The other sensors were generally set at 0.2, except for the relative heading of the ROV, which was set at 0.5, on the grounds that the information used to calculate the values were given by two other separate sensors. Using typical values from the previous experiment, this would mean that if all the sensors were left on for a whole run, an information cost of perhaps 40000 would be accumulated—far more than the total positive scores available. Thus, leaving the graphics on all the time was removed from possible competitive strategies.
Clearly, introducing this information costing was going to change the task considerably. Firstly there was the added load of deciding what information was wanted, and using the mouse to turn the appropriate sensors on and off. But secondly, if, as intended by the experimenter, most of the sensors were turned off, there would no longer be the chance of opportunistic use of information that happened to catch the eye. One intended benefit from this was to constrain the methods used to be more consistent over time: having decided on necessary information, a player would not get the opportunity to notice fortuitously that other information would be useful. Thirdly, assuming the graphic sensors were used much less, the strategies that were found to be appropriate for digital displays might differ from those appropriate for use with graphic displays.
If graphic displays were a hindrance to analysis, one might ask, why not do without them altogether? In this game, as in so many learnt skills, it was recognised that the needs of the learner and the needs of the expert were in all likelihood going to differ. Shorter learning times were better in all ways for the experiment, and it was difficult to imagine a subject learning the task quickly with an interface consisting only of digital data. But even practiced subjects get confused sometimes, and if there were no graphic display to fall back on, there would be a risk that they might remain thoroughly disoriented, or possibly even give up the game or be generally discouraged.
Given that the graphic displays would be used at the outset, the scoring system needed careful thought. The decision taken was to start with the full scoring system in place, but to issue instructions to subjects that they were not even to consider the scoring until they felt reasonably competent at performing the main task, that is, without the added task of information management. If the large mounting negative score was felt to be a distraction, the display could be turned off, just like the other information displays. Since the negative score was necessarily going to be larger than in the first experiment, the completion bonus was raised to 20000, so that subjects would feel the satisfaction of scoring positively at an earlier stage.
Since the first experiment had analysed the ROV turning, and since it was the most obvious inadequacy in the interface, it was decided to implement better turning effectors for the ROV. To maintain some continuity and comparability with the previous experiment, these effectors were implemented in a way similar to the way they were implemented by humans, and still using the same underlying simulated mechanisms. This meant that, on one button-press, the ROV motors had to be set asymmetrically, and without a further button-press, they had to be brought back into balance at a later time. Thus, the balancing action was implicit in the complete action. This required the ability to store button-presses for execution at a later time, also ensuring that when the time came for execution, it would not be interfered with by other button-presses.
This was implemented, and worked successfully. The unbalancing of the ROV motors was done in a way that had been found common in the first experiment, and this necessarily depended on the state of the motors at the time. This meant that turning actions and speed control actions were interdependent. The opportunity was taken to rearrange the other ROV controls, so that sensors relevant to each other were closer together.
The resultant appearance of the display is shown in Figure 7.1. The ROV sub-display is shown, with most of the sensors turned off.

Figure 7.1: The interface in the second sea-searching experiment
Similar changes were required by the desire to introduce weather. In order to have all the relevant information present in the trace files, the actions of setting the weather needed to be recorded in the same way as other actions. But allowing the player to alter the weather would risk tempting them into exploring a whole range of situations, most of which would be irrelevant to their task performance for the still relatively short experiments that were planned (very short compared to a process operator's training). Developing and practising skill for a wide range of weather situations would need substantially more time than envisaged in this experiment.
Setting the weather required the ability to predefine some actions, to be taken and recorded, in a separate file. This was achieved by reading in that file into a space to be shared by implicit actions described above. Further details are not given here, as that would need reference to the source code. As it happened, the weather facility was not needed, since the subjects did not attain a sufficiently stable and high degree of skill.
As has been noted, it was believed to be desirable for subjects to spend longer at the task than the subjects of the previous experiment. Either nominal payment, or time taken from working hours, would be highly desirable, and this, in turn, limited the scope of the experiment.
Thirty hours was the chosen target for total experiment duration, of which most would be actually playing the game, and a part, especially at the beginning, would be familiarisation by reading the help provided.
The possibility of the General Position Indicator being off highlighted the fact that, in the first experiment, some information was only presented graphically, with no corresponding digital measurement. So as to enable the player to navigate around the area without needing to use the General Position Indicator, North and East sensors were introduced, giving measurements relative to the starting point. The mine area was also moved slightly, so that the boundaries were multiples of 500m north and west from the starting position.
The help given by the help screens was changed to reflect the other changes made. For reference, the contents of the help screens are given in Appendix A.
The modifications to the program meant that, as well as the effectors recorded in the previous experiment, the trace records included all the key-presses having the effect of turning sensors on or off. From these records, knowing that all the sensors were originally off (except the scores, which were all on), one could deduce the state of visibility of all the sensors at any time, and this from only the trace files, without needing to recreate the simulations for that run.
So that we can discuss collections of sensors, we shall here use the term “chord”, by analogy with the musical term,1 to mean a collection of sensors that are simultaneously available—in the current interface, visibly. For instance, one chord commonly used (later on) by subject AJ was the combination of the three sensors that indicate the ROV height, range from target, and relative heading of target.
Analysis of these chords needed a means of
representing and manipulating them on the computer.
Since there were less than 24 sensors in each of
the three sub-displays, it was possible to hold
the chords in the form of 32-bit integers,
where there was one bit for each of the sensors that
could be on or off, three bits showing what sub-display
was current (each sub-display having different sensors),
a further bit showing whether the graphic display for
that sub-display was on or off, and another showing
whether the general position indicator was on or off.
Here these are written in octal format.
The first digit (after ‘ch’) contains the bits
indicating the status of the graphic sensors,
with the first digit being 1 if the sub-display graphic
is on, 2 if the general position indicator is on,
and 3 if both are on.
The second digit is 2 for the ship sub-display,
3 for the ROV, and 4 for the cable.
The last 8 digits (24 bits) are for the individual sensors,
one digit having information on up to 3 sensors
(the individual bits of the octal number).
A 7 indicates three sensors on;
a 3, 5 or 6, two sensors, and a 1, 2 or 4, one sensor on.
Thus, as in Figure 7.2,
the chord ch0347372742 indicates the ROV sub-display,
with graphics off, and 15 sensors on (which was all of them).
The chord ch3200000000 indicates the ship sub-display,
with both its own graphic display and the general position
indicator on, and all other sensors off.
A program called tracechord was written by the
author to analyse the chords from the action traces.
The action trace files, which were in the same format
as in the previous experiment, were passed to
tracechord, which kept a track of which sensors
were visible, identified the chords used,
and added up the number of actions
performed while each chord was showing.
Figures 7.2 and 7.3
show output from tracechord for the two subjects,
side by side.
Each entry shows the chord code,
the number of effector actions performed when this chord
was operating, and the proportion of the total represented
by this number.
AJ MT
ch0347372742 1331 0.4087 ch0347372742 1374 0.4883
ch1347372742 885 0.2717 ch3277633303 605 0.2150
ch3277633303 600 0.1842 ch1347372742 538 0.1912
ch0400766736 241 0.0740 ch0400766736 161 0.0572
ch3200000000 44 0.0135 ch2277633303 127 0.0451
ch2277633303 41 0.0126 ch0400000000 5 0.0018
ch2200000000 32 0.0098 ch1300000000 2 0.0007
ch0300000000 30 0.0092 ch2200000000 1 0.0004
ch1300000000 17 0.0052 ch3200000000 1 0.0004
ch0400766636 9 0.0028
ch0200000000 8 0.0025
ch0400000000 8 0.0025
ch2347372742 5 0.0015
ch0277633303 3 0.0009
ch0343372742 2 0.0006
ch3347372742 1 0.0003
Figure 7.2: Sensor chord usage at the outset
Figure 7.2 shows figures for the first few hours of each subject's practice. The subjects, as instructed, initially left most of the sensors on while they were in the initial stages of learning the task, and there is not a very wide range of chords that were tried. The chords that were extensively used at this early stage were mainly those where most, if not all, the sensors are on. In Figure 7.3 are corresponding figures for each subject's final few hours, except that the list shown for MT omits further chords with effector frequencies down to 1. For both subjects, there were also many other chords used where there were no effector actions, and these are omitted from the figures. In the late chords, we see that the sensor usage of both subjects has changed greatly from the early pattern, and each is markedly different from the other subject's. The frequently used chords have only a few sensors on, and there are many more different chords used.
AJ MT
ch0301000140 901 0.2891 ch1303020700 518 0.1902
ch0200200200 330 0.1059 ch1303020100 235 0.0863
ch0300000000 324 0.1039 ch0300000600 219 0.0804
ch0200000000 310 0.0995 ch0300000000 186 0.0683
ch1301000140 255 0.0818 ch0303020700 149 0.0547
ch1300000000 205 0.0658 ch0400000000 88 0.0323
ch0201200200 166 0.0533 ch0205000000 85 0.0312
ch0400000000 149 0.0478 ch0207200000 80 0.0294
ch0204000000 92 0.0295 ch0400000002 76 0.0279
ch0400000002 68 0.0218 ch0201200002 75 0.0275
ch0207000000 64 0.0205 ch0207200002 64 0.0235
ch0300000040 60 0.0192 ch0200000000 58 0.0213
ch0201000000 47 0.0151 ch0201200000 55 0.0202
ch0206000000 21 0.0067 ch0205200000 54 0.0198
ch0200200000 19 0.0061 ch0300000700 43 0.0158
ch0301000100 17 0.0055 ch0301020700 42 0.0154
ch0205000000 15 0.0048 ch0205200002 39 0.0143
ch0300000140 10 0.0032 ch0301000100 32 0.0117
ch0202000000 9 0.0029 ch0300000100 29 0.0106
ch0201200000 8 0.0026 ch0225200000 28 0.0103
ch0207200000 7 0.0022 ch0235000000 28 0.0103
ch0200000200 6 0.0019 ch0301000700 28 0.0103
ch0300000100 6 0.0019 ch0204000000 27 0.0099
ch0201000200 5 0.0016 ch0207000000 25 0.0092
ch1200000000 5 0.0016 ch0215200000 22 0.0081
ch0207200200 3 0.0010 ch0303020100 18 0.0066
ch0301000000 3 0.0010 ch2400000000 18 0.0066
ch0207000200 2 0.0006 ch2400000002 17 0.0062
ch1206000000 2 0.0006 ch0300020700 15 0.0055
ch2201200200 2 0.0006 ch1301000100 15 0.0055
ch0203000000 1 0.0003 ch0225000000 14 0.0051
ch0206200000 1 0.0003 ch0234000000 14 0.0051
ch0301000040 1 0.0003 ch0237000000 13 0.0048
ch1201200200 1 0.0003 ch2205000000 13 0.0048
ch1204000000 1 0.0003 ch0224000000 12 0.0044
ch2207200200 1 0.0003 ch0301020100 12 0.0044
ch1303000100 12 0.0044
ch0235400000 11 0.0040
ch0303020600 10 0.0037
ch1300000600 10 0.0037
ch2237000000 10 0.0037
ch0201200202 9 0.0033
ch0303000100 9 0.0033
ch1301020700 9 0.0033
ch0201000000 8 0.0029
ch0227200000 8 0.0029
ch0235200000 8 0.0029
ch0215000000 7 0.0026
ch0221200000 7 0.0026
ch0300010000 7 0.0026
ch2225000000 7 0.0026
ch0203200000 6 0.0022
ch0221000000 6 0.0022
ch0227200002 6 0.0022
ch0300000400 6 0.0022
ch2224000000 6 0.0022
ch3234000000 6 0.0022
ch0207600000 5 0.0018
ch0217000000 5 0.0018
ch0220000000 5 0.0018
Figure 7.3: Sensor chord usage at the end
The sensor usage results are enough to add another dimension to differences between individuals, but they are not of themselves enough to give a predictive model of the players' actions. For this, we must think again about what is necessary for a predictive model, before we are able to integrate these sensor usage results into a coherent model.
In the previous chapter, we were looking at the attempt to derive rules for various groups of control actions, and recognising that better rules were derivable from some representations of situations and actions than for others. But we did not address the wider issue of making a predictive model of an operator's behaviour of broad enough scope to simulate the performance of the whole task. Considering this issue in greater depth has important repercussions for this analysis.
From the above analysis of sensor usage, it was clear that players were able to perform the task adequately, and with improving scores, using only a small selection of sensors at any one time. A predictive model of an operator using only certain information should ideally use the same information. What information should a predictive model be using, and what rules it should have ‘loaded’, at any particular time?
Let us consider the full spectrum of possible answers to these questions. At one extreme, it would be possible to base a model on all rules being available at once. In order to execute this model, all the relevant information for all of the rules would also have to be available. As well as not matching the results of this experiment, this model's reliance on all the information being monitored would perhaps plausibly model that aspect of human information processing if actions were few and far between, but not so if some of the actions demanded focused attention over time, as is the case in the experimental simulation here.
At the other extreme, it would be possible to base a model on the principle of only one rule being present at once. The information necessary for the execution of that rule would be well-defined and limited, but the difficulty in the model would come from the extensive higher-level rules necessary to decide which rule was the one that was relevant to any particular situation.
Seeing this spectrum of possibilities, the approach taken in this analysis was to explore a range of the middle ground first, since that appeared by far the most plausible. The middle ground assumption is that there are groups of rules that are applicable at the same stage of the task, and those rules share an information environment, in that, although they will not all require all the same information, there will be a considerable overlap. The amount of this information should be such that it is plausible to imagine a human monitoring it, given the workload and constraints of that stage of the task. There should also be some chance of reasonable higher-level rules governing either the transition to a new information environment, or rules which allow the deduction of which one should apply at any time. This ‘package’ of rules and information requirements will here be called a context.
As well as relating to the natural use of the word, the name also serves to distinguish the idea from potentially related previous concepts such as schemas [10], frames [82], scripts [119], and their offspring. The motivation behind these concepts is more to do with long-term memory, general knowledge, and understanding story fragments, which differs from that of the present study. However, the term is used in a similar sense by Fagan et al. [35], when discussing the VM system, although this is not the same sense as in the rest of the MYCIN project.
A context is a particular stage of the task, along with the rules and the information that are actually being used during this stage, for which the chords are evidence. This is in harmony with natural usage such as “in different contexts, the same values imply different actions”. The word “representation”, though it has been used in a variety of looser ways, will now refer to a whole pattern of context-based information use that can be thought of as latently present while a person is performing a task; but the meaning should not be taken to include the lower-level action rules themselves. The higher-level rules for switching between contexts could be seen either as a property of individual contexts, or as a property of the representation as a whole.
Having introduced the idea of context, it should be noted that in principle it could stretch all the way in between the two extremes mentioned above. One could have just a few contexts just below the level of the task as a whole: each context would include a relatively large number of rules, and need a relatively large amount of information, but the transition rules would be less likely to be intricate. On the other hand, there could be many contexts comprising only a few rules, and each context would have a relatively small requirement for information. The higher-level rules for determining context would be correspondingly more complex. Furthermore, in principle there is no reason why a kind of context structure should not be built up in more than one layer: there could be grouping of action rules at the bottom level, and grouping of higher-level rules at levels up to the level of the whole task. This last possibility will not be explored here.
Since this idea of context is about a package of rules, information and higher-level rules, ideally we want to do context analysis in terms of rules as well as information use. However, this has not proved possible yet. An approach to this will be discussed below (§8.3.1), but for the time being we shall use information in our analysis.
The analysis in terms of contexts ideally needs data about information usage, but what we have at this point is data on sensor usage. The two are not necessarily the same. This could be for a number of reasons.
Though the first of these reasons may not be a great problem, the second and third mean that it is unsatisfactory to use simply the chords themselves as the basis for the analysis. Furthermore, we can see from Figure 7.3 that there are many different chords used, and that this would appear rather too many to correspond with a human division into stages of the task.
The analysis needed to compensate as much as possible for these ways in which information usage was likely to differ from sensor usage. As well as this, in keeping with the original aims of the study, it was desirable for the analysis to be kept as much as possible objective and automatic. A method of grouping the chords together, and a method of allowing for implied information, are described below.

Figure 7.4: Simplified data flow during analysis of second experiment
An outline of the flow of data in this analysis is given in Figure 7.4, which should be compared with Figure 6.4 above. The first stage of the analysis, shown in outline on the left side of the figure, is to find some context structure and content, and the second stage, down the main axis of the figure, is to use this structure in the induction of rules for the actions.
There are at least three potential ways of finding context structure. Firstly, we could ask subjects what their perceived context structure is, i.e., how they split up the task in subtasks or substages, what information they use to make decisions in each context, and what rules they use. (See below, §7.2.9.4.) This may or may not correspond with what they actually do. Secondly, we can examine the information that they use, and look for patterns in that usage. This is the main approach taken here. Thirdly, we could derive a context structure from the pattern of applicability of rules. This will be explained and discussed as part of further work, below (§8.3.1).
To obtain a more satisfactory (and possibly more realistic) context structure than that given by the chords alone, the raw chords needed to be grouped in some way. What was needed was more than a simple clustering process, because when the chords are clustered together, we do not wish to take the central or most frequent one as wholly defining the information usage, since other chords may have had extra sensors turned on. From the point of view of rule induction, the important point was not necessarily to find the exact information used in a context, but to find a superset of this. Having a few variables present that were not actually used should not hinder the rule induction to any great extent.
In the following procedure, which the author devised to meet this need, the frequency associated with a chord was the number of effector key-presses in the sample performed while that chord was in use. Starting from the least frequently used chord, each chord in turn was matched with all the other more frequently used chords, to find whether there was another chord within a specified ‘distance’ of the first, and with at least as great a frequency; and if there was, to find the one of those with the greatest frequency. The less frequently used chord would then be absorbed into the more frequently used one. If the frequency of the original chord was greater than zero, the keys used in that chord would be added on to the keys used in the chord to which it was absorbed, to make a superset chord stored separately (with harmonics, using the analogy). A distance of one unit meant that the two chords differed by exactly one non-graphic sensor being on in one chord and off in the other, while if one had a graphic display on that the other had off, this was (arbitrarily) assigned a distance of three units.
ch0301000140 998 0.3202 och0301000140 ch0200000000 569 0.1825 och0207200200 ch0200200200 537 0.1723 och0207200200 ch0300000000 324 0.1039 och0300000000 ch1301000140 255 0.0818 och1301000140 ch0400000000 217 0.0696 och0400000002 ch1300000000 205 0.0658 och1300000000 ch1200000000 8 0.0026 och1206000000 ch2201200200 3 0.0010 och2207200200 ch1201200200 1 0.0003 och1201200200
Figure 7.5: Result of chord absorption for the later chords of AJ
An example of the result of this process, applied to the later
chords of subject AJ already given in Figure 8.3,
is shown in Figure 7.5.
With the threshold of absorption of a chord set at two units,
the number of distinct units reduced from
36 original chords to 10 groups of chords.
In the figure, each line has four components.
The first three are as before: the ‘base’ chord code
of highest frequency in this group
(starting with ‘ch’); the frequency
(of effector actions with this group of chords);
and this frequency expressed as a proportion of the whole.
The fourth and last entry on each line
(starting with ‘och’ for ‘overchord’) represents the
chord made up by including all the sensors that
were on in any of the chords in the group.
For instance, in the original list, the chord ch0400000000
(cable sub-display with all sensors off)
had a frequency of 149.
In the list of chord groups, this has absorbed the chord
ch0400000002
(cable sub-display with one sensor on)
which had a frequency of 68,
so that the resulting group of chords has a base chord of
ch0400000000, an overchord of och0400000002
and a frequency of 217.
The other groups are made up in the same way.
Having thus made an attempt to integrate related chords together into groups, the next step was to make allowance for information that was implied. Each sensor was assessed for its likely implications, and a routine was written to add in these implied quantities to the contexts. The implications were based on just a few basic principles.
It is difficult to be comprehensive about these implications, so it would be surprising if there were not some omissions, and indeed spurious inclusions. This is a list of the implications that were included in the analysis. The items followed by a star (*) did not have a sensor of their own.
These implications were added to the overchords,
which then resulted in chord groups as in Figure 7.6.
Comparing this with the previous figure, 7.5,
we see how the overchords have been filled out.
For instance, for the first chord, ch0301000140,
before implications, the overchord has only the same
three sensors as the base chord:
after implications, the overchord has seven sensors
(och0303102142).
In addition to this, the implied quantities that had no
actual sensor were recorded in another part
of the data structure, along with the implications from
the general position indicator that referred to
information whose digital sensor was in another sub-display.
When these chord groups are used, the base chords on the
left are used to match a chord for closeness, and the
overchords and extra quantities without sensors
are used to give what is hoped to be a superset
of the information used in any particular context.
ch0301000140 998 0.3202 och0303102142 ch0200000000 569 0.1825 och0207211301 ch0200200200 537 0.1723 och0207211301 ch0300000000 324 0.1039 och0300102002 ch1301000140 255 0.0818 och0303112142 ch0400000000 217 0.0696 och0400000116 ch1300000000 205 0.0658 och0303112142 ch1200000000 8 0.0026 och0206611101 ch2201200200 3 0.0010 och0237211301 ch1201200200 1 0.0003 och0205611301
Figure 7.6: Result of implications after chord absorption
The second stage of the analysis follows the data
down the central path in the diagram (Figure 7.4).
Starting with the trace data, the first step is to expand
it in the same way as in the previous experiment.
There, actrep then dealt with the representation
of actions, both null and compound.
In this experiment, having introduced higher-level
ROV turn controls, the focus was
away from the representation of actions;
but null actions still needed attending to
even if compound actions were going to be ignored.
A modified version of actrep removed key-presses
that were ineffectual, and put in a null action wherever
there were at least 10 consecutive time steps without
any key-presses (that is, 5 seconds).
This produced a reasonable number of null actions,
such that the number of null actions was at least
of the same order as the numbers of any other
individual class, but not so many as to far
outnumber all the other classes put together.
The functions of the previous programs sitrep and
indprep (see Figure 6.4)
were combined
into a new program prepcont (for prepare
data according to context),
part of which incorporated a definition of a representation
in terms of contexts, either output from tracechord
or hand-written.
The program prepcont then amounted
to some 600 lines of source code.
Some decision had to made about which actions to include
and which to leave out, as was done previously by
sitrep with the representation files.
Including all of them would merely clutter up the programs,
since there are several actions that were either never or
very rarely taken.
The subject AJ never used the ship's propellers individually,
and therefore the relevant effectors were left out in his case.
But they were left in for subject MT, who did use them.
The camera angle controls were left out on the grounds
that the information on which these actions would be based
would be graphical in form, and difficult to formalise.
The action of detonating the mines was left out because
the button for it is in the top section of the screen,
always available, and hence it would not obviously
belong to any one of the ordinary contexts.
There were 44 remaining keys that were included in
the analysis for AJ, 53 for MT, which were responsible
for the overwhelming majority of the total key-presses.
In a significant change from the earlier method,
the program prepcont output a number of files ready for
the rule-induction programs: this is the intended meaning
of the fanning out of arrows in Figure 7.4.
Each of the defined contexts had separate files,
and to facilitate the testing of rules against test data from
the same time interval, the data for each
interval and context were split into two parts,
by putting alternate examples in two files.
Thus, for a representation of 10 contexts,
20 files would be generated from however much
data was fed in to prepcont at one time.
The form of these files was as before
(see Figure 6.8).
This separation of alternate examples was reasonable in this case because any action is associated with the situation prevailing at only one time interval, and the rule-induction process does not make any distinction on grounds of the order of the examples—any significance that there might have been is lost in any case. In contrast, when inducing higher-level rules for contexts themselves (see below, §7.2.7), one cannot use the same method of splitting data, because one context covers a sequence of examples, and if one split up the data by assigning alternate ones to alternate data sets, one would effectively have training and test sets that were drawn from the same instances. So in that case, the data needed to be divided sequentially.
In order to be more comprehensive than in the previous experiment, it was decided to generate rules for every set of data, and to test those rules against every other set of data within the same context. It proved possible to write a C-shell script to govern this process, using the same implementation of CN2 as previously for the induction. The unordered mode of CN2 was used for this analysis, with the modification that only rules that had the decision class as the class of maximum frequency were to be recorded. The parameters of CN2's operation were given values that had given reasonable results in the first experiment. ‘Star’ was set at 15 (a value also used in tests by the algorithm authors [23]), and the significance threshold at 15.0.
The subject AJ interacted with the simulation for a nominal 30 hours 31 minutes, including 62 starts, between 18th June and 25th July. The first non-negative score was 9500 after 14h 38m. Progressive maxima were 11362 after 17h 23m, 12089 after 19h 53m, 14332 after 20h 35m, 14477 after 24h 0m, 16990 after 25h 17m, and 17441 after 30h 31m. Interspersed with these high scores were several where, due to infringements or damage penalties, the score was large and negative. The values of these low scores reveal very little other than the fact that a mine exploded, and so a complete table or graph is not given here. As a comparison, indicating the region where scores would stop improving, the author on a good day can score around 20000 on this task, but has never scored as much as 21000.
A potentially serious error was discovered after this subject had completed 8h 39m of practice. When the ship was travelling backwards, there were certain circumstances where it accelerated backwards without power, and well beyond maximum speed. This was rectified by attending to the simulation of the rudder, but this meant that the data from before this time was not easily analysable with the updated versions of the programs. So the analysis we have here does not include the first stages of learning. The remainder of the data was divided up into six intervals. These intervals were intended to be of approximately similar sizes, but preference was given where possible to put the boundaries coincident with the end of a day. The seven boundaries corresponded with practice times of 8h 39m, 12h 23m, 16h 37m, 19h 53m, 23h 10m, 26h 41m, and 30h 31m. These will here be referred to as intervals C to H respectively, as a reminder that the first part of the data is absent. The durations of the intervals were 3h 44m, 4h 14m, 3h 16m, 3h 17m, 3h 31m, and 3h 50m.
In order to observe the value of using a context-style
representation for the analysis, it was desirable
to have at least two contrasting analyses.
The first analysis follows the minimum
context structure compatible with the interface,
taking only the contexts defined by the
three separate sub-displays of ROV, ship, and cable.
This representation was derived by using the
tracechord program with trace data from the early
interval C, with a very large distance parameter
governing chord absorption (20), ensuring that only
one chord group for each sub-display would remain.

General ROV context (ch2301000140) |
||||||
|---|---|---|---|---|---|---|
| Training set | Test set | |||||
| C1 933 exs |
D1 864 exs |
E1 611 exs |
F1 535 exs |
G1 643 exs |
H1 675 exs |
|
| C0 933 exs |
37.4% +17.4% |
38.3% +12.6% |
33.4% +5.4% |
27.3% +8.6% |
25.7% +8.6% |
23.4% +6.4% |
| D0 864 exs |
31.4% +11.4% |
43.9% +18.2% |
35.5% +7.5% |
28.0% +9.3% |
25.7% +8.6% |
29.2% +12.2% |
| E0 611 exs |
28.7% +8.7% |
34.5% +8.8% |
38.3% +10.3% |
29.3% +10.6% |
26.4% +9.3% |
26.8% +9.8% |
| F0 536 exs |
26.5% +6.5% |
33.3% +7.6% |
31.8% +3.8% |
31.8% +13.1% |
25.0% +7.9% |
26.1% +9.1% |
| G0 644 exs |
30.4% +10.4% |
36.3% +10.6% |
33.1% +5.1% |
30.5% +11.8% |
36.4% +19.3% |
31.6% +14.6% |
| H0 676 exs |
25.2% +5.2% |
27.9% +2.2% |
26.2% -1.8% |
28.6% +9.9% |
27.7% +10.7% |
35.9% +18.9% |
Table 7.1: General ROV context for AJ (of 3 basic)
The first table, 7.1, shows the results of inducing rules for ROV actions, in the general ROV context, with CN2 and testing them on fresh data. The number of examples in each set of data is given below the label for that data set: because the data were dealt out evenly between the two sets for each context, the numbers in set 0 and set 1 differ by at most 1. In the body of the table, the upper figure (e.g., 37.4% in the top left element) gives the overall performance of the rules (generated from the training set) at classifying examples from the test set. The rules generated were used as they were, without any attempt to ‘clean them up’ (despite the fact that it was easy to see opportunities to clean up the rules), so as to reduce the possibility of unaccountable knowledge affecting the analysis. From the data that generate any set of rules, a default rule can also be generated, which is that the class for all examples is the class seen most frequently in the training data. The difference between the performance of the default rule and the induced rules is given as the lower number in each element of the body of the table, where a positive value indicates rules performing better than the default rule, and a negative value that the default rule performs better. As an example, for the top left element, 37.4% is an improvement over the default rule of 17.4%: and thus the performance of the default rule was 20.0%.
The main trend to be observed in this table is that the improvement of performance of the rules (over the default rule) generally is near a maximum when the test set is from the same time interval as the training set, and falls off to either side. This suggests that the rules that are induced are ones that change over time, something that could be explained by the subject learning, and his score improving, during the experimental period. However, the overall performance of the rules is far from good. This implies, in terms of the discussion of action types above (§6.4.2), that there were many actions either which fell into a category other than that of established rule-following actions, or for which effective rules could not be induced given only the attributes included, and the characteristics of the induction program. Some ways of attempting to get better performing rules will be addressed in the next section (§7.3).
Another noticeable feature of this set of data is that the figures for test set E1 appear to be slightly depressed from what would be expected on the basis of the above trend. In fact, between sets D and E there was a two-week break, during which the subject suffered accidental injury. The combination of injury and falling out of practice would seem very plausible explanations in this particular context, where the actions are faster-moving and more time-critical than in the other contexts.

Table 7.2: General ship context for AJ (of 3 basic)
The next table, 7.2, shows similar overall trends. The overall performance percentages are higher than for the ROV context, but this is accounted for by the higher performance of the default rule in each case (this is because there is a greater proportion of null actions in the ship context). The increases of performance over default fall within the same range as for the ROV context. There is somewhat less of a trend of higher performance for training and test data close in time, but instead, there appears to be an increase in the performance of all the rules as the test set is later in time. This could be explained as a general increase in the proportion of rule-governed actions.

Table 7.3: General cable context for AJ (of 3 basic)
The final table of the three in the first group, 7.3, has similar overall performance figures to the ship context, but this time the improvements over the default rule are far more marked. It seems thus likely that the actions in this context are more rule-governed in nature. This is to be expected, given the relative simplicity of the decisions that have to be made in the cable context.
The second analysis given here used contexts derived directly from the data at a finer granularity than the previous ones. The data used in the context derivation was the last set of data from subject AJ, i.e., that called H here. As described above, a chord distance of 2 units led to 10 contexts. Some of the contexts, however, had very small numbers of examples in them, and perhaps could be regarded as fictions created by the analysis process.

Table 7.4: ROV approach context for AJ (of 10)
The three ROV contexts that we shall consider here were termed ROV approach, ROV visual and ROV miscellaneous. This ROV approach context generally applied from after the ROV has been put out, up to where it is close enough to the target for the camera to reveal the nature of the target. It was based around three sensors: the relative heading of the target from the ROV; the range of the target from the ROV; and the height of the ROV above the sea-bed. In Table 7.4 we see much the same trends as for the general ROV context above (Table 7.1). Here the trend indicating shifting rules in somewhat more pronounced than in the general ROV context. In Table 7.5, in contrast, the trend towards shifting rules is distinctly less pronounced. This context, here described as ‘ROV visual’, included the ROV graphic sensor on, so that the subject was relying less on the digital sensors. This context applied immediately after the ROV approach context, and covered the stage where the ROV was manoeuvring very close to a mine. However, looking at the number of examples over time suggests that this context is declining in use, with more actions being taken under the ROV approach context as time goes on. If indeed this context is ‘on the way out’, it is not surprising that there is not much change or development of the rules over the period covered. Conversely, if the ROV approach context is taking on a larger share of the action, it may be that there is further sub-structure within it.

Table 7.5: ROV visual context for AJ (of 10)
The other ROV context is given in Table 7.6. This context is based around no sensors, and tended to occur both immediately as the ROV was put out, and immediately before being pulled in again. It could contain, for example, routine preparatory actions that were not dependent on the situation at all.

Table 7.6: Miscellaneous ROV context for AJ (of 10)
There were also three ship contexts of interest (two others had very few examples). In the ship search context, there were generally no sensors turned on, and from observing replays, it was apparent that brief glances at information were taken, often being turned off before any action was taken. This context was the one relevant to going between targets. Looking at Table 7.7, we see that virtually all the rules induced performed worse at classifying test examples than the default rule. This means that the rules induced could not be accurately showing consistent regularities in the data. The obvious explanation is that there are no good rules, in terms of the attributes associated with this context.

Table 7.7: Ship search context for AJ (of 10)
This is consistent with the view that the searching pattern is the aspect of the task that is most at the knowledge-based level, involving reasoning and planning, rather than simple condition-matching. Subjects were able to discuss at length reasons for or against taking a particular path, both in general, and in particular, when they could see several targets at once and had to decide where to stop the ship most advantageously. A complementary explanation would be that suitable attributes were not provided, in terms of which decisions could be taken. Providing those attributes would involve considerable machine processing, in lieu of the considerable knowledge-based processing that is presumably performed by people.

Table 7.8: Ship positioning context for AJ (of 10)
The ship search context contrasts greatly with the ship positioning context, for which results are given in Table 7.8. This context covered the stage from where a position to stop had been selected, to the time when the ship was stopped and attention moved to the ROV. The sensors centrally involved were the propeller revs and the ship surge speed, with the control demands, headings and target range also amongst the overtones. In this context, the rules perform very well by comparison both with the ship search context and the general ship context, though there are no very clear trends within this good performance.
What is very clear, however, is that this division of context between ship search and ship positioning divides two collections of data that have very different characteristics, and that thus this division is highly relevant to the analysis of this data. This could not have been due to the choice of attributes, since it happened that the same set of attributes had been selected for both contexts.

Table 7.9: Ship with General Position Indicator context for AJ (of 10)
The other ship context included here is the one including the general position indicator (GPI). The GPI was priced heavily to deter its use, and it was never envisaged as being easy to formalise its information content. In Table 7.9, we see that even for period C, the rules induced do not perform very well. The context is then progressively abandoned as time goes on, and the decline of this context roughly matches the growth of the ship search context.

Table 7.10: General cable context for AJ (of 10)
The general cable context derived from period H of AJ's runs (Table 7.10) differed from the previous one (Table 7.3) only in that there were more attributes included in the earlier version's analysis. These extra attributes cannot have been centrally important however, because comparing the tables shows a better performance for the later version with fewer attributes, for the majority of the table elements, including all of the leading diagonal. One plausible hypothesis here is that some of the extra attributes allowed increased precision in the rules, whereas others allowed spurious precision leading to unfounded rules.
The subject MT interacted with the simulation for a nominal 20 hours 53 minutes, including 31 starts, between 17th July and 10th August. The first non-negative score was 7922 after 11h 33m. Progressive maxima were 12337 after 15h 56m, 13971 after 18h 8m, 15147 after 20h 53m. Compared with AJ, MT achieved similar levels of score in a shorter practice time, but did not achieve as high a final score due to spending less time overall in practice.
The data from MT were divided into five intervals, with the boundaries corresponding with practice times of 0h 0m, 4h 8m, 7h 23m, 10h 48m, 16h 22m, and 20h 53m. Thus, the lengths of the five intervals were 4h 8m, 3h 15m, 3h 25m, 5h 34m, and 4h 31m. These are referred to here as intervals A to E respectively.
Initially, the same process was followed for MT as for AJ. Interval E served as the basis for defining 13 contexts, using again a chord ‘distance’ of 2 for allowing the absorption of a chord in a larger group. For each context, rules for each training set were tested against each test set, as before.

Table 7.11: ROV visual context for MT

Table 7.12: ROV direction context for MT

Table 7.13: ROV non-graphic context for MT
The tables of results for the ROV contexts are Table 7.11, Table 7.12, and Table 7.13. For the ROV visual context, we see for interval A a low value for the improvement of performance over the default rule. This implies that at the outset, rules in terms of the attributes selected were not yet established. By the time we get to intervals D and E, however, the induced rules are performing well above the default rule, and we have a situation comparable to AJ's Table 7.4 and Table 7.5. The rules are not performing very well in absolute terms, which suggests that some feature of the actions in these contexts is not taken account of in the analysis.
As we would expect, given the pricing policy on the information, the use of the graphic information declines as time goes on. The context here called ‘ROV direction’ is one of the contexts that is standing in for the ROV visual one at later times. The performance of the D and E rules in (Table 7.12) somewhat suggest that the rules in this new context are in the process of development—there are better scores for the training and test sets drawn from the same interval than for training and test sets drawn from different intervals.
When we come to the ROV non-graphic context (Table 7.13), the results look rather erratic. One possibility is that in this context, there are actions that do not depend on the selected attributes, such as preformed sequences of actions. Another possibility is that this context itself is not a natural one, and that there could be a number of disparate contexts within it. We will return to this point shortly.

Table 7.14: Ship search context for MT

Table 7.15: Ship close context for MT

Table 7.16: Ship search with GPI context for MT

Table 7.17: Ship with GPI 2 context for MT
The results in the ship contexts are given in Tables 7.14, 7.15, 7.16, and 7.17. None of these display any convincing sign that there are rules in terms of the attributes selected. There is no context as ruly as AJ's ship positioning context (Table 7.8). What they do show, however, is shifts in patterns of sensor usage, and that this sensor usage differs substantially from that of AJ. In the absence of any signs to differentiate between them, we must say that it is not clear whether these contexts correspond to MT's task structure, or whether they are artefacts of the analysis.

Table 7.18: General cable context for MT

Table 7.19: Cable with GPI context for MT
The cable contexts (Tables 7.18 and 7.19) for MT show much the same picture as for AJ, but in the early intervals (not present in the AJ analysis) MT has the general position indicator on, and the rules induced are not as good during the initial learning, in intervals A and B. The cable operations are extremely simple, and it is not at all surprising that rules can be induced for these.
As well as the 9 contexts described here, there were 5 other contexts in which the number of examples was smaller. These contexts are more tentative than the others and the results based on them of less value.
In order to assess the variability of the figures obtained in the tables, the induction was run again with the 0 and 1 sets of data interchanged: i.e., rules were induced on the 1 data sets and tested on the 0 data sets. Because of the fluctuations between the 0 and 1 sets, in general both the overall accuracy figures and the default accuracy figures differed slightly between the two sets. For comparison, the three tables 7.20, 7.21, and 7.22 give alternative versions of Tables 7.11, 7.13, and 7.18 respectively.

Table 7.20: ROV visual context for MT

Table 7.21: ROV non-graphic context for MT

Table 7.22: General cable context for MT
These tables show a reassuring difference in detail and similarity in structure. Of the three shown here, the context which was least regular and predictable, ROV non-graphic (Tables 7.13 and 7.21), is also the one where the discrepancies between the two versions are greatest, whereas for the other two, where there appears to be more predictability, there is also less discrepancy between the versions. This adds to suspicions that the ROV non-graphic context corresponds less to MT's mental structure than some of the others.
Another aspect of the validity of the contexts that were derived in analysis is whether they themselves can be predicted in terms of the variables in the simulation. This would be crucial to the ability to simulate the performance of a human operator, since to use the rules from a particular context needs first to determine which context to use. At the same time, the question arises whether we can measure in some way the difference between the two subjects' context structures.
To these ends, the final intervals of both subjects were each divided into three sections, and data was prepared with many of the likely variables as attributes, and the contexts that we have used above as class values. The data sets were E1, E2, and E3 from MT's interval E, and H1, H2 and H3 from AJ's interval H. Both context structures were used with data from both subjects: that is, the data was put into both the representation derived from that data, and also what should have been a less well-fitting representation from the other subject. For each of the two representations, rules were induced on each of the 6 sets of data, and these rules were tested on each of the 6 sets.

Table 7.23:Testing representation rules using contexts from AJ

Table 7.24:Testing representation rules using contexts from MT
The results of this analysis are given in Tables 7.23 and 7.24. The first point to be recognised is that the leading diagonal of these tables must be discounted, since the training set and the test set are the same, giving much higher accuracy values.
The next point to consider is the comparison of the figures from the top left and bottom right quadrants (where the training set and test set come from the same subject) and figures from the top right and bottom left quadrants (where the training set and test set cross between the two subjects). On the whole, the figures for the crossed training and test sets are lower than for the homogeneous case. This suggests that the rules for the contexts differ between the two subjects, even in this case where the same context structure is being used to process the original data.
The third point worthy of consideration comes from a comparison between the two tables. Though it is difficult to pick out any very marked differences, It would appear that where the training set is prepared with its proper representation (H with AJ, E with MT), the distinction between the performance of own subject test sets and other subject test sets is more marked. Thus, in Table 7.23, having discounted the leading diagonal element, there is no clear difference between the performance of test sets on the training set E1, which is from MT's data. For the H training sets, however, there is in each case a marked difference between the E and H test set performance. This could be due to an appropriate context structure leading to clearer context selection rules, which in turn lead to clearer distinctions between individuals.
Looking at the table again, one sees that the performance with E2 as test set is consistently lower than for the other E test sets (suggesting an unrecognised cause operating), and this tendency contributes to the effect just described as the third point. But even discounting the E2 test set results, there is still a slight trend in the way described. If one discounts E2 as a reliable test set, then Table 7.24 shows the same pattern as the other table. But the figures supporting this third point are far from conclusive, so more evidence would be needed to establish this as an effect.
As we have already seen that different contexts can differ markedly from each other, it also makes sense to look at the performance of the rules induced for predicting each context separately. This was done for both subjects, and the results are presented in Tables 7.25 and 7.26.

Table 7.25:Accuracy of rules for contexts for AJ, for the last interval

Table 7.26:Accuracy of rules for contexts for MT, for the last interval
These two tables show to what extent rules can be constructed to predict the context itself, from the attributes included in the analysis. It is important to note from these tables that the overall accuracy figures in previous tables do not consistently reflect the predictability of individual context use. For some contexts, their selection would appear to be highly rule-based, e.g., both subjects' ship search contexts. It is interesting that the ship search contexts are so highly predictable, despite the fact (above) that within the context no good predictive rules could be discovered. Other contexts are not so rule-based. This could be due to a number of reasons.
The ROV non-graphic context posed the question of whether this was a fictitious context, or alternatively a real context in which there were no straightforward rules inducible on the basis of the attributes chosen. One test for this was to attempt to make the granularity of the contexts finer. This was done by setting the absorption distance to 1 rather than 2 in the process of construction of the contexts. As a result, more putative contexts were produced, and these then served as the basis for another similar process of rule induction and testing. This revealed little difference from the previous analysis. The same contexts were still dominant, with the same general patterns of results: the other contexts were generally low in examples, and offered no further coherent insight into the context structure. This result also serves to cast doubt on the value of pursuing still finer context divisions.
Perhaps a more challenging question was raised by the ROV visual context for MT, and the ROV visual and ROV approach contexts of AJ. We have here what look like well-defined contexts, yet the overall performance of induced rules is not as high as one might hope for, looking at the performance of rules in other contexts. Why not? One possible reason worth investigating was that during ROV manoeuvring, there are three concurrent tasks: to deal with speed, direction, and height. It may be that these tasks interfere with each other, because the human controller cannot attend to all at once, and that therefore at times more than one action may become appropriate according to simple rules. But the human will only be able to deal with one at a time, and any set of combined rules may predict either, but cannot predict both simultaneously.
A method of testing this is to separate out the control actions for the three different sub-tasks, and see how rules for the actions separately (together with null actions) compared on performance with the rules for all the actions together, which we have already discussed. Because null actions are only included when there is a reasonable thinking break, it is plausible to suppose that this process would avoid the potential clashes, although of course it cannot do anything about the extra fuzziness introduced by the actions having had to be delayed. This analysis of the sub-tasks turns out not to be strongly suggestive of any particular explanation of why the overall accuracy figures for the ROV contexts are not very high. It is given in Appendix C.
In an area so barely explored, it cannot be doubted that there must be other methods of analysis which have not been pursued here: further discussion is in the next section (7.3).
At this point we shall turn to verbal reports both as a means of explaining some of the findings here, and of highlighting some of the problems, to be discussed in the next section (§7.3). For both AJ and MT, on the same day as their last trial, the author and the player discussed a replay of their final, highest-scoring run, and this discussion was recorded on audio tape. This replay was a version using the expanded file, with the facility to stop, go slowly or fast, backwards, or skip forwards or backwards.
This study is not primarily a study of verbal data, and therefore far less than a full analysis of the verbal reports is offered here. We will rather pick out certain points that are relevant to the general issues under consideration. The extracts below are quoted as near as possible verbatim, because in most cases the subjects did not (and perhaps could not) give concise accurate accounts of the rules they were using. In the extracts, “I” stands for the author/experimenter.
One of the potential failings of the method of analysis described is that it will not distinguish contexts that have the same sensor usage. An example of such an undistinguished context is the start, described by both subjects.
MT: The first objective is to try to hit the red square at roughly, to go through the corner axis of the square I'm aiming for that point. I start off by just, er, aiming to go full ahead then I move onto my display screen and switch off the, er; fix the ship in the centre, and reduce the scale by double the amount (whatever it is). This sets up the screen for the right sort of like distance I'm going to be using now when I want to be, er, when I want to use the screen. I would then — that's a reasonable amount of time to actually come back and start turning the ship then: the ship's going a sufficiently amount, er, speed forward, then start turning it to the port, so it's going to actually hit this, aiming at round about 300 degrees to be able to hit it in the right direction.
AJ: Go into full ahead, I want to get as near to the area as possible. I know roughly the direction of the area.
I: So you do that of course without looking at anything.
AJ: Yes; which is a bit unfair; you should change the area each time. Right, now, checking the heading, see how far I've gone, 340, that's fine, I don't have to adjust that.
I: But what wouldn't be fine? But you've gone centre rudder there I notice.
AJ: Centre rudder, yes. 340, that's OK, that's a fine bearing. If it was going towards, er, if it was still about 350 say, I'd want to have a wee bit more port. Yeah, I've just remembered, I want to get the position indicator ready, in case I have to look …
This could well be regarded as a separate context, since special rules apply that do not apply anywhere else. But the sensor usage is fundamentally the same as for the general ship searching: that is, no sensors on all the time. A more subtle approach would be needed to distinguish this context from other similar ones on the basis of the players actions and information usage.
We noted above the lack of effective rules coming from the process of rule induction, for ship searching contexts. This is not surprising, given the kind of high-level concepts employed by the subjects describing their searching strategy.
AJ: What's my strategy? I usually just keep going along, um, the bottom half.
I: Yes. So where roughly abouts?
AJ: Say, about the middle of the bottom half.
I: About two and a half squares up from the bottom? 250 metres up from the bottom?
AJ: Three, three I'd say.
I: Yes, 300 metres up from the bottom. So you go along the bottom and back round the top, do you?
AJ: Yes. But usually it never works that way.
MT: The next bit I'm looking for is the easterly direction, and when it's about 600, what I intend to do then is to turn it North, and hit 0 degrees and just go North, bring it round south, north and south, and then back in. It's a pattern to follow through the, er, the maze, the red maze you give us. It adds some rules and directions to where I'm going within there, rather than search aimlessly.
These strategies would be very difficult to discover from the data, and without them we cannot very well make sense of the decisions taken in this context.
The discussions brought out the fact that some sensors were used together, to form a new compound quantity, which seemed more likely to figure in the rules. Here is an example of a quantity that was not included in the analysis, and could therefore be partly responsible for the fact that the rules generated were less than optimal.
MT: … look at the range. I should have also looked at the height, or the depth.
I: Yes, the height.
MT: And decided on when I want to actually thrust down to, to get there.
I: Do you feel yourself making some sort of intuitive judgement of angle, on the range and height together?
MT: Yes.
I: Right, and when do you — have you formalised that in your head, or is that just a sort of vague idea?
MT: I don't want to be diving too deeply, er, by being too close. The problem is, you end up losing the vehicle underneath you …
There were other instances in the discussions which could have been taken to imply that certain quantities were playing a part in operational rules, which were derived from the quantities displayed, rather than being displayed directly.
Both subjects were asked explicitly how they would describe the structure of the task in terms of phases. Subject MT came up with approximately the following outline.
There were also a few non-standard situations that were recognised as having separate rules.
Subject AJ's reported outline pattern can be summarised as follows.
Getting stuck in the mud (on the sea-bed) was another obvious separate context, as indeed were other recoveries from mistakes.
The phases mentioned by the two subjects have some similarities with the contexts produced in the analysis described earlier. The number of them is comparable, and some of them can be identified with one of the analysed contexts. However, they are not clearly identical, either with each other, or with the analysed contexts, and this adds doubt to the idea that the context analysis procedure is perfect.
Both subjects reported recent changes in the way they performed the task. An example of what might be called a strategic change was given by MT.
MT: The last 3 turns, probably from 8th August, or the go before then, there's been, er, a conscious switch in the rules that's been used, to generate the strategy used for finding the ships, pointing the ships. The direction to — the rules to go up and down — there's various mines been left around, right on the edge, which I've not been getting, because I've been wandering from one mine to the other, which meant I'd come back to the base,
I: And you wouldn't have finished, yes.
At a more tactical level, AJ reported having just started to use the ‘turn’ effectors, where he had previously exclusively used the ‘kick’ effectors to change direction. He also said that he had recently begun “going by feel”, rather than, presumably, going by conscious rules.
Here is an important point for the experimental methodology. Even after 20 or 30 hours of practice on this task, the players performance was still in a state of flux, and hence, since stable rules would be easier to discover, a longer period of practice would be better. It is also consistent with the observation, for some of the tables above, that the rules induced for one time interval performed much less well when tested against data from a different interval. Ideally, an experiment such as this should be long enough for the rules to stabilise, which would mean both that subjects did not report recent changes, and that rules induced on one interval performed equally well on neighbouring intervals.
An interesting and important additional point is that neither subject reported recently changing their view of the structure of the task, in terms of stages or contexts.
Another factor seen as leading to change in task performance was the experience of recent problems. MT talked a lot about confidence, how it was lost, and how this affected the tactics. AJ reported not taking a certain action because of recent experience of failure. Changes in tactics for these reasons would also be reflected in more poorly performing rules being induced from intervals including such changes.
But, among the many other interesting facets of the discussions, which are less directly relevant here, there was a clearly apparent difference between many aspects of the way the two subjects performed the task.
The discussion at the end of the previous chapter highlighted the need for an approach to discovering about human representations of situations. To this end, we have seen the introduction of a concept of context, together with a rudimentary means of deriving contexts within the framework of the information-costing experimental arrangement that was devised expressly for that purpose; and then an analysis in terms of those contexts.
Despite the shortcomings of these methods, which will be discussed later in this section, the context structures derived
Some of the contexts appear to have a comparatively highly rule-based character, and it is easy to relate this to Rasmussen's categories of rule-based and skill-based behaviour. It would be rule-based, in Rasmussen's terms, if the rules were consciously known by the operator, and skill-based if they were not. On the other hand, other contexts do not reveal a highly rule-governed nature through this method of analysis. There are a number of possible explanations for this, but one obvious one is that they correspond to Rasmussen's category of knowledge-based behaviour. Here it is interesting and suggestive to note that in the ship searching contexts, for which good rules could not be derived, the information flow is relatively small, with the sensors kept mostly off, and the number of actions is comparatively low. These are just the conditions one would expect for knowledge-based processing.
It must be emphasised here that the results of these analyses are tentative. The analysis methods have apparently not been tried on this kind of data, and there are no established equivalents of the general statistical methodologies, current in psychology, to support this approach. The results have been presented and discussed largely in terms of the difference in performance between induced rules and default rules, expressed as a simple difference in percentage. However, there are undoubtedly other possible ways of arriving at a measure of ‘how much has been learnt’, and the methods used have been used because they were plausible and gave interesting results. We await a more thoroughly worked out methodology. To the extent to which these results can be considered at all valid, they serve also to support and justify the novel techniques that have been necessary to derive them. There is a great deal more that could be done in the line of analysis in terms of contexts, and this can be seen as a highly valuable outcome of the context principle.
A context structure is also a means of structuring a task so that it does not grossly exceed the known capabilities of the human information processing system. Card, Moran & Newell's Model Human Processor, which has been discussed above (§2.3.2.1), has a useful collection of relevant values of those capabilities. No explicit attention has been paid to make a context structure fit in with these boundaries, but it is not difficult to see firstly, that a context structure is a plausible way of breaking down a task so that only a small number of independent quantities need to be monitored at any one time; and secondly, that explicit constraints of this type could be built in to a context analysis process, to ensure that the limitations were kept within, and thus that a context analysis remained consistent with what is known about human information processing.
This would also be addressing similar issues to those addressed by the idea of Programmable User Models (PUMs), also discussed above (§2.3.2.2). A context-based structure could provide a model of the content of task skill, in a form which could be run on an explicitly constrained computational model of a human operator, as envisaged by the PUMs approach.
Here we will consider problems with each stage of the analysis, from the subjects onwards. These problems invite solutions, which are suggested as well.
Both subjects both showed and described recent changes in their methods of performing the task. A longer practice time would be preferable. Based on the experience of these experiments, one could conjecture that perhaps 100 hours of practice would be more appropriate for the level of complexity of the of the task examined here.
The relatively short practice time meant that the data could be expected to have more anomalies in it than would be the case for later practice: but the data was not ‘cleaned up’ in any way before use. This means that they could have included runs, or parts of runs, when the player was doing something other than the usual task. It would be possible, if laborious, to watch all the runs carefully, and to discard those runs which appeared not to be conforming to a minimum standard of attempting to perform the task as given. This would run the risk, of course, of selecting the data to fit the theory, but it might also produce an improvement in the clarity of the analysis. Another related open question is whether to filter out actions which preceded disasters (such as setting off a mine), on the grounds that such actions cannot be consistent with a successful overall strategy.
Having chosen the data, attention turns to the analysis, with the construction of contexts and the choice of attributes within each context. The method of finding contexts was not highly developed or principled, and there is no doubt that this could be improved, both for the information-hiding methods employed in the second experiment, and by exploring other methods, which will be discussed below, §8.3.1.
The question of selecting attributes within a context is highly problematic. Seen in one way, this is an endless problem, to be solved only in the ideal case that a full predictive model of behaviour is constructed in terms of the full set of attributes. However, the impossibility of this need not blind us to possibilities of improving the attribute set for any context. This is also linked to the question of whether we have a realistic context structure, since an inappropriate structure could mean that an inhomogeneous mixture of information might be being used. But assuming that there was a good context structure, there are essentially two approaches to improving the set of attributes associated with it. The first is the way which has been taken here, to monitor usage, and to ask the operator what information is being used. More attention could be given to this. The second way is to ascertain which attributes lead to the best induced rules, and this will be taken up later, in §8.3.1.
Having decided on the contexts and attributes to be used, the next important factor in the induction is to optimise the operation of the rule-induction program for the data presented. In the analysis reported here, plausible values were assigned to the parameters of the program, and not altered, so that the analysis would not be confused. There remains the possibility that other values would have given better or clearer results. A natural extension to the work would be to check this.
Another approach to obtaining good rules is not to rely entirely on the rule-induction process, but to attempt some kind of selection or editing of rules. This could be done by eliminating those rules that performed least well on test data; or that could be discounted on a priori grounds such as symmetry, or the use of attributes that should have nothing to do with the action. It is important to recognise that in this experiment, no attention has been paid to the rules themselves, but only to the performance of the rules together. In other words, the chief interest has been the ruliness of the data, rather than the details of the rules. The number of rules is rather larger than one would desire for a model of dynamic task performance, and the rules individually appear more to specify when a given action does not occur, than when it does occur. Hence it is unclear how successful editing rules would be.
Another unexplored possibility is the integration of the analysis of situation representations followed in this experiment, with the analysis of action representations, which was carried further in the previous experiment. It is an open question whether this would improve the effectiveness of the analysis as a whole.
Other extensions to the work, that do not arise specifically from recognised problems or deficiencies, involve methods to further check the validity or consistency of the results.
Originally envisaged, but not undertaken, was to use the representations derived from particular operators, and implement interfaces where the sub-displays corresponded to the contexts, and the information available in those sub-displays corresponded to the information that was found to be used within that context. It would then be possible to test experimentally how operators performed with interfaces that either corresponded, or not, to their own context structure. This might provide valuable feedback about how closely an individual's representation had been captured.
Related to this, it would be very interesting to train people on the information-costing version of this task, and then put them on a version as in the former experiment, where all the information is simultaneously available. An important question would be, do their rules for performing the task stay as they were, or does the presence of extra information help, or even possibly hinder, them? Having developed a strategy for using information, do they prefer an interface where information can be turned off?
There might be some value in changing the scoring system. For instance, any access to a piece of information could be priced at the appropriate value for a minimum time of a few seconds. Alternatively, a sensor could be set to be disabled a few seconds after a button-press on an enabled sensor. This might make the analysis of information usage easier, by making the system fit more closely with human short-term memory.
At some point it might become worthwhile to assess the difference, if any, between results obtained with CN2 (in its different modes), other rule-induction algorithms, and other techniques such as Bayes classifiers.
Another more ambitious way of testing the whole context and rule system is to use them to construct a executable model player, based on the data from one human player. To do this, one would have to first code context selection rules, then, for each context, code a set of rules for that context. In considering rules for contexts, some of the same considerations arise as in the discussion of types of action, above (§6.4.2). One could consider a context to be a function of the system state, with every state having a unique corresponding context. This may, however, be over-idealised for representing a human context structure. In order to implement a model where the context was a function of several variables of the system, those variables would have to be continuously monitored, to check for change of context. If the number of variables to be monitored was in excess of the plausible human monitoring capacity, it might become more realistic to consider context changes as the fundamental method of keeping track of context, with rules for change from one context to others existing alongside the rules for actions within that context. There could then arise considerations such as whether more than one context could coexist, where there was swapping between contexts based on available attention rather than triggering rules. The issues involved in constructing a full executable model of an individual's task performance are extensive, and some of them are taken further in the next chapter.
1. ↑ The analogy between music and other intellectual systems is taken much further, imaginatively by Hesse [52] and speculatively by Hofstadter [54].
Looking over all the foregoing work, we may collect together a number of points that are relevant to our central theme.
The findings that emerge from the study as a whole are thus:
This issue is independent of the other main points of this study, and will therefore here be discussed separately. We started out, in §1.3.2, defining a complex task as one for which there were a large number of potential practical strategies. With this large number of possible strategies, and without superimposed severe constraints to limit this number, it is not surprising that individuals settle on different strategies, as suggested, passim, in §2, and more explicitly in §3.1.2.2. This study does not belabour the general recognition that strategies, contexts and rules differ: that is informally evident from many of the experimental results. The difficulty is in measuring that difference in a way relevant to the model being developed.
If there were a clear correspondence between the contexts of two subjects, but with different rules within those contexts, we would be able to compare the performance of rules induced from one subject's training data on test data both from that subject and another subject. This would show how fax apart the rules were. But as it is, their contexts differ, and this is not possible. What was done in §7.2.7 was to analyse two subjects' data both in terms of their own context structure and in terms of the other's. This was inevitably a somewhat artificial procedure, but it was the nearest that could be devised to measuring the difference between the two context structures. This measurement was consistent with there being a difference between the rules used for selecting contexts, though it did not provide a method of determining which context structure matched up with an anonymous segment of performance data. Instead, for long sequences of trace data, we could distinguish whose data they were simply by looking at the frequencies of sensor usage. We can see something of the difference in sensor usage in the second experiment in §7.2.1. Turning back to rules, the results in both the sea-searching experiment chapters (§6 and §7) included evidence concurring with the intuitive notion of rules differing with respect both to the player and to time. Informally, even the short snatches of verbal report that have been given here (§7.2.9) reveal differences in rules between the subjects: there were of course many more examples in the verbal reports.
The fact of there being differences between individuals has had implications for the concept of modelling being developed. Differences between individuals mean that there is no universal human strategy to model, and that therefore the important advance is not to try to discover a normative model, but to establish methods of modelling individual human task performance, by setting up a framework and a methodology for that modelling. In the literature, the term 'model' is used sufficiently broadly to permit such a modelling approach to be termed a model.
It is important to emphasise, despite the fact that many rules have been induced in the course of analysis, that no claims are being made about any of the rules that have been induced. There are very few grounds for putting much confidence in any particular induced rule, or attaching great significance to the content of one of them. In this study, throughout §6 and §7, rules are induced only as a guide to how ruly or unruly a certain set of examples are, with respect to a set of potentially determining attributes and a set of actions potentially determined by those attributes in a rule-like way. Comparing the ruliness of one set of data, represented in different ways, gives measures that can help progress towards finding better sets of attributes for that data; and similarly, looking at the ruliness of sets of data divided in different ways helps towards identifying better ways of dividing the data. Together, the ways of dividing the data, and the attributes that are relevant within each division, amount to a representation. The representations that help the analysis to be more tractable, concise and effective are very natural candidates for consideration as representations that humans use to structure a task, even if the action rules themselves are not good models of human rules.
If we are to take the information-processing model of human cognition seriously, it is reasonable to work towards modelling human abilities by investigating structures which help to clarify human task performance data; and inasmuch as the derived structure does actually clarify, this could be taken as indirect evidence for the existence of structures of similar form in the human. Further indirect evidence would be gained if the structures were able to serve as the basis, in the longer term, for the discovery of rules that could more plausibly be attributed to human agents than the rules in this study.
The idea that context (as used here) is a main feature of such structures is supported by:
The information pricing technique described in Chapter 7 offers a start to analysis of task performance data in terms of contexts, in a way that is not just a priori; but to be more valuable, the methodology needs to be extended to deal with data from less artificially restricted domains.
Starting with the last feature to be introduced, the first generalisation would be to remove the necessity of the information-costing interface (§7.1.1). To achieve the same aims, this would mean that the analysis had to discover information usage in a different way. A possible explicit approach to monitoring information usage would be by using eye-tracking, which would naturally go together with a more detailed analysis of short-term information flow in terms of short-term memory. This would require more input from cognitive psychology, and it is not clear to what extent this approach would reveal more about the aspects of cognition addressed in the present study. Discovering information usage otherwise, that is, implicitly rather than explicitly, would be tantamount to an advance in machine learning techniques, and therefore the discussion of that, though important, is left to §8.3.1, below.
Another artificial constraint imposed in the course of constructing the experimental vehicle was the strict quantisation of the times at which interaction was possible. Removing this constraint has two implications, corresponding to the two reasons that strict control of action timing was introduced originally. Firstly, there is the technical problem of storage and regeneration of the runs. Due to the essential indeterminacy of the physical world, we cannot expect to recreate episodes from real life given only the actions taken, however accurately these are recorded. If we wish, nevertheless, to gather data from real tasks, this means that the only option is to record all the possibly relevant data to whatever level of accuracy is appropriate-limited perhaps by the ability of the human to make discriminations. For life-size complex tasks, this would mean in practice a lot of magnetic tape. For simulations, the method of recording data would be entirely dependent on the details of how the simulation was implemented. Suffice it to say here that the amount of data that needed recording would be somewhere between the minimal amount necessary in the experiments in this study, and the maximal amount for a real life task with a physical system.
Secondly, removing strict control on timing would mean taking into account the possibility that precise timing of actions was an important aspect of task performance. This is discussed here immediately below, and in §8.2.1.
In §4, investigation was started on a task which had a virtually analogue control input, and for which precise timing of actions was important. Others of the tasks rejected in §5.1.3 were seen to have a similar character.
The main problem with this kind of task is in relating appropriate situations and actions together in a way that is relevant to human cognition. As shown in §4.3.3, it is difficult to decide how to represent human actions when they are executed through an analogue channel; and if precise timing is involved, as discussed in §4.4.2, it is difficult to know which situations to relate to which actions, in terms of time.
Failing any more principled ways of overcoming these problems, the approach that is implied by this study is to work by trial and error, using rule induction as a means of testing the relative merit of ways of representing actions. Extension to these kinds of task will be briefly discussed further below, §8.2.1.
In the sea-searching experiments, the issue of developing new representational primitives for situations was not explored beyond the introduction of reasonable hand-crafted compound attributes, in the first experiment intuitively, and in the second experiment following the idea of information implications. In the representation of actions, the method in the first experiment was simply a kind of chunking, of no more sophistication than, for example, the reasonably well-known methods referred to by Schiele & Hoppe [120]. The methodology of the present study has minimised the need to find new representational primitives, but the proper representation of actions would be a more important issue in manual tasks with analogue controls, and the representation of situations would be more important in more complex tasks.
The problem of representing situations properly is focused by bringing in some kind of realistic limitations to the amount of information and the number of rules to be dealt with at any one time, in line with the supposed abilities of a human. We may find that to get the greatest possible ruliness from a set of human task performance data, where the situations are represented at a low level, requires the number of attributes, or the number of rules, to exceed such a limit. One possible reason for this would be that the human preprocesses some of the information into higher-level units (aggregation of data), in terms of which the rules may be considerably more compact. For this methodology to be generally effective, ideally it needs the addition of an automated method of finding such higher-level primitives.
Ideas on this have been introduced in the discussion of machine learning, above (§3.2.3), and a general solution would belong to that field where the issue of constructing new predicates has already been addressed (e.g., [86]). However, it is possible that other less general methods could be developed to tackle this problem specifically for the domain of human task performance. The process of looking for higher-level primitives could be triggered by finding a set of attributes that exceeded some reasonable bounds on human processing ability. For instance, a control room operator could be confronted with a large number of warning lights in a single panel. We could imagine the strategy to be markedly different depending on whether only one or two warnings were active, or many simultaneously. A very complex rule could describe the difference in terms of the status of each warning light; but the human would more likely be using a higher-level qualitative attribute of roughly how many warnings were active at the time. In this example, there would be very many individual sensors in the low-level representation, but some kind of constrained search over these sensors might turn up a qualitative measure of the number that were on simultaneously. Deriving such a method would require extensive further investigation.
If no such methods were obtainable, one would again have to rely on trial and error, with different sets of primitives being evaluated with regard to the performance of the rules induced under each representation, as has been done in this study. Clearly, this process could be greatly aided by finding as much as possible about the terminology that people use when describing or discussing the task, and attempting to formalise those terms.
The nature of this study is exploratory, and there is no fully-fledged theory of human representations of complex systems which can be presented in conclusion. Nevertheless, it is important, in the conclusion to this study, to give a wider idea of the concept of context that has grown up alongside it. This is because these conjectures serve both to clarify the idea of context by giving it some background, and to point towards further areas of research.
Contexts can also be thought of as entities that serve the purpose of supporting other ideas. First in §2.4.9, and subsequently in §7, we have suggested that an operator's information processing can range from skill-based to knowledge-based in the course of one task. If we cannot describe a whole task performance as purely skill-based, rule-based, or knowledge-based, then to use these terms we must identify a smaller unit to which they could apply. Contexts as described here fit the bill.
This study has not revealed any empirical evidence about how people articulate contexts: in particular, how they move from one to another, how many there can be active at one time, and whether there is any differentiation amongst contexts-different types, hierarchies etc. Reflection on everyday life, as well as other complex task performance, leads to the conjecture that context shifting may be done primarily by means of cues, which may be internal to the task (e.g., a particular goal state having been reached), or external to it (e.g., the phone rings). There are some context shifts that seem to be very widely applicable: for instance, in an office, when the fire alarm sounds. The rules of behaviour while a fire alarm is ringing are, to say the least, noticeably different from the rules obeyed in other situations. Of course, it is not the sound of the alarm itself that changes a person's rules of behaviour, but an internal change in response to that alarm. Another intuitively obvious phenomenon is that people sometimes get disoriented while they are performing a task, or engaged in an action. This leads to actions to identify what is happening, in other words, what the current context should be. So it seems reasonable that any context at any time will have a 'reorientation' context behind it, so to speak, from which the person may say 'what was I doing, now?' This reorientation context may vary according to circumstances, and it may have a more or less fixed method of determining the (lost) current context.
People also clearly engage in multitasking. This could be done via a mechanism involving attention: when there is a lull of attention-needing activity in the current context, one could move into another context that needed attention. Alternatively, it could be that a number of contexts can be simultaneous in a more immediate way, such that a relevant change of state in any of them brought that one into awareness. Analogies with multitasking computer operating systems may be of some use, including the ideas of dæmons and interrupts.
If one can easily imagine multitasking, then it would be even easier to imagine that the process of transition between two contexts involved a gradual, rather than a sudden, takeover. Being sure that a new context was appropriate and workable could be a precursor to relinquishing the previous context.
We have seen in this study (§7.2.1) that it takes time from starting on a new task to settling on a particular pattern of information usage. At the early stages, there may wen be some context structure, but it was not revealed by the methods used, and in any case, it appeared to be in a state of flux. In any unfamiliar situation, we have already said (§2.4.9) that information processing is more likely to be knowledge-based, and it seems likely that one of the chief processes by which a knowledge-based situation becomes rule-based and thence skill-based is by identifying the context structure within that situation. That is, a structure needs to be set up where it is known what the relevant variables are, what the appropriate actions might be, and when that context is no longer applicable. This would then be a precursor to refining the rules for application within each context.
An individual new context could originate from the human realising that some current context (perhaps an underdeveloped knowledge-based one) was needing better performance than was currently being achieved. Some distinguishing features would then he sought, on the basis of which to refine the context structure. As soon as some new context was defined, a process of adjustment would be started. Along any context boundary, one might find that one context was more appropriate than the other, in which case the boundary would shift so that the more appropriate one was used more.
The previous context structure out of which the new one came could be retained in the background, and might be referred to again in cases of disorientation. In cases of disuse, it could be that either the rules within contexts get forgotten, or the progression rules between contexts could be forgotten. In each case, we might see a reversion to a previous, more general, or simplified context structure for that domain or area.
A completely new area of experience would provide the possibility for borrowing the context structure from another domain, as an analogy. Just what parts of the context structure need to be borrowed from the analogous field, and what parts need to be changed, is unclear.
This study has largely focused on a particular kind of context, where rules can be induced based on a few attributes. These are where the information processing is, in Rasmussen's terms (see §1.3.1), rule-based (if the rules are explicitly known) or skill-based (if the rules are not explicitly known). We have also discussed the possibility of contexts, occurring at times where the less experienced operator is still, in Rasmussen's terms, using knowledge-based processing. Here, much varied information may be used, but we would expect it to be processed sequentially, and relatively slowly.
We can also imagine a third kind of information regime for a context: where there is much information, and that information is processed in parallel, relatively quickly. One paradigm for this would be pattern recognition. Now it may well be that, in practice, patterns are recognised as falling into one of a small range of classes, before being, as it were, passed on to the decision-making process, but it is often characteristic of patterns that we cannot build any simple rules which would enable inference of the class from the pattern elements.
If pattern-based information processing is going on, analysis and simulation in these contexts may require the integration of some kind of pattern-recognising front end to the information gathering process: something that would enable the classification of patterns into classes, modelling a particular human's way of doing this. However, just because a human uses pattern-matching does not necessarily mean that there is no other way of finding equivalent rules from the same information. If the situation arose, where a human was pattern-matching and other information could support concise rules, it would be possible to emulate human performance while losing some realism, by using the other information as the basis for inducing rules.
Extensive discussion of pattern-matching would be out of place here, since it has a large literature to itself, involving connectionist models. The existence of pattern-matching aspects to human information processing by no means invalidates the rule-based approach: but it does put limits on its comprehensiveness.
When discussing cognitive psychology above, the point was made that having a theory does not necessarily mean, either that is it relevant to real problems, or that it can be put to good use. Since this study was motivated by real problems in the world, it is appropriate to consider briefly how the work done could be built on to provide something of external use, which serves some of the purposes introduced in §1.3.4.
These could come from either of two levels of the analysis in this study: firstly (and more simply) from the representation, along with its implications for information use; and secondly (with more difficulty) from the rules, of a particular individual's task performance. The context structure and information usage could be useful to the incremental redesign of interfaces; but application to early design, training, and what is here called the 'Guardian Angel' approach to operator support, need a model of rules as well as context structure. Before considering these in detail, we shall first look at obstacles remaining in the way of applying the methodology to real tasks at all.
The methods developed here aim not to rely on subjective judgement, but as far as possible to be objective and automatic. Hence it is important that the information automatically gathered and processed for the analysis covers as much as possible of the information actually used by the human operator in making decisions or in performing actions. In §8.1.4, we have discussed problems attending representing the information that is available, but this still leaves the problem of gathering relevant information in the first place. This research does not circumvent this problem, but rather highlights it by providing methods of using the information that has been gathered.
We have discussed above (§3.1) how ship navigation involves a number of aspects, and that there is limited usefulness in analysing one without the involvement of the others. But capturing data relevant to all the aspects presents major problems. Even for collision avoidance (a relatively easily represented aspect of the task) it would be difficult to capture the unmediated visual information that an officer of the watch might well use. And although it should be possible in principle automatically to capture the data presented on an advanced plan position indicator, there would still be problems in formalising that information, just as there were problems in the formalisation of graphical information in the experiments of the present study. But if we go beyond collision avoidance, the involvement of several people on the bridge clearly implies managerial aspects to the task, that would be difficult to capture and formalise automatically; and even on a one-man bridge, even in fog, the navigational decisions are greatly affected by communication with external agents such as harbour authorities and other ships. Before ship navigation can be fully analysed using the present methods, there is clearly more work to be done in gathering appropriate information.
The problems in analysing ship navigation generalise easily to other complex tasks. We can imagine, in any complex system, the existence of sources of information that were either not monitored electronically, or difficult to formalise, or both. As well as the fairly obvious sights, sounds and smells, it is not uncommon in complex systems for the actions of an operator to be affected by factors relating to other people involved in the process. Keeping other people happy is not to be forgotten, but surely very difficult to capture and formalise.
The obvious way of attempting to perform a study in circumstances like navigation or other complex tasks would be to have a human observer recording significant events, and this could be fruitful; but there is the danger, at each of the stages of observation, recording, and interpretation, of the researcher's representation of the task interfering with discovering that of the subject being studied.
The faster dynamic tasks include riding bicycles; many computer games, discussed in §5; and car driving, which will be used as an example below (§8.2.4). These pose particular problems in analysis, to the formalisation of both situations and actions.
The problem with the representation of situations is that there is an information input of major importance from vision, in a way that can appear to have the character of pattern-matching; and in the cases of driving and riding, there is much potential for information to be gained from such senses as proprioception and balance, which might be difficult to capture. Even to model human performance in the tasks of this kind that are easiest to analyse—the computer games—one might have to apply some sort of pattern-recognition preprocessing to get a tractable description of situations. At least, for computer games, the presented information is available for analysis: in driving or riding, automatic sensors cannot yet collect the same kind of information, to the same detail, as humans can. Simulation for these live tasks is certainly not easy, as was reported in §4 for bicycle riding, and therefore this would not be an easy alternative for analysing the content of the skill. A practical approach would therefore have to rely on gathering what data can be gathered by more straightforward means, and hoping that an analysis based on these would match a human performance even though it was not identical.
The problem with the representation of actions is that there are in the case of driving and riding only a few analogue inputs (steering, power) that are used to perform the wide range of actions that we are able to discuss for these tasks. Detecting what action had been performed, or indeed intended, from a record of physical movements of the controls would be difficult, and until this had been done, no satisfactory analysis of the skills could be expected (see the analysis and discussion in §4). Even with computer games of this type, where the input is technically digital rather than analogue, typically most, if not all the control is via a joystick or mouse, and there is still a great problem in adequately formalising and recognising the higher-level actions, given only data on the very limited range of low-level signals. Despite one reported attempt to extract machine pole-balancing skill from human performance on a pole-balancing simulation (see above, §3.2), simply in terms of the primitive left and right movements of a joystick [79], it remains doubtful how near this approach can come to modelling the human skill itself, without making higher-level characterisations of the actions.
For this kind of game, players are usually performing against their limits, such as reaction time and coordination. An adequate description of these skills would want to take into account these limits in some way, which may include modelling some psycho-motor aspects of task performance. Even for tasks in which the psycho-motor aspect is not a critical limiting factor, it is possible that psycho-motor factors affect the way the task is performed: this would again mean modelling these factors.
If we imagine these preconditions to be satisfied, we could use the data gathered to reveal context structure to the task (whether by the methods used in this study, or by extensions and generalisations such as those discussed above, §8.1.4), and thus to progress towards interface redesign, addressing some of the problems of interfaces introduced in §1.2. The context structure could be made the basis for the interface, by being used as a fundamental unit of the organisation of the interface. It might help the immediate comprehensibility of this if the operator could agree meaningful names for each context. We could imagine, for example, one screen for each context, in an interface where one VDU is used to display many screenfuls of information. An important part of the interaction would be maintaining the appropriate context for the situation.
Within each context, the information that had been found relevant could be displayed. In general, we could expect the amount displayed at one time to be less than is generally presented simultaneously in complex system interfaces, but one should not lose sight of the value, and actual use, of redundant information in the same context, both to support a small range of alternative strategies, and to enable checking of the internal consistency of the data. The present study has not examined the use of redundant information, but one could extend the methods used here, to discover redundancy.
Some aspects of the style of the interface could also be based on knowledge gained from the analysis. If a context was highly ruly, the rules being derivable from only a small number of quantities, care could be taken on the appearance of the display to maximise the ease with which those quantities could be apprehended. This could well involve qualitative or symbolic displays, as well as the more usual continuous analogue or digital ones. But if the context did not have well-defined rules, and instead appeared either to be one where the information processing had a knowledge-based character, or one where the quantities needed were not sensed directly, one might want to design the display to enhance access to other sources of information, and the making of inferences, links, or analogies. Hypermedia-style interfaces come to mind here. For more subtle skills involving many small pieces of information, or graphic information, processed by pattern, one could design the display to enhance this ability, by ensuring that the important aspects of the pattern were salient.
If an interface were to be redesigned for a number of operators or users, the ease of using the currently suggested approach would depend on the extent to which the users all shared the same context structure and information use. If there were a lot in common, then the redesign could proceed in essentially the same way as for one individual. However, the present study would doubt whether individuals would be likely to share a lot in common in such a complex task, without at least extensive training designed to ensure conformity. If the context structure, only, were common to the different operators, and the information use different, then a redesigned interface could include all the information that any of the operators used in any one context. But if the operators' context structure were different, in terms of the divisions and boundaries between the contexts, and the higher-level rules governing transitions between them, it would be difficult to obtain a principled common redesign from the methods of the present study.
While discussing redesign, it may be pointed out that redesign of an interface is likely to change the way an operator performs the task, thus invalidating the analysis that led to the changed design. Another factor that would invalidate the design is if the user changed information use. Thus, in this paradigm, redesign should not be based on an analysis of operator's performance while that operator's representation was changing, but it would be valid if the representation had achieved stability, even if the action rules were still changing.
It is relatively easy to see how this methodology could lead to incremental improvements in an interface, particularly to do with prioritising the information that was actually used over that which was not, thus easing the workload of operators, and reducing the chances of overlooking important information. For the more difficult objective of identifying major deficiencies in the provision of information, a context analysis could provide the raw material for someone with extensive knowledge of the task to use their creative insight to suggest, for example, where a new source of information could relieve an intricate context structure built around a badly instrumented system.
Having suggested that this methodology is primarily able to support the redesign of interfaces for individual operators, we would agree that it would be counterproductive to design an interface to support any maladaptive strategies that might have been adopted by a particular operator. Such maladaptive strategies could not easily be detected on the basis of context structure alone, except by means of another expert's judgement on what information should be consulted in a situation. If, however, a detailed model of the rules of a particular operator had been obtained, from a deeper analysis, this model could be tested on a simulation of the task, to see whether the rules used were likely to lead into trouble or inefficiency in any situations-most likely those that were not frequently encountered, but possibly also where bad habits had consolidated. Finding such maladaptations could lead to the recommendation of remedial training on a simulator, focused on the kinds of situation where the model had shown potential problems.
This kind of detailed analysis of individual rules and their potential failures could bring a qualitative change in methods of human factors safety and risk assessment. Probabilistic methods of assessing the unreliability in the execution of a particular action cannot take into account the possible variation of reliability across different contexts, without having a context model. If errors could be analysed in a context-based way, there would be the potential of a very informative and precise attribution of causes to errors. The more accurately the rules of human task performance are known, the clearer will be the explanations of failures in that task.
The prospect, even a remote prospect, of having a rule-based model of operator performance in a complex task, stimulated the concept of a kind of operator support that invites the name, “Guardian Angel”. The concept is like that of a guardian angel, supposedly looking over the shoulder perhaps, remaining mostly in the background; understanding actions in terms of intentions; intervening when action and intention do not match, or where a harmful intention is formed, or where important information is overlooked. The intervention could be either giving advice, information, or asking a question to direct the attention to something. Like a guardian angel, such a system would be inherently personal. In order to relate some examples to common experience, we will here consider potential application to driving a car. This example is chosen not because it is typical of the kind of complex task considered in the present study (it is not), but in order that we may relate the concept to a task of which most adults have extensive experience.
Probably many of us would be very glad of a voice quietly telling us that there is a police car following behind. The potential value of this is recognisable irrespective of the practical difficulty of implementing this technologically. But when would a guardian angel system make such an announcement? Not every time a police car began to follow, for that might become annoying. If a guardian angel system had learnt that in every case when I knew a police car was following, I rigorously obeyed the current speed limit, then the observation that I was not being rigorous would enable the hypothesis that I had not seen the police car. That would be one truly helpful time to let me know. Equally well, if I was already cruising along at the speed limit, pressing my foot hard down on the throttle would be clearly inappropriate. A similar warning, delivered in a timely fashion, could keep me out of trouble.
This is not universally applicable, however. A fire-engine driver would not appreciate such advice, and indeed, there would be no such rule observable from a fire-engine driver's past behaviour. Here, a guardian angel system would not intervene, because the actions were within the normal range.
A guardian angel system would have to know about different classes of passenger, as well. We would not want it to give suggestions to the effect that I was driving slower than normal, when I had an aged relative as a passenger. On the other hand, if I forgetfully drove with my normal style for lone driving, I would appreciate a reminder (preferably visible, and only to myself) that I had a granny in the back.
In other examples, there might be no simple external explanation of the deviation from the normal range of behaviour. A guardian angel system might come to know what my normal performance was in keeping my place in a lane—how much I deviated each side of the mean, what the frequency of the deviations were, etc. Large oscillations are obviously undesirable, and if I started to exceed my normal limits of performance, it would be quite in order to suggest that I should reduce my speed. If information concerning my consumption of alcohol was also routinely available (or perhaps taking of some prescribed drugs) a guardian angel system might recognise the performance as belonging to a known category of substandard performances, for whatever the reason was. An ideal system might also know from experience what to do to reduce the risk of accident in these circumstances. This would be based on generalisation of many people's behaviour.
Probably most of us are aware of a wide variety of driving style, though we would be hard put to define exactly how to measure it. To design a general driver advice system would mean designing to the common factors of a large number of drivers. Such a system would not have the ability to discriminate between the same performance when done by different people, and the different implications of this. We would not want drivers with somewhat less motor control continually to be criticised for their lack of perfection, but it would be useful to be able to consider the possible reasons for an otherwise excellent driver to be driving in a way that might be reasonable for others, but distinctly bad for him or her.
Perhaps the most important distinction between a general advice system and a guardian angel system is in the likely response from users. With a general advice system, there would be external rules and standards, and it is easy to imagine a driver rejecting advice with the riposte that “It is perfectly safe!” The idea behind a guardian angel system is that the advice given would be like one's own advice, distilled from one's own performance, gathered and approved over long periods. If delivered appropriately, that advice should not suffer from the same disadvantage of being felt as fundamentally alien.
In order to work at all, such a system would need comprehensive access to information about the quantities or variables that affect task performance. Initially, there would be a learning phase, where the guardian angel system formed a detailed model of the user's task performance skill. The only advice that could be given initially would be of the same grade as from a general advice system, possibly tailored by user's choices, or by fitting the user into a stereotype.
In time, enough data would accumulate to allow the derivation of a representation, and rules. Further data would have to be continually added and analysed, to ensure that the rules remained current. If no input was obtained from the user, the rules would reflect what he or she did, rather than what he or she thought was good performance. However, one can see much more potential coming from a system that includes value judgements from the user on his or her own performance. Most people seem to be aware when they make a mistake, or do something that they would rather not repeat, and if this value judgement could be incorporated by the guardian angel system, it could form models not only of what the user did, but what the user thought was decent performance. This might lead even to the ability to suggest causes of poor performance, and suggestions for avoiding that.
In the European Community DRIVE Programme (Dedicated Road Infrastructure for Vehicle safety in Europe) there is a project, Generic Intelligent Driver Support (GIDS) [130], which aims to deal with similar issues, specifically for driving, including the idea of an adaptive interface: but they do not consider machine learning as a tool. The advantages of approaches using rule induction are firstly that the adaptation of the interface could in principle be closer than is possible using predefined stereotypes, and secondly that it provides a searching test of the adequacy of a representation for describing performance. If such a test is not carried out, it is easy to rely on a representation that only encompasses a small subset of the real task. This is related to the problem identified earlier (§2.3.1.5) in which formalisms may fail to represent a task adequately.
The clearest and most obvious application to training, of the analytic methods discussed in this study, would be to assess training's efficacy. Since training can potentially make a difference to the way in which a task is learnt, a detailed analysis of what has been learnt, in terms of contexts and rules, may reveal generic differences in the results of different training schemes, beyond the differences between the individual trainees. If the individual characteristics of the trainees were taken into account, there would be the potential for discovering whether different training regimes suited different types of people. In these cases, the context and rule analysis of task performance would be contributing more detailed feedback about what is learnt than is normally obtained through straightforward tests of speed or accuracy.
However, in the course of this study we have confirmed that it is more difficult to discover detail about task performance when a task is still in the early stages of learning, because in general the contexts and rules have still not stabilised. One outcome of the analyses performed is to show that different contexts differ in their degree of ruliness; and this suggests that even at the earlier stages of training one might be able to identify particular contexts where the rules were established relatively quickly.
Designing a training programme for a new task poses more problems. After such a program had been running for a while, analysis of the results of training, as above, might be able to guide a redesign. But this does not help in the initial design of training: for that, one would need general principles of what was learnable, and what a human would be likely to learn about a task. This overlaps with the problem of early design, which will be discussed below.
Related to the concept of training, we could ask whether the methods of analysis described in this study could form the basis of an assessment tool, to discover the suitability of different people to the performance of different kinds of tasks. The answer to this is by no means clear, but if an answer were to be found, it would most likely relate to parameters governing the structuring of a task, which would here be chiefly about contexts. If one were to study the task performance of subjects, in terms of rules and contexts, across a wide range of tasks, there might be consistent differences between people, for example in terms of the number of rules that could be comfortably accommodated in one context; the number of different items of information that were taken into account in each context; the number of contexts into which a given task was split; and the amount of intermediate processing necessary in the execution of the rules in any context. From these differences, it might be possible to factor out one or more dimensions of ability in general task performance.
To be able to help with early design, or (relatedly) to help with the construction of a training programme for a new system, a model of an operator's capabilities must exist prior to the analysis of an actual operator's performance. This model would have to be able to address the question, “how difficult is the task of controlling this system, given this amount of information?” An even more general question would be, “What information has to be provided to make this task doable?”, and we could imagine answering this latter question in terms of the former one, using the extra input of the cost of providing whatever information is needed. These questions are closely related to the idea of 'cognitive task analysis' which has been raised in the discussion of the literature above (§2.1.2), and in a more extensive focused fashion elsewhere [43].
Here, as previously, to answer these questions we need to know something of the parameters governing human ability to structure a task. If we then came up with a model of one possible method of performing a task, those parameters could be applied to that model, resulting in a judgement whether that particular method was humanly possible or not. A positive result should be reassuring, that the task was indeed possible, but should not be taken to imply that any human would actually perform the task in that way. But the converse would not be true: just because one found that a particular method was implausible for a human would not mean that the task was impossible. To prove that a task was impossible would be at least much more exacting, if not itself strictly impossible.
To design a training programme, or to derive human models which could be expected to arise from a (possibly null) training programme, would need a model of human learning as well as parameters governing what is learnable. For this reason, the automatic design of a training programme is a yet more distant goal.
In the second sea-searching experiment (§7), a context structure was derived based on explicit use of sensors. In contrast, during a task where the information was freely available, it would be more difficult to demonstrate the existence of a context structure, albeit easy to imagine. To set the idea of contexts on a firm footing, we should be able to derive such a structure without needing to monitor the information explicitly, nor relying on verbal reports of phases and information use. At the same time, room for improvement exists for finding more accurate and reasonable rules governing the actions taken. How could we envisage progress being made in these two areas?
The essence of the concept of context that has been introduced here is that it is useful for a number of purposes simultaneously. For regularly performed complex human tasks, it is economical to conjecture that a manageable number of rules for a limited range of actions should be closely associated with an information environment that: supports the application of those rules; is processable within the limits of human capability; and supports the rules necessary to switch to different contexts where appropriate.
One approach to this would be to start looking for a set of rules that fitted at all into a context structure: or, looking at the problem the other way round, to look for a context structure that divides rules up into suitable groups. The action rules that we have seen here each have conditions and an action: the conditions as a group, and the actions, can be true or false for any given example (here we are not counting the appropriateness of the context as a condition). What can we say about the truth of conditions and actions in the ideal model?
What this amounts to logically is this: if a rule is in its own context, and its conditions are true, then the action should be true. Conversely, if the action is other than a rule predicts, then it should follow that either the conditions are false, or the context is not proper to the rule.
To consider this in more detail, one may recognise the way in which a rule can divide up a set of examples. Thus any rule divides the set of examples into four:
The function of contexts then emerges in this fashion. The context for a given rule must exclude as many as possible of the examples where the conditions are all true, but the action false (i.e., other than the rule's action), and should include as many as possible of the examples where the conditions and action are both true, though this latter is less crucial. The context structure as a whole should do this as economically as possible for all the rules together, and in such a way that rules for transition between contexts are possible.
It would be easy to derive an unsatisfactory context structure by concentrating on one aspect while neglecting the others. For a given set of rules, division of a data set into a large enough number of contexts would presumably be able to separate off the examples with true conditions and false actions: but this would be likely to lead to the inability to form rules governing context applicability. Alternatively, concentrating on plausible contexts with clear transition rules would be less likely to result in the ability of the contexts to distinguish accurately the applicability of rules. Again, if the contexts were chosen in advance, rules could be induced wholly inside those contexts, which would guarantee that the contexts served to limit the applicability of the rules, but to be sure of doing this, the rules would most likely be very numerous, and would be less likely to predict actions accurately.
Satisfying all these constraints for a context-based rule system poses a very challenging task. Could these constraints actually be sufficient to obviate the need for explicit knowledge of human information-processing limitations? After all, if the data is all taken from human performance, the constraints should in principle be able to be discovered from the data, not vice versa.
How could an answer to this question be approached? If we could define a goal, in terms of the desired characteristics of a representation, we could perhaps set up a heuristic search (in effect, through representation space), to find a representation which both conformed to expectations about context structure, and allowed action rules to be induced that accurately predicted human task performance. Unfortunately, it is not clear how to define such a goal; nor, for any given goal, is there any obvious way of determining whether it is attainable at all. A less explicitly goal-oriented approach would be to define a measure of success of a representation, and search for better ones for as long as desired. This is one way of looking at the process that has been followed in this study: the main criterion of success of a representation has been the performance, compared with the default rule, of the rules induced with that representation.
But this study has been searching for something at a deeper level. This is that the success of a representation is the extent to which it divides up the data into different contexts which are recognisably different both internally, in terms of induced rules, or ruliness; and externally, in that there is some method, or there are some rules, for determining either which context should apply to any situation, or when a transition from one context to another should be made. More criteria which have not been discussed extensively are that the representation should minimise simultaneously the number of contexts, the number of rules in each context, and the information and amount of processing needed both to execute those rules, and to determine the context. The trade-offs inherent in attempting to satisfy these conflicting criteria have yet to be determined. In short, this thesis suggests that something like what is called here context constitutes a naturally occurring structural element in the analysis of human performance of complex tasks, and that therefore representations of the control of complex systems should incorporate context as a salient feature. Still better criteria for approximating human representations should be a goal for future work.
The analyses in this study have used floating-point quantities (effectively continuous from a human point of view). This is because recent induction algorithms have been designed to process floating-point values, and to introduce their own divisions of these quantities into qualitative ranges. However, the literature referenced in §2.3.3.5 considers that humans often treat continuous quantities as if they were composed of a small number of discrete qualitative ranges. Also, in §3.2, we looked at the problem of dividing up continuous variables into qualitative ranges for the control of a dynamic system. This leads on to considering the potential of extending the context analysis to incorporate qualitative divisions, rather than leaving it to the induction programs.
This could be done by insisting that within any context, the qualitative ranges that are used by the different rules must be harmonised. It is clear that CN2, at least, does not consider this when constructing rules—see the rules in Appendix B, in which each quantity has many different splitting values, or thresholds, to use the terminology of §3.2. To implement a harmonisation of qualitative ranges would either need a major change to a rule-induction algorithm, or a possibly unwieldy arrangement whereby different thresholds were tested out for efficiency by reinducing all the rules for the context, using existing induction algorithms. Another implementation problem is that it is not clear how to set the trade-off between accuracy of induced rules and number of thresholds.
But if this were indeed possible, the information presented to the operator of a redesigned interface could be presented in a discrete, rather than an analogue, form, and this would enable a great reduction in the amount of information presented. Effectively all the unused information from the high-resolution sensors would be cut out, leaving only the essential bits. Whether or not this would be a good idea overall is difficult to determine; but it would certainly provide feedback about whether the analysis was accurate or not. If the operator's performance was impaired by having only qualitative information rather than quantitative, one would be led to ask what that extra information was being used for. On the other hand, it is conceivable that the operator would find the task easier, due to the simplification of the presented information, and the reduction of distracting extraneous information.
If rules are specific to contexts, it makes sense to consider the actions specified by them as proper to contexts as well. This implies another potential constraint on, and another way of discovering about, contexts. The constraint is that each context should have a limited number of possible actions: in practice, if the number of rules is already restricted, this means that those rules must be predicting only a small range of actions. Independently of rules, one could use the co-occurrence of actions as another guide to the sections of data belonging to different contexts, because one would expect each context to have a peculiar pattern of actions.
However, it is also important to remember that actions from the point of view of cognitive analysis are not necessarily the same as individual button-presses, or whatever else the most basic interaction with the system is. As in §6, an analysis of sequences of actions may be necessary to establish more correctly what the cognitive actions are. Such an analysis may be called for if one were to find that a context did contain unreasonably many individual actions. Using better-represented actions could be expected to clarify context structure as well as to improve the apparent ruliness within contexts.
The extension of machine learning techniques in the analysis of aspects of human task performance has been discussed above. A question which naturally arises from this is, can machine learning alone learn how to perform a task in a similar way to a human, without knowing anything about how humans have actually performed it? If this could be done, it would clearly relate to early design (§8.2.6), and possibly to training. The ultimate goal here would be the automatic analysis of a task that had not yet been mastered, and the generation of a training programme to teach it to humans.
The answer to this question depends on what we mean by 'similar' to a human. The strongest criterion would be a Turing test—whether other people could distinguish between the performance of humans and the performance of the machine-acquired skill. The possibility of such a skilled machine for complex tasks is limited by our knowledge of the information-processing structures of the human, and so progress towards that goal would come with the refinement of our knowledge about human skill and knowledge. But there are also weaker criteria. As Michie & Johnston pointed out [81], it is becoming increasingly important that such knowledge as is acquired automatically, is accessible to humans, for checking its validity and applicability. But in order to fit into this 'human window', it is not strictly necessary to perform a task in a human-like way, but only to have a humanly manageable structure to it. A context structure, irrespective of how closely it corresponds to actual human practice, is certainly a reasonable approach to providing just the kind of structure to a task that it would be relatively easy to understand. This is because a context structure is a way of minimising the amount of information, the number of rules, and the complexity of processing, that has to be dealt with at any time. It would be interesting and significant to know what features of a task structure are strictly implied by this quest for minimising cognitive difficulty. This would be a valuable extension along more formal lines.
After deciding on the form of what is to be learnt, the next problem for machine learning to tackle is how to go about learning the content. If we were to suppose that humans are good at learning new, unstructured problems, then machine learning might also profitably gain from copying a model of human learning. In this case, advance in machine learning and advance in the study of human learning would share a direction for progress. Hence, our last consideration is directed towards human learning.
Investigating parameters for the structure and content of human task performing skill has already been mentioned. The contribution of this study is in suggesting the importance of rules and ruliness, and the centrality of the concept of context; and in suggesting some of the central parameters which might govern contexts: amount of information available; number of rules; complexity of higher-level rules for determining context; processing requirements in the gathering of information into a usable form, and in the execution of rules.
We have seen above (§7.2.7) how some contexts appear to be well-defined, but not ruly, on the basis of rule-induction from obvious attributes. This has suggested a distinction paralleling Rasmussen's, between contexts where the information processing has more knowledge-based character, and when it has a more rule-based character. Here we draw attention to the possible need to model these kinds of context differently. Since it has been supposed that the knowledge-based approach comes before the rule-based or the skill-based, a model of learning could address the question of how general-purpose problem-solving contexts become gradually differentiated into specific, efficient, task-oriented rule- or skill-based contexts.
We have noted above (§6.4.6) how the methods of this study are not well-suited to the study of the early stages of learning, and indeed to the study of the learning process itself. This was partly because it is difficult to obtain sufficient data at a stable early level of skill. One plausible idea for circumventing this would be to arrange a study of subjects whose practice would be strictly regulated, interspersing periods of learning and improvement with periods when just the right amount of practice was done so that the performance remained at a stable level, neither improving because of too much practice, nor declining through too much time between the practices. Whether this could work, even in principle, would depend on whether what was learnt was the same as what was forgotten. If one could, by this means or any other, gather a much larger amount of data from the early stages of learning a skill, it would become possible to use the kind of methods both that have been used here, and that have been discussed as improvements.
This study has furthered the aim of modelling cognitive aspects of complex control tasks, by analysis of human performance in terms of information and ruliness, using rule-induction tools and some concepts from cognitive psychology. The same inter-disciplinary approach could be greatly extended, potentially illuminating a broad range of topics concerning learnt human skills and how to support them.
The green ‘help’ buttons on the right of the lower half of the screen will cause more information to be displayed about how this simulation and interface work, etc. If you are a beginner, please start by reading How to Use the Help Screens, and Beginners' Introduction.
See the appropriate section for instructions on how to start, stop and replay.
Your actions will be recorded for posterity in the interests of scientific enquiry, though your identity will be kept confidential!
How to use the help screens provided here.
Each of the buttons on the right provides a (textual) piece of help on the subject indicated on the button label, which appear in the same space as this text is now appearing. If there is more text than will fit onto one screen, you may move through it using the blue buttons on the left of the lower half of the screen. If a move is impossible, you will be beeped at, but nothing more serious will happen.
If pressing one of the green buttons results in a beep, this means that the file for that piece of help text is not available. If this happens, or if there is anything which you think should be explained, or you would like to be clarified, that is not, please inform the program author.
It is not possible to see the help screens while in the middle of a run, as this would interfere with the realism of time pressure in decision making. However, when you stop the run, you may continue to page through the help until you start your next run, or quit from the program.
If you have not studied the other screens already, the suggested order is:
This is the explanation for beginners, which you should read if you are unfamiliar with the task of mine hunting. You will need to study all the help information at some point, otherwise you will probably assume something incorrectly. This is simply an overview.
You are in command of a mission to sweep an area of sea bed and dispose of any mines you find. At your disposal are
First you look for a suspicious target. Having found one, you manoeuvre the ship to a position between 100 (red circle) and 200 (green circle) metres away, and bring the speed down so that the ship won't drift away while your mind is on other things. Next, you put out the ROV, and fly it towards the target until it appears properly on your camera view, so that you can identify it. If the target is an old oil-drum, you can just leave it at that, and bring the ROV back in. If it is a mine, you now have to disable it.
You are responsible for flying the ROV to a position where an explosive charge can be attached to it. How this is done is not part of the game, but you are told when it has been done. Then you get away from the mine, and when clear you can detonate it. Job done. Then see if there are any more.
The cable is fairly strong, and you can pull the ROV back toward the ship by reeling in the cable.
Read the sections on how to use the help screens, and on the interface and the response to clicks. To get as far as reading this you have already discovered most of the essentials. While learning the task, ignore the cost of information, turn all the sensors on until you have a good idea of how you are going to perform the task. Then you will need to get a feel for the controls of the ship. Read the sections of help about the ship, and about the general display, and without bothering at all about mines or the score for the moment, manoeuvre the ship around, and experiment with the display changes, stopping when you like. You could also replay the ship demo run. When you are fairly happy with that, try the ROV. Read the sections of help about the ROV, the cable, and the sea bed. Perhaps look at the ROV demo run. Try it, and have a good look from all sides at how it responds to your controls. Then read the section on the targets, and see if you can manoeuvre the ROV close to one.
Then you will be ready for the full game. Read the sections on the game object and scoring, and have a go. Good luck! Two requests.
The object of the game
After starting the game, when you reduce the scale of the plan, you will see a red-bordered rectangle, (to the North-West) which defines the area which you are to check over and clear of mines. You start inside a green rectangle, and you must return to this after sweeping in order to complete the task.
Inside the red rectangle, the task is
The first two parts of the task are essential, i.e., you cannot complete the task without doing these. The others are secondary, in that you may complete the task but you will lose points.
After you have become reasonably skilled at the game, getting a high score becomes the priority. To achieve the best score, you will have to use only the information you need, by turning off what you do not need at any time.
Speed and caution are not easily compatible, and you will have to decide how to trade off the different objectives, in the light of the scoring system (q.v., which defines the relative priorities from the point of view of the person setting the task).
The scoring system
The main surprising thing about the scoring is that there is a cost in points for using information. The purpose of this is that after you feel confident that you know what is going on, you can turn off the information that you do not need. The way the information is priced means that when you are learning, there will be a large negative score. You are to ignore the score completely until you feel happy that you know what is going on well. Your objective is first to learn how to do the task (ignoring the scoring absolutely), and only then to attempt to achieve the highest score you can by judicious switching off of information.
For completing the task (as described under ‘object’) there is a bonus of at least 20000. If there are adverse weather conditions, you may get more. You cannot get a good score without this. For each mine that there is, when you detonate it after priming it you will get a bonus of 500. When you identify any target by clicking the correct button, you get a bonus of 500. However, clicking on the wrong identification will lead to a penalty of 500 under ‘infringements’. So don't just guess what the target is without looking. You cannot complete the task without identifying all the inert targets and detonating all the mines. If a mine explodes while a vessel is within 100 metres of it, the vessel will be damaged. How much depends on how near it was to the explosion, and the penalty for damage is calculated accordingly. The penalties are large. If you navigate the (centre of the) ship within the area of possible damage of a mine or unidentified target, you will be penalised for breaking safety regulations, at the rate of 10 points per half second, irrespective of whether or not it is a mine or whether it explodes. Distances are calculated in 3-D. The information on the sensors is paid for in points. The cost of each sensor is shown on it, when that sensor is off. The total cost per half-second, of all the sensors that are currently on, is shown on the display, as is the cumulative total cost of information till now. Finally, time ticks away steadily, and you lose 1 point for every half second that you take to complete the task.
The number, type and position of the targets are randomly allocated whenever you start a new run. The scoring is designed to allow for this, in that you will take longer if there are more targets, but you will accumulate more bonuses. With luck (and a bit of skill) your score should come out positive in the end, if not first time then certainly after a few trials!
If you are really curious to know about other people's scores, look at the scoreboard, which gives each player's best score to date. Your own scores (on the current configuration) are available to you every time you have this help screen.
The purpose of the simulation
This simulation game is intended to provide a semi-complex task for experiments into matching the presentation of information to the user with the representation embodied in the user's ‘mental model’ of the task/system.
The main way in which this is done is by recording what actions are taken in what situations. The way that the situations are categorised depends on what information you use for making your action decisions. This will become apparent when you have reached a level of competence that permits you to turn off all the sensors you do not need.
The design of the simulation as a whole
The simulation is intended to bear a resemblance to an actually possible complex task, and thus be inherently interesting and challenging.
Not all of the information and controls could be accommodated onto one screen comfortably. This means that there have to be some changes in the information and controls displayed over time. The principle governing the way in which the task is split up is that the information most directly relevant to the performance of a control action is displayed with it. Thus, for example, the control of the ship's rudders is displayed along with the information about what the setting is currently (both graphically and numerically), and what the ship's heading is.
The sensors and effectors are grouped together following the obvious physical, mechanical or functional sub-systems, rather than having higher-level connections. Thus, the interface that you see is designed to be the kind of interface that you might come across for a system that has not undergone detailed task analysis or analysis of the user's mental model.
The principles of the interface
As will have already struck you, the screen has four differently coloured backgrounds. The rationale for this is simply as follows.
The blue section contains active buttons that change either what information is displayed, or the way in which it is displayed; but these buttons do not affect the simulation itself. They act at the ‘presentation’ level.
The next section (black background) provides information in either a graphic or a verbal form. The red-backed section provides numerical or verbal information. The black and red sections respond to mouse button clicks by toggling the sensors on and off. If a sensor is off, its cost in points per half second is displayed in place of the information. (These are ‘monitors’.)
The green-backed section provides your controls over the process. As you read this help text, they merely enable you to select which help text is loaded, but during a run they cause actual or demanded values to be set on the various controls. These values will then appear in the red section, so you should be able to see that something has changed as a result of your mouse click.
Two general principles are followed: firstly, if a (legal) click has no actual effect (e.g., you selected something that was already the case, or something impossible) you will receive a beep; secondly, where possible, information relevant to the state of some variable is matched in the same row as the control buttons that allow its change.
The General Position Indicator and its Display Changes
The general position indicator display, on the top half of the screen, can be manipulated when the game is running by means of the blue ‘display change’ buttons on its left. The various ‘fix’ buttons make what is fixed stay in the same place on the screen (strictly, the same scale distance away from the centre of the screen). What is currently fixed is displayed at the bottom left of the graphic display. The ‘centre’ buttons bring the named object to the centre of the screen, but do not affect what is fixed.
The scale buttons alter the scale by a factor of two, either way. The grid lines remain at 100m intervals, and since you cannot apply a ruler easily to the screen (nor is there the time or motivation to do so), the actual value of the scale is not given. You can work out what it is roughly by observing the grid lines.
The plan and section buttons will be self-evident when tried. This graphic display is very useful to give you an idea of what is going on. This is essential while learning about the task. However, its use is priced highly, and when you are reasonable competent at doing the task, you will want to turn off this display unless you really need it.
How the mouse button clicks operate
The interface is deliberately limited to allow at most one mouse click every half second. Very rapid clicking is pointless, since the clicks are not stored up. Here is how to tell what is happening.
When you press (and hold down) the left or middle mouse button, one of three things could happen.
There is also one kind of action which is not done with the mouse, but should not concern you until you are well practiced. If you know exactly what is going on, but you do not wish to do anything for a considerable time (while the simulation continues), you may press one of the number keys, 1 to 9. (1 is the only one you are likely to want.) This causes the simulation to move on by about 10 seconds times the number you press, without showing any display, in the shortest time possible. All the scoring continues just as if you had not pressed anything during that period. Be warned that this cannot possibly increase your score.
The sea bed
The sea bed, in these waters, is muddy and gently sloping. It gives a few, fairly random, echoes to your sonar, which appear as grey dots on your general position indicator. This is enough to give you a general visual impression of where the sea bed is, when you look at the North-South or West-East sections on your computer generated display. For accuracy, however, you must rely on your digital instruments, which give you vertical measurements of the sea depth (at the ship), or the height and depth (of the ROV). In the home area, the sea just happens to be 50m deep, and in the area to be swept it is close to this value, sloping only very gently.
The main hazard of the sea bed itself (as opposed to the targets) is that the ROV may get stuck in the mud. This is tedious, and wastes time.
The targets
In the area to be swept, you may find two kinds of target.
Having identified these types of mine, your task is to fly the ROV to a position where someone else will actually do the job of priming it—how this is done does not concern us in this game, but it could be the fixing of a small explosive charge to the mine, using some kind of robotic arm. What you need to know is that in order for this priming to be done, you need to bring the ROV within 5 metres of the mine (range shown on one of the sensors), at a Ground speed of less than 0.2m/s. As soon as these conditions are fulfilled, the priming will be done instantly, and the word ‘Ready’ will appear in the green ‘detonate’ button on the top half of the screen. Any time after this, pressing that button will result in the mine exploding, and your being credited with points accordingly. Don't do it until both your vessels are over 100 metres away! The mines are acoustically set off, but running into them makes a loud clang which also sets them off. Type 1 mines explode on contact if the ROV is within 2m, For type 2 mines this is 1m, but they do more damage. This will probably result in the ROV being destroyed and the run ending. If you use too much motor too close to the mine, it will go off and you will have an enormous damage penalty. You are safe using all full thrusters if you are 5m or more away. Closer than this, the effect is proportional to distance and to the square of the revs from each thruster.
While any target is still either unidentified or dangerous, two circles will appear on the general display if the ship is within 400 metres of it. The outer (green) one is 200 metres from the target, the length of the cable. The centre of the ship has to be within this circle for the ROV to be able to reach right up to the target. The inner, red one is the 100 metre danger zone. If the centre of the ship goes inside this, your safety infringement penalty will grow rapidly.
The ship model
The ship is 60 metres long. It has twin propellers that can be operated independently, and twin rudders that operate only together. There is also a bow thruster, which gives a smallish sideways and turning force, most useful and effective when the ship is moving very slowly through the water. It takes a fair time for a propeller revolutions demand to take full effect—the revs only change at a fixed low rate. Each of the components that can be altered has five possible demand values: zero; full either way, and part either way.
The ship is equipped with a sonar that will detect all suspicious objects (‘targets’) on or near the sea bed, up to 500 metres away from the centre of the ship, in all directions equally. However, this sonar will not distinguish between the different types of object. It also picks up other random echos from the sea bed, within 500 metres or more, and it has a clever (computer-based!) system integrating information from sonar and radar, and displaying it in various ways: plan or section; various scales; various things fixed or centred. This forms the main display which is always present on the top half of the screen. In the ship's own graphic display, there is a diagram of the ship's heading, speed and rudder position along with a verbal indication of how each rudder is performing (useful to know if you're trying to figure out why the ship isn't turning!).
The digital sensors include the actual propeller and bow thruster revolutions, and their demanded values; the rudder angle and demand; The surge (i.e., forward speed) and sway (i.e., sideways speed); the heading of the ship, the heading of the nearest target and the distance to it; and the depth of the sea at the centre of the ship.
If you encounter non-calm weather conditions, you will find the graphic display most helpful. You can easily figure out what most of the signs represent when you alter the weather conditions. The red line is the ship's velocity relative to the water, the green the water's velocity relative to the ground, and the yellow is the ship's velocity relative to the ground, which is the thing you are most interested in. This explains why it is drawn most saliently.
The model is a simplification of a model, previously held at YARD, of a Mine Counter-Measures Vessel (MCMV). The chief simplification is in restricting the motion of the vessel to three, rather than the full six, degrees of freedom, namely: surge (forward), sway (side), and yaw (rotation about a vertical axis). Heave (vertical motion), roll (about a fore–aft axis), and pitch (about a lateral axis) are set to zero at all times. Within the bounds of this simplification, the modelling of the hydrodynamics and other factors has stayed fairly closely to the earlier model, with the main exception of the rudder, which is less true to life (due to its potential analytical complexity). The maximum speed is around 8.5m/s (c. 17kt.) which is reduced very slightly when towing the cable and ROV.
Stopping the ship is difficult, since it has so much momentum. If you are going ahead, put both propellers full astern, and when you reach about 1.1 metres per second “surge” speed, stop the propellers. The time it takes for the propellers to stop will be roughly equal to the time it takes the ship to finish stopping.
The ROV model
ROV stands for Remotely Operated Vehicle, and it is a small unmanned submarine used to approach potentially dangerous objects, to examine them and perform any necessary operations. It is attached to the ship by an umbilical cable (q.v.) which carries instructions and information. The ROV is carried in the ship while not in use, and while it is in, its controls cannot be used nor its display seen.
The model of the remotely-operated vehicle is largely the author's own invention. It has two main horizontal thrusters, which can operate independently, and one vertical thruster, located in the centre of the vehicle. There is no rudder, and the directional controls use the main thrusters differentially. These are driven electrically and respond quite quickly. The shape of the ROV may be imagined as based on an oblate spheroid (smartie shape).
The main sensor is a camera which has a range (optimistic) of 15m in the underwater conditions. This is tiltable up and down, up to plus or minus 1 radian (about 60 degrees). It cannot pan, but always points towards the front of the vehicle. The camera view is integrated with information from the ship, showing the position of targets that are still out of sight as conventional symbols, irrespective of the type of target. The ROV graphic display also gives a visual indication of direction and camera tilt, in the form of imaginary vertical lines at each of 16 points around the compass. This also gives a good graphical impression of turning. Note that when the ROV is in (i.e., not deployed) it is an error to select the ROV display and controls. To deploy the ROV, you must use the control to be found in the cable section (UMB). Other sensors show the demanded turn; the depth below the surface and height above the sea-bed; the speed through the water forwards (surge), sideways (sway) and downwards (heave); the heading of the ROV, and the heading and range of the nearest target that has not been dealt with, if within 500m. As far as possible, the sensors that relate to each other have been placed close: thus, the heave sensor is in the next row to the controls of the down thruster.
The model keeps roll and pitch always at zero. The remaining four degrees of freedom are modelled very simply, with no hydrodynamic cross terms, only simple drag. (This is quite unlike the YARD ROV model in the mockup simulator.) The ROV can reach a speed of over 6m/s unhindered, but in practice the umbilical cable (q.v.) restricts this severely. The ROV sticks in the muddy sea bed very easily, and can be difficult to extract. You may have to give it a tug with the umbilical cable (which fortunately is quite strong in this model!). Currently, collision with the ship is not modelled, and they are capable of passing through each other obliviously.
The umbilical cable
The umbilical cable is 200 metres long, neutrally buoyant and, in this version, fairly strong and elastic—the force needed to snap it is 10kN (about 1 ton force) and it will stretch by 10% of its length before breaking. You can break it by violently mishandling the controls of the ship and ROV. The cable is not without water resistance: it can be very noticeable at times.
Inside the ship, the cable is wound round a drum or capstan, over which it can slip. This means that we have control of two quantities: 1) the tension at which the cable slips over the drum, and therefore is payed out if there is any spare, and 2) the speed at which the drum is turning, which dictates the speed at which the cable is being taken in, if is it not slipping. You can tell whether the cable is slipping, by comparing the set payout tension with the tension of the cable at the ship (displayed adjacently). If the tension at the ship reaches the payout value (even if momentarily) the cable will slip. The tension and speed can operate together: i.e., the cable can be set to be winding in if the tension is less than the fixed amount, and paying out if it is over that amount. Pulling in the ROV can be quickly done by setting maximum tension and take in speed together. In addition, the total length of cable out, and the actual distance between the ship and the ROV, are displayed, which allows an easy estimation of how straight the cable is.
Placed with these are the controls to put out or take in the ROV from its dock in the centre of the ship. Taking in can only be done when the cable length out is at the minimum value of 3m. Winding in the cable automatically stops at this length.
Also, here are the numerical versions of the weather parameters, in case these are not easy to see on the ship graphic display. The directions are in degrees clockwise from North, like vessel headings, the speeds are in metres per second, and length and height in metres.
How to start, stop and replay
This is simple. Click on the “Start” button in the upper half screen. All the variables are re-initialised. When you start, all the sensors and graphic information is turned off. To see what is going on, you will have to turn some of the sensors on by clicking the mouse buttons when the cursor is in a graphic or sensor area.
The run to be replayed will be the one indicated in the red section in the lower half screen, just to the right of this. You may choose which one you want by using the buttons “Select Next Run” and “Select Run Before”. Having chosen the run you want, click on the Replay button in the upper half screen.
To stop a new run, click on the “Stop” button in the top half screen. During a replay, no buttons are active. You must use the ESC key if you want to stop a replay.
Please inform the program author if there is any other term you do not understand.
These are rules obtained with the representation RT01,
from data generated by the author.
All the material in typewriter font has been
output in that form by one of the programs. Many lines of output
have been taken out, but what is left has not been altered.
Inconsistencies are due to the different versions of the programs
used as program development proceeded.
The rules are presented here in order to illustrate the operation
of CN2, and the general nature of the induced rules.
However, these rules are not presented as
plausible candidates for rules that humans might use.
The figures in square brackets indicate how many of each class is
covered by that rule. Thus, [15 0 0] means that all 15 of
the examples falling into the category defined by the three
conditions have Port_Ths_Half_Ahead as their action
decision class. Similarly, [23 11 14] indicates that
there were 48 examples within the scope of the two conditions,
and of those, 23 had class Port_Ths_Half_Ahead,
11 had class Stbd_Ths_Half_Ahead and 14 had the class
value NO_KEY. This latter rule is less accurate than the
former one.
The larger the numbers, the broader the coverage, and the more the numbers are other than in the appropriate place, the less accurate is the rule.
*------------------------*
| UN-ORDERED RULE LIST |
*------------------------*
IF 0.65 < rov_speed < 2.33
AND rov_port_revs_demand = stop
AND rov_stbd_revs_demand = h_ahd
THEN class = Port_Ths_Half_Ahead [15 0 0]
IF rov_height > 1.80
AND rov_port_revs_demand = stop
AND rov_stbd_revs_demand = h_astn
THEN class = Port_Ths_Half_Ahead [7 0 0]
IF rov_degrees < 31.50
AND rov_speed > 0.31
AND rov_target_range < 10.10
THEN class = Port_Ths_Half_Ahead [7 0 0]
IF rov_target_range > 137.35
AND sub_display = rov
THEN class = Port_Ths_Half_Ahead [23 11 14]
IF rov_target_range < 56.75
AND rov_port_revs_demand = f_ahd
THEN class = Port_Ths_Half_Ahead [16 12 10]
IF rov_target_head > 135.00
AND rov_speed > 0.22
AND rov_r < 0.17
AND 6.75 < rov_target_range < 7.45
AND sub_display = rov
THEN class = Port_Ths_Half_Ahead [7 0 0]
IF rov_height > 31.75
AND rov_port_revs_demand = f_ahd
THEN class = Port_Ths_Half_Ahead [36 25 36]
IF rov_target_range < 34.40
THEN class = Port_Ths_Half_Ahead [89 79 148]
IF rov_height < 17.05
AND rov_speed > 0.48
AND rov_port_revs_demand = h_ahd
AND rov_stbd_revs_demand = stop
THEN class = Stbd_Ths_Half_Ahead [0 15 0]
IF rov_speed < 0.58
AND 0.13 < rov_r < 0.31
AND rov_target_range > 5.00
AND rov_stbd_revs_demand = stop
THEN class = Stbd_Ths_Half_Ahead [0 12 0]
IF rov_target_range < 59.80
AND rov_port_revs_demand = h_ahd
AND rov_stbd_revs_demand = f_ahd
THEN class = Stbd_Ths_Half_Ahead [0 7 0]
IF rov_target_head < 243.00
AND rov_port_revs_demand = h_astn
AND rov_stbd_revs_demand = stop
THEN class = Stbd_Ths_Half_Ahead [0 6 0]
IF rov_r > -0.01
AND rov_target_range < 32.60
AND rov_stbd_revs_demand = f_ahd
THEN class = Stbd_Ths_Half_Ahead [1 5 0]
IF rov_degrees < 104.00
AND rov_stbd_revs_demand = f_ahd
THEN class = Stbd_Ths_Half_Ahead [10 27 21]
IF rov_target_range > 124.15
AND sub_display = rov
THEN class = Stbd_Ths_Half_Ahead [38 37 36]
IF 5.45 < rov_target_range < 10.50
THEN class = Stbd_Ths_Half_Ahead [35 36 52]
IF rov_target_range < 97.15
AND rov_stbd_revs_demand = f_ahd
THEN class = Stbd_Ths_Half_Ahead [29 41 35]
IF sub_display = ship
THEN class = NO_KEY [0 0 340]
IF sub_display = umb
THEN class = NO_KEY [0 0 61]
IF rov_speed < 0.65
AND rov_r > -0.09
AND rov_target_range > 4.95
AND rov_stbd_revs_demand = h_ahd
THEN class = NO_KEY [0 0 21]
(DEFAULT) class = NO_KEY [194 185 654]
And these are the results of testing those rules, first with the data from which they were derived, and second from another similar set of data. The default rule accuracy in these cases would be 654 / 1033 = 63.3% and 320 / 444 = 72.0%.
PREDICTED
ACTUAL Port_Th Stbd_Th NO_KEY Accuracy
Port_Ths 79.00 21.00 94.00 41%
Stbd_Ths 56.00 38.00 91.00 21%
NO_KEY 85.00 34.00 535.00 82%
Overall accuracy: 63%
PREDICTED
ACTUAL Port_Th Stbd_Th NO_KEY Accuracy
Port_Ths 31.00 9.00 21.00 51%
Stbd_Ths 42.00 5.00 16.00 8%
NO_KEY 60.00 16.00 244.00 76%
Overall accuracy: 63%
*------------------------*
| UN-ORDERED RULE LIST |
*------------------------*
IF rov_off_head > 43.00
AND rov_height < 40.20
AND rov_speed < 1.33
AND rov_target_range < 133.35
AND sub_display = rov
THEN class = Pure_Turn_Stbd [14 0 0]
IF rov_off_head > 8.50
AND 6.25 < rov_target_range < 7.60
THEN class = Pure_Turn_Stbd [6 0 0]
IF rov_off_head > 29.50
AND rov_height > 34.45
AND rov_speed < 1.15
AND rov_target_range > 121.75
AND sub_display = rov
AND rov_turn_demand = strait
THEN class = Pure_Turn_Stbd [12 0 0]
IF 10.85 < rov_height < 42.95
AND rov_speed < 0.15
THEN class = Pure_Turn_Stbd [5 1 0]
IF rov_off_head < -29.50
AND rov_height > 4.20
AND 0.09 < rov_speed < 2.85
AND sub_display = rov
THEN class = Pure_Turn_Port [0 17 0]
IF sub_display = ship
THEN class = NO_KEY [0 0 224]
IF -10.50 < rov_off_head < 11.00
THEN class = NO_KEY [0 0 73]
(DEFAULT) class = NO_KEY [34 23 331]
The performance of these rules looks better, but in fact this is
due to the greater proportion of NO_KEY events. The
overall accuracy is still very similar to the performance of the
default rule by itself.
PREDICTED
ACTUAL Pure_Tu Pure_Tu NO_KEY Accuracy
Pure_Tur 34.00 0.00 0.00 100%
Pure_Tur 6.00 17.00 0.00 74%
NO_KEY 52.00 0.00 279.00 84%
Overall accuracy: 85%
PREDICTED
ACTUAL Pure_Tu Pure_Tu NO_KEY Accuracy
Pure_Tur 8.00 1.00 0.00 89%
Pure_Tur 7.00 4.00 1.00 33%
NO_KEY 17.00 2.00 182.00 91%
Overall accuracy: 87%
The accuracy of the default rule in the first case (training examples) is 85.3%. In the second case (test examples), it is 201 / (9 + 12 + 201) = 201 / 222 = 90.5%
**RULE FILE**
@
Examples: RT01s09a.exs
Algorithm: ORDERED
Error_Estimate: LAPLACIAN
Threshold: 10.00
Star: 10
@
*ORDERED-RULE-LIST*
IF sub_display = ship
THEN class = NO_KEY [0 0 340]
ELSE
IF sub_display = umb
THEN class = NO_KEY [0 0 61]
ELSE
IF rov_speed < 0.65
AND rov_r > -0.09
AND rov_target_range > 4.95
AND rov_stbd_revs_demand = h_ahd
THEN class = NO_KEY [0 0 21]
ELSE
IF rov_height > 2.00
AND rov_r < 0.03
AND rov_target_range < 4.85
AND rov_stbd_revs_demand = stop
THEN class = NO_KEY [0 0 15]
ELSE
IF rov_target_head > 2.50
AND rov_speed > 6.06
AND rov_port_revs_demand = stop
THEN class = NO_KEY [0 0 10]
ELSE
IF 0.35 < rov_height < 1.10
AND rov_speed < 1.75
THEN class = NO_KEY [0 0 6]
ELSE
IF rov_target_head < 333.00
AND rov_speed < 0.09
AND rov_port_revs_demand = stop
THEN class = Port_Ths_Half_Ahead [5 0 0]
ELSE
IF rov_speed < 0.58
AND 0.12 < rov_r < 0.31
AND rov_target_range > 5.80
THEN class = Stbd_Ths_Half_Ahead [0 12 0]
ELSE
IF rov_target_head < 187.50
AND rov_r > 0.20
THEN class = NO_KEY [0 0 6]
ELSE
IF rov_height < 33.50
AND rov_speed > 0.49
AND rov_port_revs_demand = h_astn
THEN class = NO_KEY [0 0 7]
ELSE
IF rov_target_head < 264.00
AND rov_speed > 0.20
AND rov_port_revs_demand = h_astn
THEN class = Stbd_Ths_Half_Ahead [0 7 0]
ELSE
IF rov_r < 0.02
AND rov_target_range > 161.15
THEN class = Port_Ths_Half_Ahead [5 0 0]
ELSE
IF rov_port_revs_demand = h_ahd
THEN class = NO_KEY [2 27 30]
ELSE
IF rov_speed < 2.33
AND rov_target_range < 134.90
AND rov_stbd_revs_demand = h_ahd
THEN class = Port_Ths_Half_Ahead [18 0 0]
ELSE
IF rov_degrees < 31.50
AND rov_port_revs_demand = stop
THEN class = Port_Ths_Half_Ahead [11 0 0]
ELSE
IF rov_port_revs_demand = stop
AND rov_stbd_revs_demand = h_astn
THEN class = Port_Ths_Half_Ahead [6 0 0]
ELSE
(DEFAULT) class = NO_KEY [147 139 158]
1033 examples!
PREDICTED
ACTUAL Port_Th Stbd_Th NO_KEY Accuracy
Port_Ths 44.00 0.00 150.00 22.7%
Stbd_Ths 0.00 18.00 167.00 9.7%
NO_KEY 0.00 0.00 654.00 100.0%
Overall accuracy: 69.3%
444 examples!
PREDICTED
ACTUAL Port_Th Stbd_Th NO_KEY Accuracy
Port_Ths 7.00 1.00 53.00 11.5%
Stbd_Ths 3.00 1.00 59.00 1.6%
NO_KEY 19.00 4.00 297.00 92.8%
Overall accuracy: 68.7%
The default rule accuracy in these cases would be 654 / 1033 = 63.3% and 320 / 444 = 72.0%. The better relative accuracy of the first set can be easily explained, as that was the training set, i.e., the set of data from which the rules were derived in the first place.
**RULE FILE**
@
Examples: RT2s09a.exs
Algorithm: ORDERED
Error_Estimate: LAPLACIAN
Threshold: 10.00
Star: 10
@
*ORDERED-RULE-LIST*
IF sub_display = ship
THEN class = NO_KEY [0 0 224]
ELSE
IF -10.50 < rov_off_head < 11.00
THEN class = NO_KEY [0 0 55]
ELSE
IF rov_height < 52.30
AND rov_speed > 1.68
AND rov_r < 0.00
AND rov_target_range > 49.60
THEN class = NO_KEY [0 0 29]
ELSE
IF rov_off_head < -30.50
AND rov_height > 4.20
AND rov_speed > 0.09
AND rov_r < 0.01
THEN class = Pure_Turn_Port [0 17 0]
ELSE
IF rov_off_head > 39.50
AND rov_height < 40.20
AND rov_speed < 1.33
AND rov_target_range < 133.35
THEN class = Pure_Turn_Stbd [14 0 0]
ELSE
IF rov_target_range < 6.25
AND rov_av_revs_demand = stop
THEN class = NO_KEY [0 0 7]
ELSE
IF rov_off_head > 15.00
AND 0.02 < rov_speed < 0.34
THEN class = Pure_Turn_Stbd [9 0 0]
ELSE
IF rov_off_head < -12.50
AND rov_r > -0.09
AND rov_target_range > 6.35
THEN class = NO_KEY [0 0 7]
ELSE
(DEFAULT) class = Pure_Turn_Stbd [11 6 9]
388 examples!
PREDICTED
ACTUAL Pure_Tu Pure_Tu NO_KEY Accuracy
Pure_Tur 34.00 0.00 0.00 100.0%
Pure_Tur 6.00 17.00 0.00 73.9%
NO_KEY 14.00 16.00 301.00 90.9%
Overall accuracy: 90.7%
222 examples!
PREDICTED
ACTUAL Pure_Tu Pure_Tu NO_KEY Accuracy
Pure_Tur 5.00 2.00 2.00 55.6%
Pure_Tur 1.00 7.00 4.00 58.3%
NO_KEY 5.00 5.00 191.00 95.0%
Overall accuracy: 91.4%
Again, we can easily calculate the performance of the default rule. In the first case it is 331 / 388 = 85.3% and in the second case (not training data) it is 201 / 222 = 90.5%.
The analysis of the second sea-searching experiment invited an attempt to consider the stage of ROV control in terms of the sub-tasks of control of height, direction, and speed.

Table C.1:ROV visual context, height control, for MT

Table C.2:ROV visual context, direction control, for MT

Table C.3:ROV visual context, speed control, for MT

Table C.4:ROV direction context, height control, for MT

Table C.5:ROV direction context, direction control, for MT

Table C.6:ROV direction context, speed control, for MT

Table C.7:ROV non-graphic context, height control, for MT

Table C.8:ROV non-graphic context, direction control, for MT

Table C.9:ROV non-graphic context, speed control, for MT
This analysis of the separate ROV functions is done here in Tables C.1 to C.9, for the three major ROV contexts of subject MT. Since it is only a comparison with previous figures (in Tables 7.11 to 7.13), only the last two intervals are shown, the others being less reliable and informative. A similar analysis was also done reversing the roles of the 0 and 1 sets. This generally confirms the impressions given by the tables here, and adds little to the argument, except to note that variations of up to 10% in the difference of performance over default seems to be quite common in this collection of data: this may be at least partly due to the sample size, which is not very large for data as noisy and ill-understood as here.
Within the ROV visual context speed control (C.3) and direction control (C.2) appear to be well established. The overall accuracy figures are higher than in the original ROV visual context, but the difference over the default rule does not appear to be a very substantial improvement over the difference in the earlier table. The height control results (C.1) admit the possible explanation that a ruly approach to height control was only gained in the last interval: however there is not enough data to have great confidence in this.
The ROV direction context was so named because the two principle sensors defining this context for subject MT are the heading of the ROV and the bearing of the target. The figures (C.4 to C.6) suggest that rules for direction control are more evident than other rules within this context. None of the rules, however, have impressive accuracy figures. The ROV non-graphic context (C.7 to C.9) appears no less unruly than in the original tables, 7.13 and 7.21.
This analysis offers no firm conclusions.
[1] Ackermann, D. (1986). A pilot study on the effects of individualization in man-computer-interaction. In: Mancini, G., Johannsen, G., and Martensen, L. (eds), Analysis, Design and Evaluation of Man-Machine Systems. Pergamon, Oxford.
[2] a b Alengry, P. (1987). The analysis of knowledge representation of nuclear power plant control room operators. In: Bullinger, H.-J. and Shackel, B. (eds), Human-Computer Interaction—INTERACT '87. North-Holland, Amsterdam.
[3] Alty, J. L., Elzer, P., Holst, O., Johannsen, G., and Savory, S. (1986). Literature and user survey of issues related to man-machine interfaces for supervision and control. Internal Report AMU8603/01S, Scottish HCI Centre, Glasgow.
[4] Amarel, S. (1968). On representation of problems of reasoning about actions. In: Michie, D. (ed.), Machine Intelligence 3, ch 10, pp. 131–171. Edinburgh University Press.
[5] a b c Anderson, J. R. (1983). The Architecture of Cognition. Harvard University Press, Cambridge, MA.
[6] a b c d Bainbridge, L. (1981). Verbal reports as evidence of the process operator's knowledge. In: Mamdani, E. H. and Gaines, B. R. (eds), Fuzzy Reasoning and its Applications, pp. 343–368. Academic Press, London.
[7] Bainbridge, L. (1988). Types of representation. In: Goodstein, L. P., Andersen, H. B., and Olsen, S. E. (eds), Tasks, Errors and Mental Models, ch 4. Taylor & Francis, London.
[8] Ball, W. E. (1982). Mathematical model for simulating MCMV manoeuvring and dynamic positioning. Technical report, Hydrodynamics Department AMTE (Haslar), Haslar, Gosport, Hampshire.
[9] a b c d Barnard, P. J. (1987). Cognitive resources and the learning of human-computer dialogs. In: Carroll, J. M. (ed.), Interfacing Thought: Cognitive Aspects of Human-Computer Interaction, ch 6. MIT Press, Cambridge, MA.
[10] Bartlett, F. C. (1932). Remembering. Cambridge University Press, Cambridge, England.
[11] a b Bellotti, V. (1988). Implications of current design practice for the use of HCI techniques. In: Jones, D. M. and Winder, R. (eds), People and Computers IV. Cambridge University Press, Cambridge, England.
[12] a b Bennett, J. L., Lorch, D. J., Kieras, D. E., and Polson, P. G. (1987). Developing a user interface technology for use in industry. In: Bullinger, H.-J. and Shackel, B. (eds), Human-Computer Interaction—INTERACT '87. North-Holland, Amsterdam.
[13] a b Benyon, D. (1987). User models. what's the purpose? In: Cooper, M. and Dodson, D. (eds), Proceedings of the Second Intelligent Interfaces Meeting, London. IEE for the Alvey Directorate.
[14] a b Bignell, V. and Fortune, J. (1984). Understanding Systems Failures. Manchester University Press, Manchester.
[15] a b Blackwell, G. K., Colley, B. A., and Stockel, C. T. (1988). A real-time intelligent system for maritime collision avoidance. In: Gero, S. (ed.), Artificial Intelligence in Engineering: Diagnosis and Learning, pp. 119–138. Elsevier, Amsterdam.
[16] a b c Booth, P. A. (1991). Modelling the user: User-system errors and predictive grammars. In: Weir, G. R. S. and Alty, J. L. (eds), Human-Computer Interaction and Complex Systems, ch 5. Academic Press, London.
[17] Bratko, I. (1989). Pole balancing: A study in qualitative reasoning about control. In: 4th ISSEK Scientific Workshop, pp. 27–44, Udine, Italy.
[18] Brewer, W. F. (1987). Schemas versus mental models in human memory. In: Morris, P. (ed.), Modelling Cognition. John Wiley, Chichester.
[19] a b Cahill, R. A. (1983). Collisions and their Causes. Fairplay Publications, London.
[20] a b c d e f g h i Card, S. K., Moran, T. P., and Newell, A. (1983). The Psychology of Human-Computer Interaction. Lawrence Erlbaum Associates, Hillsdale, NJ.
[21] a b c Carroll, J. M. (1984). Mental models and software human factors: An overview. Technical Report RC 10616 (47016), IBM Watson Research Centre, Yorktown Heights, NY.
[22] Chambers, R. A. and Michie, D. (1969). Man-machine co-operation on a learning task. In: Parslow, R., Prowse, R., and Graan, R. E. (eds), Computer Graphics: Techniques and Applications, pp. 179–186. Plenum Publishing, London.
[23] a b Clark, P. and Niblett, T. (1989). The CN2 induction algorithm. Machine Learning, 3(4): 261–283.
[24] Clocksin, W. F. and Morgan, A. J. (1986). Qualitative control. In: Proceedings of European Conference on Artificial Intelligence, Brighton.
[25] Cockcroft, A. N. (1972). A manoeuvring diagram for avoiding collisions at sea. Journal of Navigation, 25(1): 105–107.
[26] Coenen, F. P., Smeaton, G. P., and Bole, A. G. (1989). Knowledge-based collision avoidance. Journal of Navigation, 42(1): 107–116.
[27] Colley, B. A., Curtis, R. G., and Stockel, C. T. (1983). Manoeuvring times, domains and arenas. Journal of Navigation, 36(2): 324–328.
[28] Colley, B. A., Curtis, R. G., and Stockel, C. T. (1984). A marine traffic flow and collision avoidance computer simulation. Journal of Navigation, 37(2): 232–250.
[29] Curtis, R. G. (1978). Determination of mariners' reaction times. Journal of Navigation, 31(3): 408–417.
[30] a b Curtis, R. G., Goodwin, E. M., and Konyn, M. (1987). The automatic detection of real-life ship encounters. Journal of Navigation, 40(3): 355–365.
[31] Donaldson, P. E. K. (1960). Error decorrelation: A technique for matching a class of functions. In: Proceedings of the Third International Conference on Medical Electronics, pp. 173–178.
[32] Duncan, K. D. (1987). Fault diagnosis training for advanced continuous process installations. In: Rasmussen, J., Duncan, K., and Leplat, J. (eds), New Technology and Human Error. John Wiley & Sons, Chichester.
[33] Duncan, K. D. and Prætorius, N. (1987). Knowledge capture for fault diagnosis training. Advances in Man-Machine Systems Research, 3.
[34] a b Eastwood, E. (1968). Control theory and the engineer. Proceedings IEE, 115(1): 203–211.
[35] Fagan, L. M., Kunz, J. C., Feigenbaum, E. A., and Osborn, J. J. (1979). Representation of dynamic clinical knowledge: Measurement interpretation in the intensive care unit. In: IJCAI-79, pp. 260–262, Tokyo.
[36] Ferranti plc, Strathclyde University, and YARD Ltd (1985). Identification of applied MMI research to aid real-time decision-making. Report ALV/PRJ/MMI/004 and 031, YARD Report No. 3068, YARD Ltd., Glasgow.
[37] a b Forbus, K. D. (1983). Qualitative reasoning about space and motion. In: Gentner, D. and Stevens, A. L. (eds), Mental Models, ch 4. Lawrence Erlbaum Associates, Hillsdale, NJ.
[38] Forbus, K. D. (1984). Qualitative process theory. Artificial Intelligence, 24: 85–168.
[39] Gams, M. and Lavrac, N. (1987). Review of five empirical learning systems within a proposed schemata. In: Bratko, I. and Lavrac, N. (eds), Progress in Machine Learning: Proceedings of EWSL-87, Bled, Yugoslavia, pp. 46–66, Wilmslow. Sigma Press.
[40] Gentner, D. and Stevens, A. L. (eds) (1983). Mental Models. Lawrence Erlbaum Associates, Hillsdale, NJ.
[41] a b Gilhooly, K. J. (ed.) (1989). Human and Machine Problem Solving. Plenum Press, New York.
[42] Ginsberg, M. L. (ed.) (1987). Readings in Nonmonotonic Reasoning. Morgan Kaufmann, Los Altos, CA.
[43] a b Grant, A. S. and Mayes, J. T. (1991). Cognitive task analysis? In: Weir, G. R. S. and Alty, J. L. (eds), Human-Computer Interaction and Complex Systems, ch 6. Academic Press, London.
[44] Green, M. (1985). Report on dialogue specification tools. In: Pfaff, G. E. (ed.), User Interface Management Systems: Proc. Workshop on UIMS, Seeheim, FRG, November, 1983. Springer-Verlag, Berlin.
[45] a b c d Green, T. R. G., Schiele, F., and Payne, S. J. (1988). Formalisable models of user knowledge in human-computer interaction. In: van der Veer, G. C., Green, T. R. G., Hoc, J.-M., and Murray, D. M. (eds), Working with Computers: Theory versus Outcome, pp. 3–46. Academic Press, London.
[46] Greenstein, J. S., Arnaut, L. Y., and Revesman, M. E. (1986). An empirical comparison of model-based and explicit communication for dynamic human-computer task allocation. Int. J. Man-Machine Studies, 24: 355–363.
[47] Grudin, J. (1989). The case against user interface consistency. Communications of the ACM, 32(10): 1164–1173.
[48] a b Habberley, J. S. (1988). Personal communication.
[49] Habberley, J. S., Shaddick, C. A., and Taylor, D. H. (1986). A behavioural study of the collision avoidance task in bridge watchkeeping. Technical report, College of Maritime Studies, Warsash, Hampshire.
[50] a b Halasz, F. and Moran, T. (1982). Analogy considered harmful. In: Human Factors in Computer Systems: Proceedings of CHI'82, Gaithersburg, MD. ACM/SIGCHI.
[51] a b Hammond, N., Jørgensen, A., MacLean, A., Barnard, P., and Long, J. (1983). Design practice and interface usability: Evidence from interviews with designers. In: CHI '83: Human Factors in Computing Systems, pp. 40–44, Boston. ACM.
[52] Hesse, H. (1943). The Glass Bead Game (Das Glasperlenspiel). Penguin (1972), Harmondsworth.
[53] Hoc, J.-M. (1989). Cognitive approaches to process control. In: Tiberghien, G. (ed.), Advances in Cognitive Science Vol. 2: Theory and Applications, ch 9, pp. 178–202. Ellis Horwood, Chichester.
[54] Hofstadter, D. R. (1979). Gödel, Escher, Bach: an Eternal Golden Braid. Penguin (1980), Harmondsworth.
[55] Hollan, J. D., Hutchins, E. L., and Weitzman, L. (1984). STEAMER: An interactive inspectable simulation-based training system. The AI Magazine, 5(2): 15–27.
[56] a b c Holland, J. H., Holyoak, K. J., Nisbett, R. E., and Thagard, P. R. (1986). Induction: Processes of Inference, Learning, and Discovery. MIT Press, Cambridge, MA.
[57] a b Hollnagel, E. (1988). Man-machine interaction and decision support systems: User modeling and dialogue specification. In: IAEA Technical Committee Meeting on ‘User Requirements for Decision Support Systems’, Vienna.
[58] Hollnagel, E. (1988). Mental models and model mentality. In: Goodstein, L. P., Andersen, H. B., and Olsen, S. E. (eds), Tasks, Errors and Mental Models, ch 17. Taylor & Francis, London.
[59] Hollnagel, E. and Woods, D. D. (1983). Cognitive systems engineering: New wine in new bottles. Int. J. Man-Machine Studies, 18: 583–600.
[60] Hutchins, E. (1987). Learning to navigate in context. In: Workshop on Context, Cognition and Activity, Stenungsund, Sweden. Draft manuscript.
[61] a b International Maritime Organisation (1983). The international regulations for preventing collisions at sea.
[62] Isenberg, D. J. (1985). Some hows and whats of managerial thinking: Implications for future army leaders. In: Hunt, J. G. and Blair, J. D. (eds), Leadership on the Future Battlefield. Pergamon-Brassey's International Defense Publishers, Washington.
[63] Jaffe, L. (1981). Technical aspects and chronology of the Three Mile Island accident. In: Moss, T. H. and Sills, D. L. (eds), The Three Mile Island Nuclear Accident: Lessons and Implications, pp. 37–47, New York. New York Academy of Sciences.
[64] Johnson-Laird, P. N. (1983). Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Cambridge University Press, Cambridge, England.
[65] Keane, M. and Brayshaw, M. (1988). The incremental analogy machine: A computational model of analogy. In: Proceedings of the Third European Working Session on Learning, Glasgow. Pitman.
[66] a b c d Kieras, D. and Polson, P. G. (1985). An approach to the formal analysis of user complexity. Int. J. Man-Machine Studies, 22: 365–394.
[67] a b Kieras, D. E. and Bovair, S. (1984). The role of a mental model in learning to operate a device. Cognitive Science, 8: 255–273.
[68] Korf, R. E. (1980). Toward a model of representation changes. Artificial Intelligence, 14: 41–78.
[69] Kuipers, B. (1984). Commonsense reasoning about causality: Deriving behavior from structure. Artificial Intelligence, 24: 169–203.
[70] a b Kuipers, B. (1986). Qualitative simulation. Artificial Intelligence, 29 (3): 289–338.
[71] Kuipers, B. (1987). New reasoning methods for artificial intelligence in medicine. Int. J. Man-Machine Studies, 26 (6): 707–718.
[72] a b Laird, J. E., Newell, A., and Rosenbloom, P. S. (1987). SOAR: An architecture for general intelligence. Artificial Intelligence, 33: 1–64.
[73] Lindgaard, G. (1988). Should systems designers need to bother with the notion of mental models? In: Ergonomics International 88, Sydney, Australia, pp. 630–632. Taylor & Francis, London.
[74] Mackey, A. M. (1985). A simple algorithm for the fast three-dimensional digital simulation of the motion of a cable in water. Technical Report WLTM 539/85, A. R. E., Portland.
[75] a b Makarovic, A. (1988). A qualitative way of solving the pole balancing problem. Memorandum inf-88-44, University of Twente, Enschede, The Netherlands.
[76] Marshall, E. C., Duncan, K. D., and Baker, S. M. (1981). The role of withheld information in the training of process plant fault diagnosis. Ergonomics, 24(9): 711–724.
[77] a b Michalski, R. S. and Chilausky, R. L. (1981). Knowledge acquisition by encoding expert rules versus computer induction from examples: A case study involving soybean pathology. In: Mamdani, E. H. and Gaines, B. R. (eds), Fuzzy Reasoning and its Applications, pp. 247–271. Academic Press, London.
[78] Michie, D. (ed.) (1982). Introductory Readings in Expert Systems. Gordon & Breach, New York.
[79] a b Michie, D., Bain, M., and Hayes-Michie, J. (1990). Cognitive models from subcognitive skills. In: McGhee, J., Grimble, M. J., and Mowforth, P. (eds), Knowledge-Based Systems for Industrial Control, pp. 71–99. Peter Peregrinus, London.
[80] Michie, D. and Chambers, R. A. (1968). BOXES: An experiment in adaptive control. In: Dale, E. and Michie, D. (eds), Machine Intelligence 2, ch 9. Oliver & Boyd, Edinburgh.
[81] a b Michie, D. and Johnston, R. (1984). The Creative Computer: Machine Intelligence and Human Knowledge. Viking, Harmondsworth.
[82] Minsky, M. (1975). A framework for representing knowledge. In: Winston, P. H. (ed.), The Psychology of Computer Vision. McGraw-Hill, New York.
[83] a b c d Moran, T. P. (1981). The Command Language Grammar: A representation for the user interface of interactive computer systems. Int. J. Man-Machine Studies, 15: 3–50.
[84] Moray, N. (1986). Operator models in process control. In: IEEE International Conference on Systems, Man and Cybernetics, Atlanta, Georgia.
[85] a b Moray, N. (1987). Intelligent aids, mental models, and the theory of machines. Int. J. Man-Machine Studies, 27: 619–629.
[86] a b Muggleton, S. (1988). A strategy for constructing new predicates in first order logic. In: Proceedings of the Third European Working Session on Learning, Glasgow. Pitman.
[87] a b Muggleton, S. (1990). Inductive Acquisition of Expert Knowledge. Turing Institute Press and Addison-Wesley, Wokingham, England.
[88] a b Murray, D. M. (1987). Embedded user models. In: Bullinger, H.-J. and Shackel, B. (eds), Human-Computer Interaction—INTERACT '87. North-Holland, Amsterdam.
[89] Murray, D. M. (1988). A survey of user cognitive modelling. Report DITC 92/87, National Physical Laboratory, Teddington, Middlesex.
[90] Nagel, E. (ed.) (1950). John Stuart Mill's Philosophy of Scientific Methods. Hafner, New York.
[91] a b c d e Newell, A. and Simon, H. A. (1972). Human Problem Solving. Prentice-Hall, Englewood Cliffs, NJ.
[92] NMI Ltd. (1985). The investigation of the hydrodynamics of a remotely operated vehicle. Technical Report OT/N/84124, Offshore Supplies Office, Dept. of Energy. NMI Project 252010.
[93] Nordgren, R. P. (1974). On the computation of the motion of elastic rods. Journal of Applied Mechanics, (September): 777–780.
[94] a b Norman, D. A. (1983). Some observations on mental models. In: Gentner, D. and Stevens, A. L. (eds), Mental Models, ch 1. Lawrence Erlbaum Associates, Hillsdale, NJ.
[95] Olsen, S. E. (1987). CATOOL: A computer-based tool for investigations of categorical information in mental models. In: Bullinger, H.-J. and Shackel, B. (eds), Human-Computer Interaction—INTERACT '87. North-Holland, Amsterdam.
[96] a b c d e f Payne, S. J. and Green, T. R. G. (1986). Task-action grammars: A model of the mental representation of task languages. Human-Computer Interaction, 2: 93–133.
[97] Pearce, D. A. (1988). The induction of fault diagnosis systems from qualitative models. Research Memo TIRM-88-029, The Turing Institute, Glasgow.
[98] a b Pheasant, S. (1988). The Zeebrugge-Harrisburg syndrome. New Scientist, 21 January: 55–58.
[99] Phillips, M. D., Bashinski, H. S., Ammerman, H. L., and Fligg, Jr., C. M. (1988). A task analytic approach to dialogue design. In: Helander, M. (ed.), Handbook of Human-Computer Interaction, pp. 835–857. North-Holland, Amsterdam.
[100] a b c d Rasmussen, J. (1980). The human as a systems component. In: Smith, H. T. and Green, T. R. G. (eds), Human Interaction with Computers. Academic Press, London.
[101] a b c d e f g h Rasmussen, J. (1983). Skills, rules, and knowledge; signals, signs, and symbols, and other distinctions in human performance models. IEEE Transactions on Systems, Man and Cybernetics, SMC-13: 257–266.
[102] Rasmussen, J. (1986). Information Processing and Human-Machine Interaction: An Approach to Cognitive Engineering. North-Holland, New York.
[103] Rasmussen, J. (1987). Modelling action in complex environments. Report Risø-M-2684, Risø National Laboratory, DK-4000 Roskilde, Denmark.
[104] Rasmussen, J., Duncan, K., and Leplat, J. (eds) (1987). New Technology and Human Error. John Wiley & Sons, Chichester.
[105] Reason, J. (1986). Recurrent errors in process environments: Some implications for the design of intelligent decision support systems. In: Hollnagel, E., Mancini, G., and Woods, D. D. (eds), Intelligent Decision Support in Process Environments. Springer-Verlag, Berlin.
[106] Reason, J. (1988). Framework models of human performance and error. In: Goodstein, L. P., Andersen, H. B., and Olsen, S. E. (eds), Tasks, Errors and Mental Models, ch 2. Taylor & Francis, London.
[107] Reason, J. (1990). Human Error. Cambridge University Press, Cambridge, England.
[108] a b c Reisner, P. (1981). Formal grammar and human factors design of an interactive graphics system. IEEE Transactions on Software Engineering, SE-7(2): 229–240.
[109] a b c Reisner, P. (1990). What is inconsistency? In: Diaper, D., Gilmore, D., Cockton, G., and Shackel, B. (eds), Human-Computer Interaction—INTERACT '90, pp. 175–181. North-Holland, Amsterdam.
[110] Rich, E. (1986). Users are individuals: Individualizing user models. In: Davies, R. (ed.), Intelligent Information Systems: Progress and Prospects. Horwood, Chichester.
[111] Riek, J. R. (1978). Collision avoidance behaviour and uncertainty. Journal of Navigation, 31(1): 82–92.
[112] Rips, L. J. (1986). Mental muddles. In: Brand, M. and Harnish, R. M. (eds), The Representation of Knowledge and Belief. University of Arizona Press, Tucson, AZ.
[113] Rivers, R. (1990). The role of games and cognitive models in the understanding of complex dynamic systems. In: Diaper, D., Gilmore, D., Cockton, G., and Shackel, B. (eds), Human-Computer Interaction—INTERACT '90, pp. 87–92. North-Holland, Amsterdam.
[114] Roth, E. M. and Woods, D. D. (1989). Cognitive task analysis: An approach to knowledge acquisition for intelligent system design. In: Guida, G. and Tasso, C. (eds), Topics in Expert System Design: Methodologies and Tools, pp. 233–264. Elsevier, Amsterdam.
[115] a b Rouse, W. B. (1981). Human-computer interaction in the control of dynamic systems. ACM Computing Surveys, 13 (1): 71–99.
[116] Royal Institute of Navigation (1972). The proposed revision of the collision regulations: A discussion. Journal of Navigation, 25(4): 427–443.
[117] Runciman, C. and Hammond, N. (1986). User programs: A way to match computer systems and human cognition. In: Harrison, M. D. and Monk, A. F. (eds), People and Computers: Designing for Usability. Cambridge University Press, Cambridge, England.
[118] Sammut, C. (1988). Experimental results from an evaluation of algorithms that learn to control dynamic systems. In: Laird, J. (ed.), Proceedings of the Fifth International Conference on Machine Learning, pp. 437–443. Morgan Kaufmann, San Mateo, CA.
[119] Schank, R. C. and Abelson, R. (1977). Scripts, Plans, Goals and Understanding. Lawrence Erlbaum Associates, Hillsdale, NJ.
[120] a b Schiele, F. and Hoppe, H. U. (1990). Inferring task structures from interaction protocols. In: Diaper, D., Gilmore, D., Cockton, G., and Shackel, B. (eds), Human-Computer Interaction—INTERACT '90, pp. 567–572. North-Holland, Amsterdam.
[121] Schlimmer, J. C. (1987). Incremental adjustment of representations for learning. In: Proceedings of the Fourth International Workshop on Machine Learning, pp. 79–90, Irvine, CA.
[122] a b Sharratt, B. D. (1987a). The incorporation of early evaluation in Command Language Grammar specifications. Internal Report AMU8715/01H, Scottish HCI Centre, Edinburgh.
[123] a b Sharratt, B. D. (1987b). Top-down interactive systems design: Some lessons learnt from using Command Language Grammar. In: Bullinger, H.-J. and Shackel, B. (eds), Human-Computer Interaction—INTERACT '87. North-Holland, Amsterdam.
[124] a b Shaw, M. L. G. and Gaines, B. R. (1987). An interactive knowledge-elicitation technique using personal construct technology. In: Kidd, A. L. (ed.), Knowledge Acquisition for Expert Systems: A Practical Handbook, ch 6. Plenum Press, New York.
[125] a b Sheridan, T. B. and Hennessy, R. T. (1984). Research and modeling of supervisory control behavior. Workshop report, Committee on Human Factors, National Research Council, 2101 Constitution Avenue, Washington, D.C.
[126] Shneiderman, B. (1987). Designing the User Interface: Strategies for Effective Human-Computer Interaction. Addison-Wesley, Reading, MA.
[127] a b c Simon, T. (1988). Analysing the scope of cognitive models in human-computer interaction: A trade-off approach. In: Jones, D. M. and Winder, R. (eds), People and Computers IV, pp. 79–93. Cambridge University Press, Cambridge, England.
[128] Sleeman, D. and Brown, J. S. (eds) (1982). Intelligent Tutoring Systems. Academic Press, London.
[129] a b Smeaton, G. P., Bole, A. G., and Coenen, F. P. (1988). A rule based system for collision avoidance. In: Maritime Communications and Control. Marine Management (Holdings).
[130] Smiley, A. and Michon, J. A. (1989). Conceptual framework for Generic Intelligent Driver Support. DRIVE project report, Traffic Research Centre, University of Groningen.
[131] Smith, S. M. and Mosier, J. N. (1984). The user interface to computer-based information systems: A survey of current software design practice. In: Shackel, B. (ed.), Human-Computer Interaction—INTERACT '84. North-Holland, Amsterdam.
[132] Stassen, H. G., Johannsen, G., and Moray, N. (1988). Internal representation, internal model, human performance model and mental workload. In: Man-Machine Systems: Analysis, Design and Evaluation. IFAC/ IFIP/ IEA/ IFORS Conference, Oulu, Finland.
[133] a b Streitz, N. A. (1986). Cognitive ergonomics: An approach for the design of user-oriented interactive systems. In: Klix, F. and Wandke, H. (eds), MACINTER I. North-Holland, Amsterdam.
[134] a b Suchman, L. A. (1987). Plans and Situated Actions: The Problem of Human-Machine Communication. Cambridge University Press, Cambridge, England.
[135] Sutcliffe, A. (1989). Task analysis, systems analysis and design: Symbiosis or synthesis? Interacting with Computers, 1 (1): 6–12.
[136] a b c Sutton, R. and Towill, D. R. (1988). Modelling the helmsman in a ship steering system using fuzzy sets. In: Man-Machine Systems: Analysis, Design and Evaluation. IFAC/ IFIP/ IEA/ IFORS Conference, pp. 366–371, Oulu, Finland.
[137] Utgoff, P. E. (1986). Shift of bias for inductive concept learning. In: Michalski, R. S., Carbonell, J. G., and Mitchell, T. M. (eds), Machine Learning: An Artificial Intelligence Approach, Volume II. Morgan Kaufmann, Los Altos, CA.
[138] a b Wahlström, B. (1988). On the use of models in human decision making. In: Goodstein, L. P., Andersen, H. B., and Olsen, S. E. (eds), Tasks, Errors and Mental Models, ch 10. Taylor & Francis, London.
[139] a b Wewerinke, P. H. and van der Tak, C. (1988). Model of the human observer and controller of a dynamic system. In: Man-Machine Systems: Analysis, Design and Evaluation. IFAC/ IFIP/ IEA/ IFORS Conference, pp. 372–377, Oulu, Finland.
[140] a b c Whitefield, A. (1987). Models in human computer interaction: A classification with special reference to their uses in design. In: Bullinger, H.-J. and Shackel, B. (eds), Human-Computer Interaction—INTERACT '87. North-Holland, Amsterdam.
[141] Widrow, B. and Smith, F. W. (1964). Pattern-recognizing control systems. In: Tou, J. T. and Wilcox, R. H. (eds), Computer and Information Sciences, ch 12, pp. 288–317. Clever Hume Press.
[142] Wilson, M. D., Barnard, P. J., Green, T. R. G., and Maclean, A. (1988). Knowledge-based task analysis for human-computer systems. In: van der Veer, G. C., Green, T. R. G., Hoc, J.-M., and Murray, D. M. (eds), Working with Computers: Theory versus Outcome. Academic Press, London.
[143] Wirstad, J. (1988). On knowledge structures for process operators. In: Goodstein, L. P., Andersen, H. B., and Olsen, S. E. (eds), Tasks, Errors and Mental Models, ch 3. Taylor & Francis, London.
[144] Woods, D. D. (1987). Commentary: Cognitive engineering in complex and dynamic worlds. Int. J. Man-Machine Studies, 27 (5-6): 571–585.
[145] a b c d Woods, D. D. (1988). Coping with complexity: The psychology of human behavior in complex systems. In: Goodstein, L. P., Andersen, H. B., and Olsen, S. E. (eds), Tasks, Errors and Mental Models, pp. 128–148. Taylor & Francis, London.
[146] a b Woods, D. D. (1991). The cognitive engineering of problem representations. In: Weir, G. R. S. and Alty, J. L. (eds), Human-Computer Interaction and Complex Systems, ch 7. Academic Press, London.
[147] Woods, D. D. and Hollnagel, E. (1987). Mapping cognitive demands in complex problem-solving worlds. Int. J. Man-Machine Studies, 26 (2): 257–275.
[148] a b c d e Woods, D. D. and Roth, E. M. (1986). Models of cognitive behavior in nuclear power plant personnel: A feasibility study. Technical Report NUREG/CR-4532, U.S. Nuclear Regulatory Division, Washington, D.C.
[149] Wrobel, S. (1988). Automatic representation adjustment in an observational discovery system. In: Sleeman, D. (ed.), Proceedings of the Third European Working Session on Learning, pp. 253–262. Pitman, London.
[150] a b c Young, R. M. (1983). Surrogates and mappings: Two kinds of conceptual models for interactive devices. In: Gentner, D. and Stevens, A. L. (eds), Mental Models, ch 3. Lawrence Erlbaum Associates, Hillsdale, NJ.
[151] a b c Young, R. M., Green, T. R. G., and Simon, T. (1989). Programmable user models for predictive evaluation of interface designs. In: CHI '89 Conference Proceedings, pp. 15–19, Austin, Texas.
[152] Young, R. M. and Simon, T. (1987). Planning in the context of human-computer interaction. In: Diaper, D. and Winder, R. (eds), People and Computers III, pp. 363–370. Cambridge University Press, Cambridge, England.
[153] a b c Zimolong, B., Nof, S. Y., Eberts, R. E., and Salvendy, G. (1987). On the limits of expert systems and engineering models in process control. Behaviour and Information Technology, 6 (1): 15–36.
[154] Zrimec, T. (1990). Towards Autonomous Learning of Behavior by a Robot. PhD thesis, University of Ljubljana.